

这是一个创建于 2925 天前的主题,其中的信息可能已经有所发展或是发生改变。
这里举个例子,某磁力离线云,对数据标题进行加密。
前端展示是这样的:  源码是这样的:
源码是这样的:  就是一堆数字
就是一堆数字
522976135611868623145167941594123212189691661622940143851845123085156721864746812335615973169122328617506173882280118479173282298017397151584601650046178434976512095105584660684511447105961183710149114224680500648924940550746597285683455685036489180044610881150575437528046276548659667614694677972708309453756195658509070188823469410901107201184
解密方式是这样的: 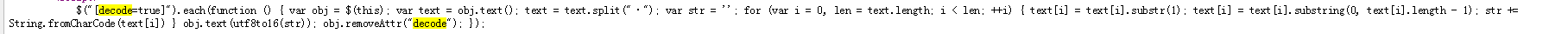
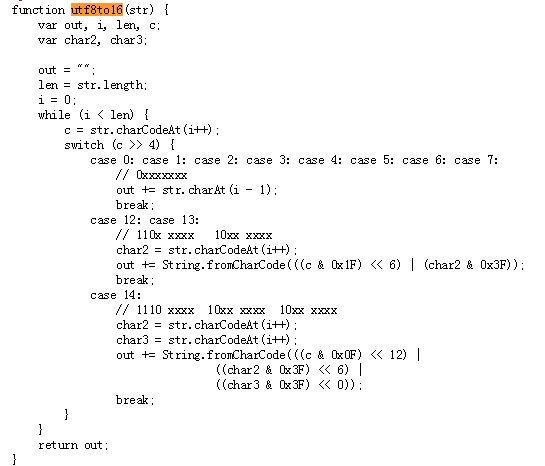
$("[decode=true]").each(function () { var obj = $(this); var text = obj.text(); text = text.split(""); var str = ''; for (var i = 0, len = text.length; i < len; ++i) { text[i] = text[i].substr(1); text[i] = text[i].substring(0, text[i].length - 1); str += String.fromCharCode(text[i]) } obj.text(utf8to16(str)); obj.removeAttr("decode"); }); function utf8to16(str) { var out, i, len, c; var char2, char3; out = ""; len = str.length; i = 0; while (i < len) { c = str.charCodeAt(i++); switch (c >> 4) { case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7: // 0xxxxxxx out += str.charAt(i - 1); break; case 12: case 13: // 110x xxxx 10xx xxxx char2 = str.charCodeAt(i++); out += String.fromCharCode(((c & 0x1F) << 6) | (char2 & 0x3F)); break; case 14: // 1110 xxxx 10xx xxxx 10xx xxxx char2 = str.charCodeAt(i++); char3 = str.charCodeAt(i++); out += String.fromCharCode(((c & 0x0F) << 12) | ((char2 & 0x3F) << 6) | ((char3 & 0x3F) << 0)); break; } } return out; } 原本想要用 python 重写这个解密过程,但是发现挺麻烦的,基于“反正都是在网页上展示内容”,干脆将他的解密 js 搬过来照用。。
第 1 条附言 2017-10-09 16:27:06 +08:00
亲测,浏览器可以运行,python用execjs调用返回空值,不然我直接解析结果了。
浏览器运行
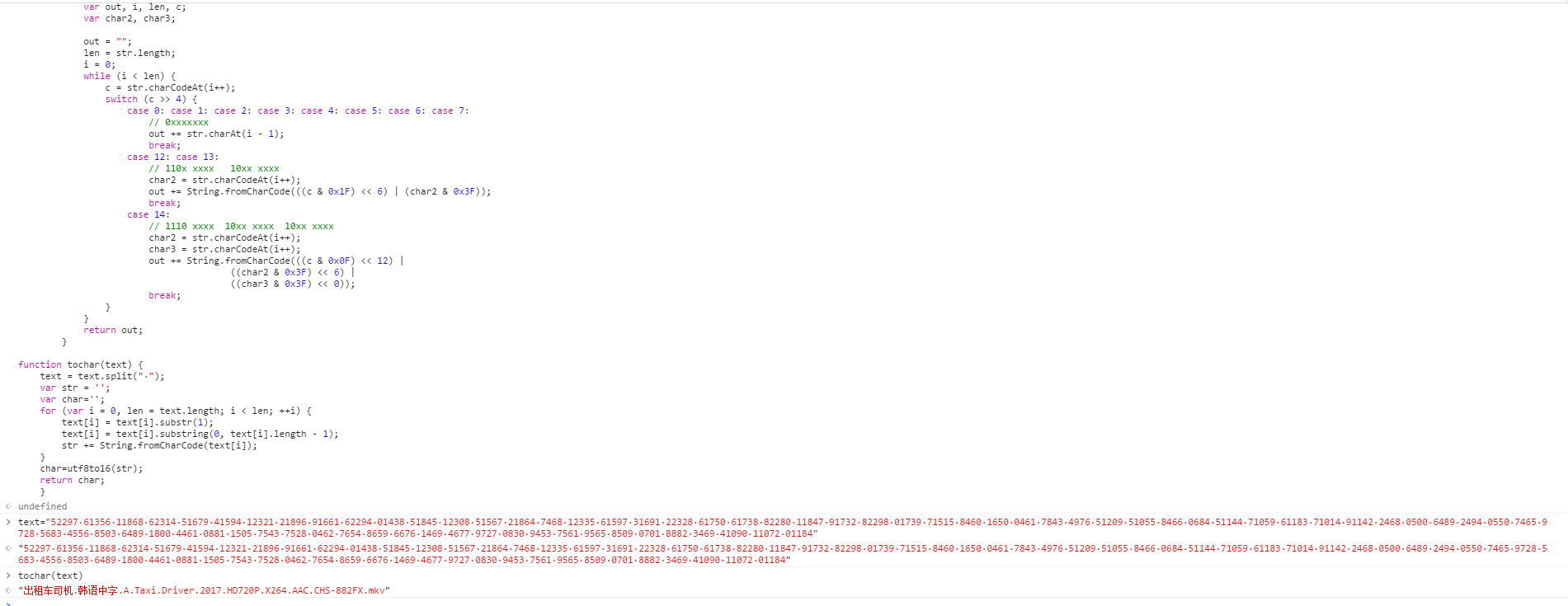
python使用execjs

或许脚本有错。发出来大家指正一下
https://gist.github.com/anonymous/420c233004e1dbfbd98fe543a2d3ad15
第 2 条附言 2017-10-09 17:32:33 +08:00
原来如此简单:
def tochar(text): text= text.split("") str_='' for idx,num in enumerate(text): num=num[1:-1] str_+=chr(int(num)) return str_ 第 3 条附言 2017-10-09 18:03:59 +08:00
这个所谓的解密就是,将以分隔的每串数字,去头去尾,取中间的数字,然后用 chr()函数将数字转为字符,最后把字符拼接起来。。。
 | 1 jas0ndyq 2017-10-09 15:39:41 +08:00 也做过和 lz 一样的事情 |
 | 2 bearsiji 2017-10-09 15:40:28 +08:00 类似这种的 多重混淆 一层套一层 酸爽 |
 | 3 PythoneerDev6 2017-10-09 15:49:14 +08:00 之前爬过 汤不热。 源代码放在 github 上,sta 达到 2k 之后。 汤不热就开始做反扒。 给 next 的标签加了一个空格。 也是雷到我了。 https://github.com/xiyouMc/WebHubBot |
 | 4 jijiwaiwai 2017-10-09 15:49:17 +08:00 你这个办法很笨的。。。 直接使用 pyv8,调用 js 函数获取返回值就行了 |
 | 5 jko123 OP @jijiwaiwai #4 试过了,会出错 |
 | 6 mansur 2017-10-09 15:56:29 +08:00 最厉害的是投毒,缠假内容 |
 | 7 af463419014 2017-10-09 15:58:27 +08:00 后台检测到肯定是爬虫的时候,不禁止访问,装作正常的页面,返回错误的数据 |
 | 8 crab 2017-10-09 15:58:31 +08:00 这种算好了,直接拿它 js 解密。 最厉害的应该是发现你是爬虫,不拒绝你,继续让你爬,但给脏数据。 |
 | 9 xujialiang 2017-10-09 15:58:38 +08:00 哈哈哈 我会用 node 写一个接口,然后调接口 |
 | 10 clino 2017-10-09 15:59:04 +08:00 以前不是有看过变成竖排文的办法,不知道效果如何 |
 | 11 nikoo 2017-10-09 16:03:26 +08:00 怎么把汉字转为楼主贴的这种数字? |
 | 12 kbdancer 2017-10-09 16:13:00 +08:00 via Android phantomJS 直接解析执行 js 或者自定义执行 js 脚本 |
 | 13 x8 2017-10-09 16:29:49 +08:00 根本不知道怎么触发的反爬机制,返回一些错误数据混在正确数据里 |
 | 14 Luckyray 2017-10-09 16:31:33 +08:00 这种乱七八糟的就直接用 chrome driver 了...重写一遍还不够麻烦的 |
 | 15 murmur 2017-10-09 16:32:51 +08:00 能被你发现的都是小 case 真正发现不了的都是用投毒的 |
 | 16 ytmsdy 2017-10-09 16:35:34 +08:00 最惨的就是掉进蜜罐里面,爬虫一切正常,但是返回的数据都是假数据。 最可怕的就是掉进去了,你还不知道!!还在那里很开心的爬,等爬完了,看到结果就 SB 了。 |
 | 17 luoshuangfw 2017-10-09 16:46:49 +08:00 via Android 楼主你看这函数名不是很明确吗,这就是把变长编码的 utf8 转换成定长编码的 utf16 的非常标准的做法啊,我觉得压根不是在加解密 |
 | 18 Xrong 2017-10-09 16:49:47 +08:00 有见过免费代理 IP 池网站,IP 最后一段是用 CSS 展示出来的。。。 |
 | 19 zbl430 2017-10-09 16:52:02 +08:00 |
 | 20 anoymoux 2017-10-09 16:56:09 +08:00 <ul> <li>A</li> <li>B</li> <li>C</li> <li>X</li> ... ... </ul> 你需要的数据是 X,但是他会生成很多的垃圾数据 A,B,C 等等..X 出现的位置是随机的,而且 A,B,C 等垃圾数据的格式跟 X 相同,无法用正则区分. 然后每个 li 都有一个随机的 class 属性,用动态生成的 css 样式控制只显示 X,其他的隐藏掉.... 另外 css 用了继承,嵌套还有复杂的计算等等 |
 | 21 annielong 2017-10-09 16:57:32 +08:00 汤不热还是使用 api 抓取比较好, |
 | 22 vtwoextb 2017-10-09 17:02:33 +08:00 京东防爬, 我用的是 动态 ip 策略 https://github.com/hizdm/dynamic_ip |

 | 24 CareiOS 2017-10-09 17:19:37 +08:00 @PythoneerDev6 你源码,现在还工作吗? |
| 25 jko123 OP @luoshuangfw #17 所以 utf8 怎么转 utf16 ? https://i.loli.net/2017/10/09/59db406626aa1.png |
 | 26 catfish 2017-10-09 17:30:57 +08:00 给假数据 |

 | 29 PythonAnswer 2017-10-09 17:54:11 +08:00 via Android 蜜罐,文字嵌图 |
 | 30 abcbuzhiming 2017-10-09 18:24:40 +08:00 其实我觉得再牛逼的反爬都对付不了真浏览器,所以我觉得无头浏览器才是未来主流技术 |
 | 31 jadec0der 2017-10-09 18:27:51 +08:00 via Android 携程还是去哪儿,价格数字用一种随机字体,比如 7 在这个字体里可能是 4 |
 | 32 yu099 2017-10-09 18:49:16 +08:00 via Android @abcbuzhiming 我看到有加挖矿 JS 的做反爬,如果像淘宝一样屏蔽跟踪 JS 就触反爬怎么办? |
 | 33 NsLib 2017-10-09 19:26:09 +08:00 前去哪儿员工,你可以试试爬爬看,假数据、前端混淆、字体混淆,23333 …… |
 | 34 airbasic 2017-10-09 19:39:59 +08:00 猫眼的票房=。= 得用图像识别 |
 | 35 j3n5en 2017-10-09 19:43:01 +08:00 via Android 啧,这不是黑科云么,。。。,我前两天刚写完。。。。 |
| 37 abcbuzhiming 2017-10-09 20:04:43 +08:00 @yu099 它一定要探测你也是没办法的,所以爬虫这玩意就是比拼服务器,你服务器众多,伪装的像正常浏览器,它就没招了是不是 |
 | 40 scriptB0y 2017-10-09 20:15:50 +08:00 碰到过一个页码记录在 session 中的,也就是你每次发一样的 curl,结果是不一样的…… session 是通过一个 cookie 判断的……不知道算不算反爬 另外记录了一些遇到过的垃圾网站: https://www.kawabangga.com/posts/2017 https://www.kawabangga.com/posts/2240 |
| 41 PythoneerDev6 2017-10-09 20:19:24 +08:00 @CareiOS 许久未试 |
| 42 jijiwaiwai 2017-10-09 21:26:43 +08:00 @chen2016 你的代码问题 |
| 43 jko123 OP @jijiwaiwai 已经不用 execjs 了,看最后 |
 | 44 fuxkcsdn 2017-10-09 21:47:26 +08:00 via iPhone @jadec0der 肯定是去哪儿,携程的技术实力在去哪儿面前… 爬过最难的是去哪儿,不用 headless 浏览器简直难爬,曾尝试跟踪解密 js,跟踪了半天被叫去做其他事,之后再没心情弄了… |
 | 45 swirling 2017-10-09 22:01:43 +08:00 我最近很烦 silverlight 数据传输通过 WCF 传输 contenttype 是 msbin 1 大概是我没见过世间险恶吧 |
 | 46 AlwaysBehave 2017-10-09 22:18:18 +08:00 |
 | 47 opengps 2017-10-09 23:30:51 +08:00 via Android 我说个吧,很多人好奇为啥方式不能偷我接口,原因是,没有 reffer 的都被我关闭了输出,就这样很多人第一步没走通就不走了 |
 | 48 doubleflower 2017-10-10 00:03:10 +08:00 @anoymoux 搞这么费劲其实真要破也容易,用个 headless 浏览器,用 js 判断这个 li 的样式是否被隐藏了。 |

 | 50 Lguo 2017-10-10 01:27:20 +08:00 via Android 请教一下各位兄弟们这个代理网站列出来的端口要怎么抓 http://www.goubanjia.com/ |
 | 51 RqPS6rhmP3Nyn3Tm 2017-10-10 05:36:27 +08:00 我遇到最恶心的是哔哩哔哩,appkey 混淆得没法看 最后乖乖 youtube-dl |
 | 52 gfcddz 2017-10-10 08:45:32 +08:00 via Android 国外的一个全站 http/2.0 协议,python 支持 http2.0 的库压根用不了,只能用 seleniim 了 |
 | 53 kran 2017-10-10 08:48:31 +08:00 投毒假数据啊,最坑的一次,见过一本写神经病的小说,看了两章胡言乱语才发现是网站爬虫被投假数据。文笔不错,没得逻辑。 |
 | 54 Marsss 2017-10-10 08:52:10 +08:00 遇到最恶心的是 js 检测是否有鼠标操作且正常,并将其一并参与请求。 |
 | 56 grey0207 2017-10-10 09:31:08 +08:00 这个网站的源图片都打乱的,又禁止右键,感觉要抓图只能靠截图了 http://viewer.comic-earthstar.jp/viewer.html?cid=1e48c4420b7073bc11916c6c1de226bb&cty=1&lin=0 |
 | 57 qqpkat2 2017-10-10 09:36:29 +08:00 这种反扒太简单了,程序内嵌浏览器直接破了 遇到最厉害的还是百度的,提交的时候记录了鼠标动作.....不过还是能破解 |
 | 58 wfd0807 2017-10-10 09:47:32 +08:00 这个还算简单,毕竟可以分析出来,解密过程不依赖浏览器; 看看汽车之家的反爬虫技术,用伪元素的 text 渲染文字。。。 |
 | 60 BlackGrasshopper 2017-10-10 10:19:28 +08:00 @grey0207 这个网址厉害了 |
 | 61 huangfs 2017-10-10 10:25:38 +08:00 最恶心的应该是不限制你 但是给假数据吧 这种真的防不胜防。 |
 | 62 sucaihuo 2017-10-10 10:32:02 +08:00 从来没研究过这方面,要学的东西还真多啊 |
 | 63 wmhx 2017-10-10 10:44:56 +08:00 之前搞刷单用 paypal 支付, 先是写代码全程模拟结果发现 paypal 的 js 请求参数和名称全是动态生成,没找到规律,就换了 seleniim, 结果检测是否是 robot,用的是一家以色列公司的技术,花了近 2 周时间没搞定, 后来一查,这家牛逼的公司首页就说,如果用了他的技术被 robot 操作了. 全额赔付. |
 | 66 Felldeadbird 2017-10-10 13:16:22 +08:00 目前遇到过最搞笑的: 客服:某个网站的价格爬取失效了。快去看看 我认真观看后,发现他们价格要登录才可以看到价格。 终于弄好了。准备上线。 客服:那个网站价格爬取正常了。 我再去看了一下……原来是他们网站出问题了= =。导致非会员价格不显示。 |
 | 67 yxy2829 2017-10-10 14:07:03 +08:00 各种验证码算吗?一堆汉字里面选四字成语,按顺序点击 |
 | 68 SlipStupig 2017-10-10 14:15:09 +08:00 数据真假掺着来.... |

 | 75 mingyun 2017-10-29 14:21:29 +08:00 @zbl430 https://zhuanlan.zhihu.com/p/29196829 这个网站反爬策略 |