

这是一个创建于 2304 天前的主题,其中的信息可能已经有所发展或是发生改变。

 | 1 mikeguan 2019 年 9 月 27 日 via Android 这个得上查询分析结果,explain 一下 |
 | 2 571726193 OP |
 | 3 dog82 2019 年 9 月 27 日 表重建一下,我司把图片的二进制编码也存在 mysql 里,导致查询巨慢,我是第一次看到这么玩 |
 | 5 Vegetable 2019 年 9 月 27 日 一般来说,选择所有也不存在说为查询时间,这个时间包括了网络传输时间(不太确定),我看你这表字段挺多的,可能是记录太大了传的慢.不然你试一下 select id from table? |
| 6 571726193 OP @Vegetable select id 挺快的 ,实际业务 也没有 select * 的 但是 我就是 试了一下 感觉查询时间 太长了 不知道 啥问题 ,带宽目前是 5M 的 不知道有关系没 |
 | 7 arrow8899 2019 年 9 月 27 日 你这是因为数据量太大了,基本都是网络传输的时间,你切换到 概况 一栏,像可以看具体的时间。 |
 | 8 awker 2019 年 9 月 27 日 type: ALL 就说明走了全表扫描,没有用到索引。 |
| 9 mikeguan 2019 年 9 月 27 日 via Android 查所有记录和大的分段查询都很慢,尽量避免吧。像 Redis 的 keys *都有可能直接搞挂服务 |
 | 10 b821025551b 2019 年 9 月 27 日 type:ALL,没有索引;但是没索引也不至于这么慢,看看网络和磁盘 IO |
 | 11 bigbigeggs 2019 年 9 月 27 日 我遇到过。和五楼观点一样。每一行的表字段太多,**从磁盘加载到内存太耗时间了**,如果仅查询 select id 那肯定不一样。不是查询慢,是磁盘到内存慢。我之前写过一篇博客,楼主可以看看。https://www.cnblogs.com/wenbochang/p/10257416.html 。 |
 | 12 HowardTang 2019 年 9 月 27 日 对接过 14s 的接口,手动狗头 |
 | 13 CallMeReznov 2019 年 9 月 27 日 首先,不要用 * 其次,我说完了. |
 | 14 himesens 2019 年 9 月 27 日 * 换成具体列,或者把表拆分。 |
 | 15 Raymon111111 2019 年 9 月 27 日 一行数据多大? |
 | 16 TanLeDeDaNong 2019 年 9 月 27 日 究竟多少字段,多少数据,你敢把查询结果导出一份.sql 看看大小吗 |
 | 17 javen73 2019 年 9 月 27 日 |

 | 18 qq976739120 2019 年 9 月 27 日 网络原因吧,3000 条数据,本地写个 txt 文件再读也不至于 4 秒 |
 | 20 awanabe 2019 年 9 月 27 日 没走索引... |
 | 21 Aresxue 2019 年 9 月 27 日 记录值太大,可能存了长文本或者图片,导致页分裂了,再加上网速不行 fetch 的时候自然就慢了 |
 | 22 zdt3476 2019 年 9 月 27 日 工具的这个时间可能包括了网络 IO。 建议你到数据库所在的机器上进行查询。3000 条数据查询全表也不可能达到秒级别的 |
 | 23 jay4497 2019 年 9 月 27 日 倾向于网络传输时间长了,一下查询三千条数据,传输肯定要时间,按上边说的点开概况看看,是不是 sending data 用时最长。。。 |
 | 24 golden0125 2019 年 9 月 27 日 CPU,IO,网络 一般就这三点 |
 | 25 harvies 2019 年 9 月 27 日 这个 4 秒包含网络传输吧,用 heidisql 查下,能看到查询和传输单独用了多久 https://imgur.com/Ggp4Rhg |

 | 27 tonic 2019 年 9 月 27 日 有主键吗........ |
 | 28 gemini767 2019 年 9 月 27 日 ``` SELECT * FROM tagert_table AS t1 INNER JOIN (SELECT id FROM target_table WHERE category_id = 15) AS t2 USING (`id`) ``` 可以满足? |
 | 29 5200 2019 年 9 月 27 日 直接 mysql 命令模式连接 127.0.0.1 试试,然后不要用*。 用一些可视化工具,如果每一条的数据太多了,把数据绘制到表格里面会巨慢。 |
 | 30 bzj 2019 年 9 月 27 日 楼上说不要用*的基本都是半吊子水平,实际上在没有索引的情况下,select * 和 select `field` 效率差不多 |
 | 31 zhuzhibin 2019 年 9 月 27 日 via iPhone 没有命中索引哦 |
| 35 571726193 OP @golden0125 谢谢 老哥 |
 | 37 haishiwuyuehao 2019 年 9 月 27 日 那两个查询参数的索引加上了吗。 照理说不应该啊,才 3000 条数据 |
 | 38 kobayashiro 2019 年 9 月 27 日 和 * 没关系。。 * 在运行之前会自动解析成字段的。 你这个首先 索引没上。其次返回了 2000 多条数据 这个数据传输上应该不小 |
 | 39 Egfly 2019 年 9 月 27 日 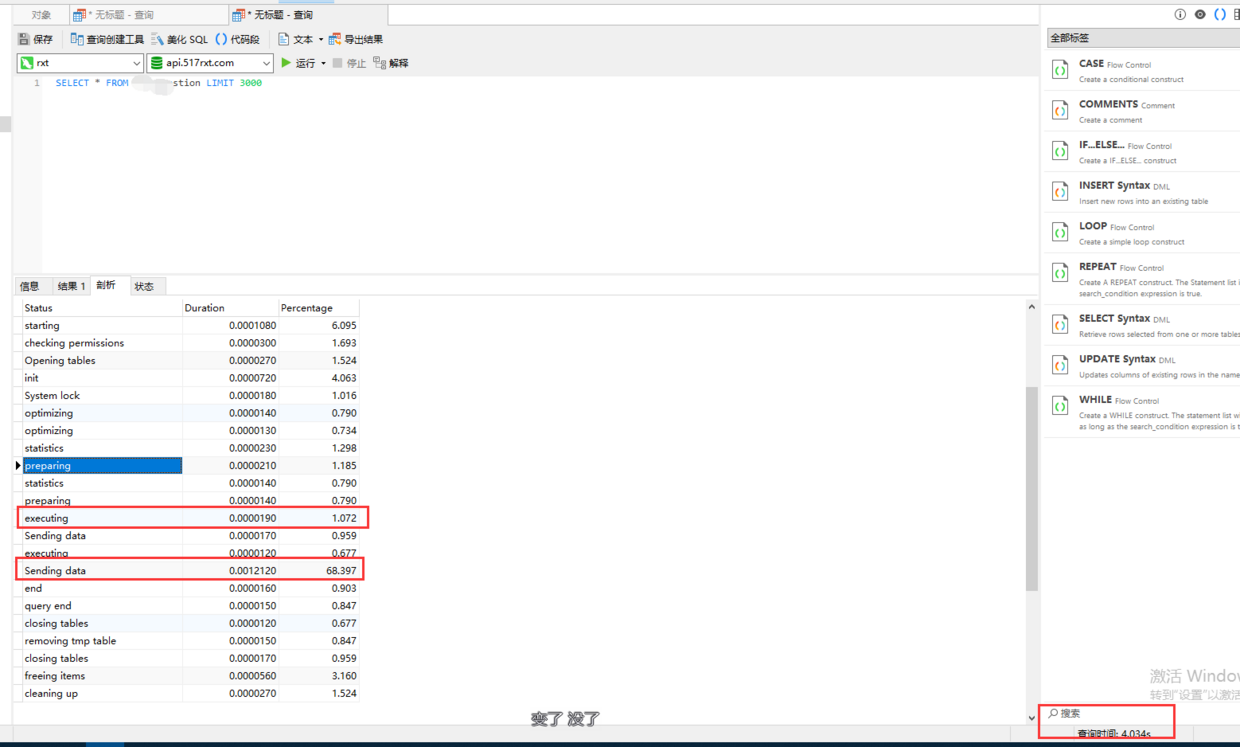 查询之后可以先看看剖析,看一下是那个步骤耗时最多。我截图中就是 sending data 的动作耗时最多,占了 65% |
 | 41 519718366 2019 年 9 月 27 日 这是 mysql workbench 辣鸡而已,莫慌....我也遇到过你这个情况 workbench 逆天用时,然后用 sequel 执行了下很正常。 mac 上数据库工具使用感受: workbench:敲 sql 时能实时报错,但是 select 不稳,有时莫名逆天慢 sequel:select 执行的稳,但是写 sql 的提示是真的不顺手 navicat:提示立马就出来,写 sql 特别顺,执行起来也相对稳,有时候 stop query 时会导致程序未响应...只能强关 现在基本在用 sequel,因为他用起来稳定...不会莫名奇妙逆天慢 |

 | 43 Macolor21 2019 年 9 月 27 日 @HowardTang 对接过 2 分钟的接口,用的是 Chunked transfer encoding。每一个 chunk 的速度都是秒级=.= |
 | 44 cz5424 2019 年 9 月 27 日 via iPhone *不*影响网络传输时间....取一列数据量少.... |
 | 45 zrc 2019 年 9 月 27 日 查询条件是 varchar ?还是 int,遇到过 varchar 然后没加引号很慢的情况 |
 | 46 feiffy 2019 年 9 月 27 日 ( 1 )只查询需要的字段 ( 2 )对查询字段建立索引 |
 | 47 iluckypig 2019 年 9 月 27 日 每行数据是不是很大啊? 3000 条就算没索引没不至于这么慢 |
 | 48 skyqqcc 2019 年 9 月 28 日 via Android 2H4G 机房 1000M 宽带内网(可能更高),一直都没怎么在乎过性能问题..... |
 | 49 xiaodim 2019 年 9 月 28 日 大家没注意到他的图下方的滑动条吗 看似每行的列字段好多 |
 | 50 tailf 2019 年 9 月 28 日 肯定是字段很大,下载时间很长 |
 | 51 LuckCode 2019 年 9 月 28 日 1. explain 说的是 all,扫全表。 2. 你查的结果是 3k 条,但是得到这 3k 条的过程是扫描了全表的,即使前 3k 条就是你要的数据了,sql 还是会扫描完,因为 sql 不知道。 3. 联合索引有没有用上。 4. 可能有大量的随机 IO。 |