

奇怪的是,现在已经很少有人认真讨论 API 了。
不是因为 API 没那么重要了。恰恰相反,API 比以前更重要。现代软件几乎都是靠 API 连起来的:SaaS 产品、内部平台、移动应用、合作方集成、自动化工作流,还有现在越来越多通过 HTTP 形态边界调用工具的 AI agent 。
但 API 生态却显得异常安静,甚至有点认命。好像这个问题已经被解决了。好像 Postman 、Swagger 、一个测试框架、一些 CI 胶水代码,再加上一堆半维护状态的示例文件,就是最终形态。
就连 GraphQL 、gRPC 这样重要的新方向,也没有真正重新点燃整个 API tooling 的讨论。它们改变了一些技术边界,但 workflow 问题并没有消失。
我不觉得这个问题真的被解决了。
我觉得只是大家已经习惯了这些摩擦。
最容易改善的那部分 API 问题,已经被 AI 戏剧性地改善了
很长一段时间里,API 最显眼的问题其实是文档。
文档不完整,文档会漂移,文档里的例子总是过于理想化,和真实行为对不上。Swagger 和 OpenAPI 当然帮了很多,但工作流还是那一套:先读 spec ,再打接口,发现真实行为和文档不完全一致,更新自己的理解,然后继续往下走。
AI 非常快地改变了这一点。
今天,只要你手里有一个还不错的 spec 、一些示例,甚至只是一个能工作的 endpoint ,AI 就能帮你解释 API 、总结结构、生成 payload 、比较版本、写 client ,回答文档里的问题,速度比大多数人工流程都快。
这是实打实的进步。但它也暴露了一个更深的问题:过去我们对 API 的很多挫败感,其实都被“文档问题”吸收掉了。现在 AI 把这部分大幅改善以后,那些真正没解决的问题反而更难被忽视。
真正的问题从来不只是文档
更难的问题,是理解一个 API 之后发生的所有事情。
你怎么探索它?
怎么把探索过程中有价值的部分留下来?
怎么把一次性的试验,变成可以重复运行的验证?
怎么测试一个真实 workflow ,而不是一堆彼此无关的请求?
怎么从本地探索过渡到 CI ,而不需要重写一遍?
怎么让这整套事情是为 AI 工作,而不是绕开 AI 工作?
这也是为什么 workflow 这么重要。workflow 决定了哪些知识能留下来,反馈能多快回来,一次有价值的试验最后会变成长期资产还是直接消失,也决定了 AI 到底是在一个真实的验证闭环里帮忙,还是只是在生成更多一次性代码。
API 知识到底会沉淀还是蒸发,往往就发生在 workflow 这一层。
我觉得 API 生态真正失败的地方就在这里。我们有很多局部工具:
- 文档工具
- 发请求的工具
- schema 生成工具
- mock server
- 测试框架
- SDK 生成工具
- contract tooling
这些工具里有些是好的。Swagger 是好的。OpenAPI 是有价值的。design-first 也是一个很强的概念。
但如果诚实一点说,这些东西并没有真正改变大多数团队的日常 API 工作流。
这个领域太多产品,只是在不断重新发明 API client ,却几乎没有真正碰 workflow 本身。
这么多年,行业一直在打磨各种“发请求”的变体,然后把这叫做进步。
现实还是一样:你在一个地方探索,在另一个地方写文档,在第三个地方测试,在第四个地方自动化,在别的地方排查失败。真正有价值的知识,就消失在这些缝隙里了。
这才是行业默默接受下来的部分。
举个再普通不过的例子:后端把响应里的一个字段名改了。前端类型过期了,文档里的示例过期了,某个保存下来的请求虽然还能“跑通”,但已经不能代表真实 workflow 。最后测试在 CI 里挂掉,离最初的改动已经非常远。这种事情一点都不罕见,这就是 API 日常工作的一部分。
design-first 适合的是“人和人协调”的时代
design-first 不是坏思路。它本质上是一种为人类设计的协调技术。
它适用于这样一个世界:frontend 和 backend 由不同的人做,甚至在不同团队里,节奏不同,需要在实现发生太多漂移之前先把 contract 对齐。
在那个世界里,spec 要承担很多职责:
- 团队对齐
- mock 生成
- frontend/backend 并行开发
- 实现前 review
- 外部文档
这是一个真实问题,而 design-first 也是一个真实答案。
但 AI 改变了协调模型。
现在,一个开发者带着一个或多个 AI agent ,往往可以在同一个 loop 里同时处理 frontend 、backend 、测试、示例和文档。过去支撑 spec-first workflow 的协调成本,正在快速塌缩。
新的默认工作流越来越像这样:
- AI 写 backend 代码
- AI 写 frontend 代码
- AI 起草测试
- 代码跑起来
- 只有在需要时才生成或更新 API spec
这不意味着 contract 不重要了。
它意味着,重心不再是把 spec 作为起点。
AI 让这个问题更明显,而不是更不重要
很多人会觉得,AI 会降低 API tooling 的重要性。我觉得恰恰相反。
AI 很擅长处理代码、结构化 schema 和明确 contract ,但它并不天然适合碎片化的点击式工作流、陈旧的 collection ,或者散落在不同工具里的运行知识。
如果 AI 能帮你理解一个 endpoint 、起草一个请求,甚至生成一个测试,那当然有用。但如果一旦你想把这些工作保留下来、验证它、在 CI 里重跑、查看失败、或者复用到更大的 flow 里,整个 workflow 就断了,那 AI 并没有解决真正的问题,它只是加速了第一步。
而这恰恰是当前 AI coding tools 在实践里最缺的东西。瓶颈通常不是“更多文档”,而是实时的执行反馈、结构化 trace 、失败断言、环境上下文,以及一种把探索性代码自然沉淀成长期验证资产的方式。
AI 解决了很多 API 解释问题,但它没有解决 API workflow 。甚至可以说,它只是让这个缺口变得更清楚了。
这也是为什么我觉得测试在今天反而更重要。它不应该只是事后检查 endpoint ,而应该是探索变成验证、验证留在代码旁边、同一份 artifact 能穿过本地使用、CI 、debugging ,以及 AI-assisted authoring 的那个地方。
过去的中心是 specification 。
新的中心应该是 executable workflow 。
在 AI 时代,source of truth 不太可能还是一份被精心维护的设计文档,更可能是这些东西的组合:
- 可运行的代码
- 可运行的测试
- trace 和真实响应
- 在需要时生成的 spec
- 能贯穿本地运行、CI 和 debugging 的验证资产
我们不是不需要 contract 。
我们需要的是更少的仪式感,更多可执行的真实。
我觉得 API 生态应该往这个方向走:让 API 探索留在代码里,让有价值的发现自然变成可运行检查,让 AI 能参与写和重构,并让同一套 artifact 贯穿本地运行、调试和 CI 。
这也是我希望 Glubean 推动的方向:不是再做一个发请求的工具,而是围绕这个 loop 来设计工具。
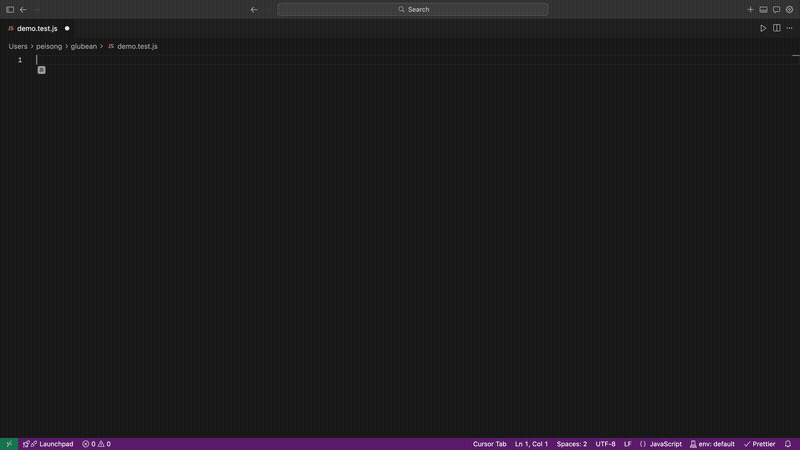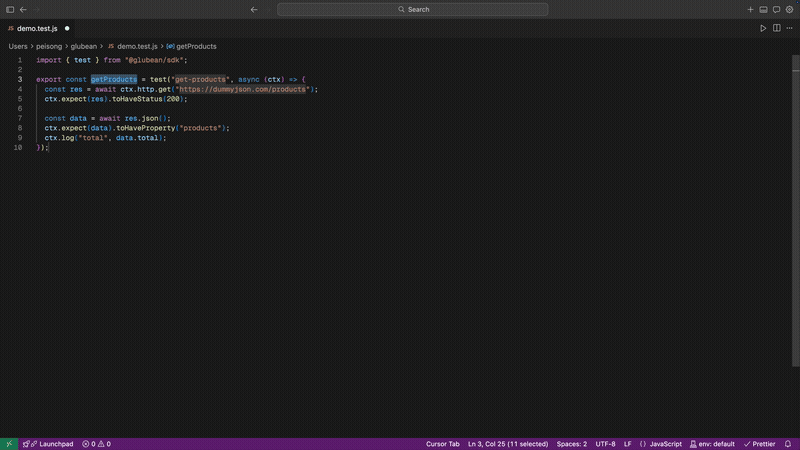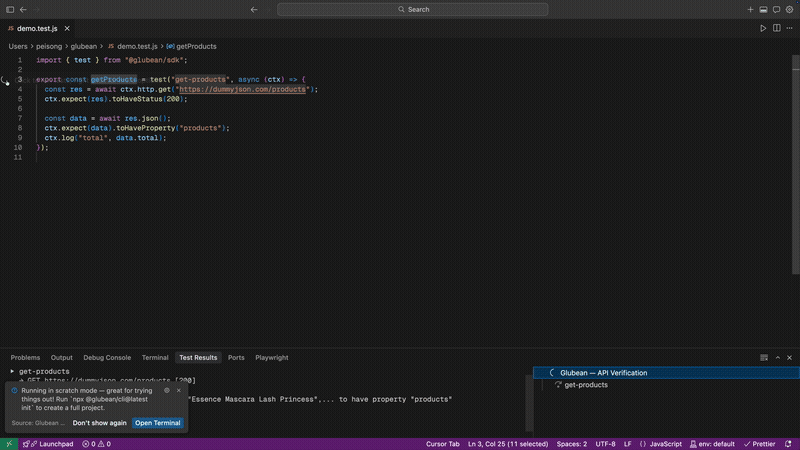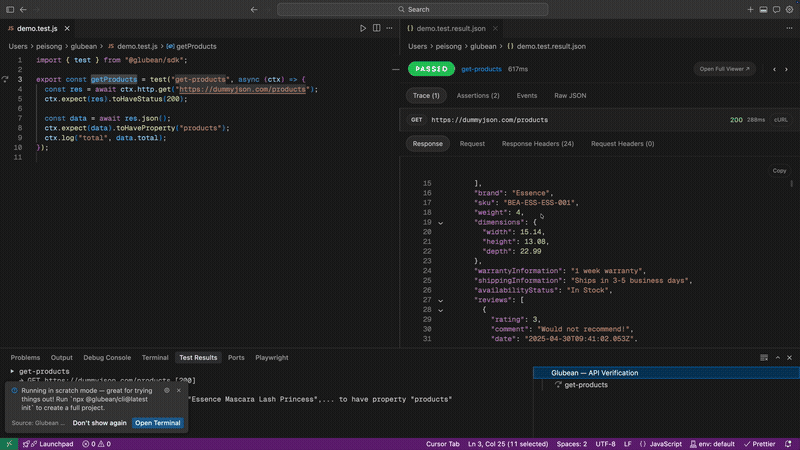
这件事之所以重要,是因为不管上层抽象怎么变,真正的边界依然很像 HTTP:请求、响应、鉴权、重试、headers 、payload 、失败,以及调用之间的状态转换。如果这个边界依然是核心,那么围绕它的 workflow 就不应该永远这么碎。
是时候重新认真对待 API tooling 了
我不觉得结论是:我们需要再做一个 Swagger clone 。我也不觉得结论是:AI 会让 API tooling 消失。
恰恰相反,真正的结论是:是时候重新认真对待 API 生态了。
不是把它只当成文档、schema 、生成代码,或者一个界面更漂亮的 request sender ,而是把它当成一个 workflow 问题。
一个真正像样的 API workflow ,应该让你理解一个 API 、探索它、保留有价值的部分、把它们变成验证、在不同环境中运行、检查失败,并且让这一整套 loop 能和 AI 更好地协同,而不是在 AI 进入后直接断裂。
而这件事,到今天仍然缺席。
我们不再讨论 API ,不是因为它已经完美了,而是因为我们已经不再期待它会变得更好了。
我觉得这是个错误。
我做 Glubean 的原因其实很简单:API 生态一直都没有让我觉得“足够好”。不管是探索 workflow 、测试体验,还是往自动化里的交接,都没有。
所以我想再试一次。不是因为我觉得一个新工具就能神奇地修好一切,只是因为我不觉得这个社区应该放弃这个问题。
目前尚无回复