

这是一个创建于 183 天前的主题,其中的信息可能已经有所发展或是发生改变。
20 种数组去重的方法
开始
本文有很多问题,并没有直接给出答案,大伙有自己思考的可以评论区留言。关于时间复杂度只是一个大体的估计。20 种只能说保守了,20 种都是单论思路而已,暂时没想到更多的思路,有其他方法的可以评论区留言。
easy 模式
此时我们有一个极其简单的数组,它可能包含也不包含重复项。我们需要删除重复项并将唯一值放入新数组中。
const names = ["a","b","c","d","e","a","b"]; new Set
时间复杂度:O ( n^2 ), 但扩展符运算符耗费时间有点多,一般推荐
最简单的,new Set去重
let newNames = [...new Set(names)] new Set
时间复杂度:O ( n^2 ), 比扩展运算符还费劲,一般推荐
let newNames = Array.from(new Set(names)) new Map
时间复杂度:O ( n^2 ), 一般推荐 通过new Map原型上的方法去重。
function dealArr (a) { let newArr = [] let map = new Map() for(let i = 0;i<a.length;i++){ if (!map.has(a[i])) { map.set(a[i], true) newArr.push(a[i]) } }; return newArr } 笨蛋双重 for 循坏
感觉实在没什么好说的,就纯暴力去重
function dealArr(a){ let len = a.length; for(let i = 0; i < len; i++) for(let j = i + 1; j < len; j++) if(a[j] == a[i]){ a.splice(j,1); j--; len--; } return a; } function dealArr(a) { let b = []; for (let i = a.length - 1; i >= 0; i--) { for (let j = a.length - 1; j >= 0; j--) { if (a[i] == a[j] && i != j) { delete a[j]; } } if (a[i] != undefined) b.push(a[i]); } return b; } 单 for 循坏
时间复杂度:O ( n ), 它真的太快了,它是所有种类的方法里最快的,大伙可以试一试, 推荐
for循坏+hash查找
function dealArr(a) { let obj = {}; let out = []; let len = a.length; let j = 0; for(let i = 0; i < len; i++) { let item = a[i]; if(obj[item] !== 1) { obj[item] = 1; out[j++] = item; } } return out; } 下面这种会快一点。
function dealArr(a) { obj = {}; for (let i = 0; i < a.length; i++) { obj[a[i]] = true; } return Object.keys(obj); } for and includes
时间复杂度:O ( n^2 ), 不推荐
for循环 + includes判断,includes会循坏到找到为止或者全部,所以挺慢的。
function dealArr(a) { let newArr = []; let j = 0; for (i = 0; i < a.length; i++) { let current = a[i]; if (!newArr.includes(current)) newArr[j++] = current; } return newArr; } for and indexOf
时间复杂度:O ( n^2 ), 不推荐
for循环 + indexof查找,indexOf会找到第一个为止或者全部。
function dealArr(a) { let newArr = []; let j = 0; for (i = 0; i < a.length; i++) { let current = a[i]; if (newArr.indexOf(current) < 0) newArr[j++] = current; } return newArr; } for and lastIndexOf
时间复杂度:O ( n^2 ), 不推荐
没啥好说的,其实和indexOf一样只是正反序查找的区别而已,问就是慢
function dealArr(a) { let newArr = []; let j = 0; for (i = 0; i < a.length; i++) { let current = a[i]; if (newArr.lastIndexOf(current) < 0) newArr[j++] = current; } return newArr; } for and newArr
相比哈希也慢
一个新数组和原数组对比,不同则放在新数组,最后返回。
function dealArr(a) { let newArr = [a[0]]; for (let i = 1; i < a.length; i++) { let repeat = false; for (let j = 0; j < newArr.length; j++) { if (a[i] === newArr[j]) { repeat = true; break; } } if (!repeat) { newArr.push(a[i]); } } return newArr; } for and sort
想想有什么问题
先将原数组排序,再与相邻的进行比较,如果不同则存入新数组。
function dealArr(a) { let formArr = a.sort() let newArr=[formArr[0]] for (let i = 1; i < formArr.length; i++) { if (formArr[i]!==formArr[i-1]) newArr.push(formArr[i]) } return newArr } splice
O ( n^2 ),特别慢
function dealArr(arr) { let i,j,len = arr.length; for (i = 0; i < len; i++) { for (j = i + 1; j < len; j++) { if (arr[i] == arr[j]) { arr.splice(j, 1); len--; j--; } } } return arr; } filter and indexOf
时间复杂度:O ( n^2 )一般推荐
filter的本质相当于,在每一个元素上添加检查,检查该元素在数组中的第一个位置是否等于当前位置,indexof是找到第一个符合条件的元素。重复元素在数组里的位置是与找到的第一个不同的。
let newNames = names.filter(function(item, index) { return names.indexOf(item) == index; }) 但其实上述方法不是很好,因为可能你会操作到原数组,导致原数据变化,那么我们可以直接用filter的第三个参数来做这件事,保证原数据的不可变性。
let newNames = names.filter(function(item, index, self) { return self.indexOf(item) == index; }) filter and sort
时间复杂度:O ( n )- O ( n^2 )不推荐
就是先对数组进行排序,然后删除与前一个元素相等的每个元素。大家也可以想想这方法有啥问题。提示:排序。
let newNames = a.sort().filter(function(item, index, self) { return !index || item != self[index - 1]; }); reduce
实在是太慢了,不推荐
reduce 果然是 js 里最完美的 api。
let newNames = names.reduce(function(a,b){ if (a.indexOf(b) < 0 ) a.push(b); return a; },[]); 笨蛋 hashMap
时间复杂度:O ( n )一般
这个方法有点笨,通过哈希表查找来fiter,大伙可以想一想缺陷是什么。(提示:对象,key 。 测试用例: [1, '1']。)
function dealArr(a) { let seen = {}; return a.filter(function(item) { return seen.hasOwnProperty(item) ? false : (seen[item] = true); }); } Normal 模式
easy 模式下我们都只处理一些基数组,接下来我们处理一下数组对象+基数组。
一般聪明的 hashMap
一般聪明的 hash,大伙看到这应该能明白上面的问题是什么了吧。经过一点点优化,我们对原始值和引用对象分开处理,到这它已经有了处理对象引用重复的能力了,但是它确实还不够聪明。
就像这样: 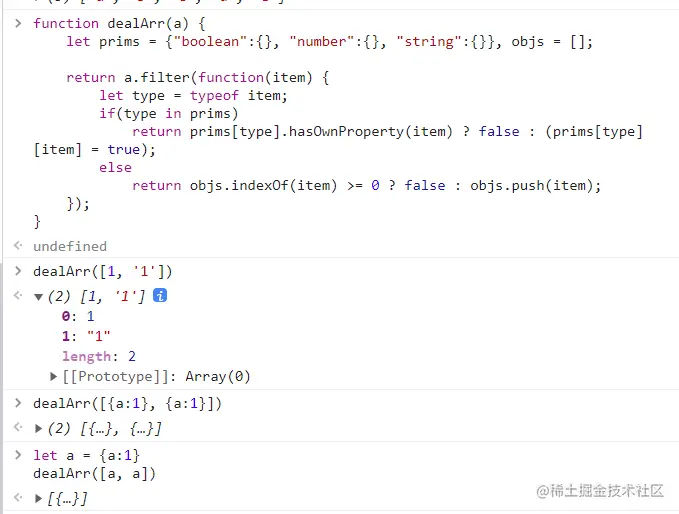
function dealArr(a) { let prims = {"boolean":{}, "number":{}, "string":{}}, objs = []; return a.filter(function(item) { let type = typeof item; if(type in prims) return prims[type].hasOwnProperty(item) ? false : (prims[type][item] = true); else return objs.indexOf(item) >= 0 ? false : objs.push(item); }); } 聪明的 hashMap
我们有时候可以写一个通用的函数,通过回调函数来优雅的完成过滤,比如这样! .webp?updatedAt=173799905869) 大家可以思考一下为什么
大家可以思考一下为什么JSON.stringify,能完成过滤。
function dealArrByBey(a, key) { let obj = {}; return a.filter(function(item) { let k = key(item); return obj.hasOwnProperty(k) ? false : (obj[k] = true); }) } 稍微炫一点
但这都es6了还这么玩不太合适,这样会好看一些。 .webp?updatedAt=1739799905593)
可以看到过滤了后面的 b.
function dealArrByBey(a, key) { let obj = new Set(); return a.filter(item => { let k = key(item); return obj.has(k) ? false : obj.add(k); }); } 特别炫
感觉这么写就特别开心了,虽然可读性不好,而且也不是很快,但它很帅啊。但这三种方法,是有点区别的,上面两种方法是保留第一个,过滤掉后面的,而这种方法保留的是最后一个,大伙可以思考一下为什么。
function dealArrByBey(a, key) { return [ ...new Map( a.map(x => [key(x), x]) ).values() ] } hard 模式
珂里化 + 链式调用
em ,都写到这了,我们可以再进阶再抽象一下,让我们的去重也可以写成一个非常抽象的链式调用。多重箭头函数其实就是函数珂里化的语法糖( fn(a,b,c)改造成 fn(a)(b)(c)),让我们完成一个参数对齐。 .webp?updatedAt=1739799905803)
const apply = f => a => f(a); const flip = f => b => a => f(a) (b); const uncurry = f => (a, b) => f(a) (b); const push = x => xs => (xs.push(x), xs); const fold = f => acc => xs => xs.reduce(uncurry(f), acc); const some = f => xs => xs.some(apply(f)); const dealArrByFn = f => fold( acc => x => some(f(x)) (acc) ? acc : push(x) (acc) ) ([]); const eq = y => x => x === y; dealArrByFn(eq)(names) 总结
大伙可以思考一下,这 20 种方法的快慢, [关于我](关于我)
 | 1 speedmancs 183 天前 sort filename | uniq |
 | 2 lichuyi 182 天前 别把掘金那一套玩意搬来这里 |
 | 3 dddd1919 182 天前 嗯,回字有四种写法 |
 | 4 langhuishan 182 天前 新时代,回字有五种写法 |
 | 5 bfdh 182 天前 @speedmancs #1 为啥不直接 sort -u |
 | 6 yesterdaysun 182 天前 为什么前面几个是 n^2, 不应该是 nlogn 么, 还有后面的单 for 循环, 为什么是 n, 因为使用了 object hash 就不算复杂度了? |
 | 7 zwlinc 182 天前 看了前面几个,复杂度都没算对( |
 | 8 burnsby 182 天前 new Set 去重性能是 O(n)? |
 | 9 cheng6563 182 天前 没有 sleep 大法 |
 | 10 MRG0 182 天前 直接[...new Set(array)] |
 | 11 csfreshman 182 天前 点开果然没失望,新时代 茴字的几种写法 |
 | 12 ianchoi 182 天前 |
 | 14 Obj9527 182 天前 这种东西应该出现在掘金,对于实际工作毫无意义 |
 | 15 zhufpy 182 天前 Only Set |