
/div>
爱意满满的作品展示区。

这是一个创建于 249 天前的主题,其中的信息可能已经有所发展或是发生改变。
大学时还在用 tesseract 来实现 OCR ,短短几年随着多模态大模型的崛起,OCR 技术正经历一场颠覆性变革它不再局限于“识别文字”,而是进化为一套能够理解上下文、推理语义、甚至主动纠错的“视觉认知系统”。
用支持视觉的大模型接口开发了一个识别食品成分的小程序,不仅摒弃了传统 OCR 技术,更直接绕过了第三方食品数据库的调用环节。
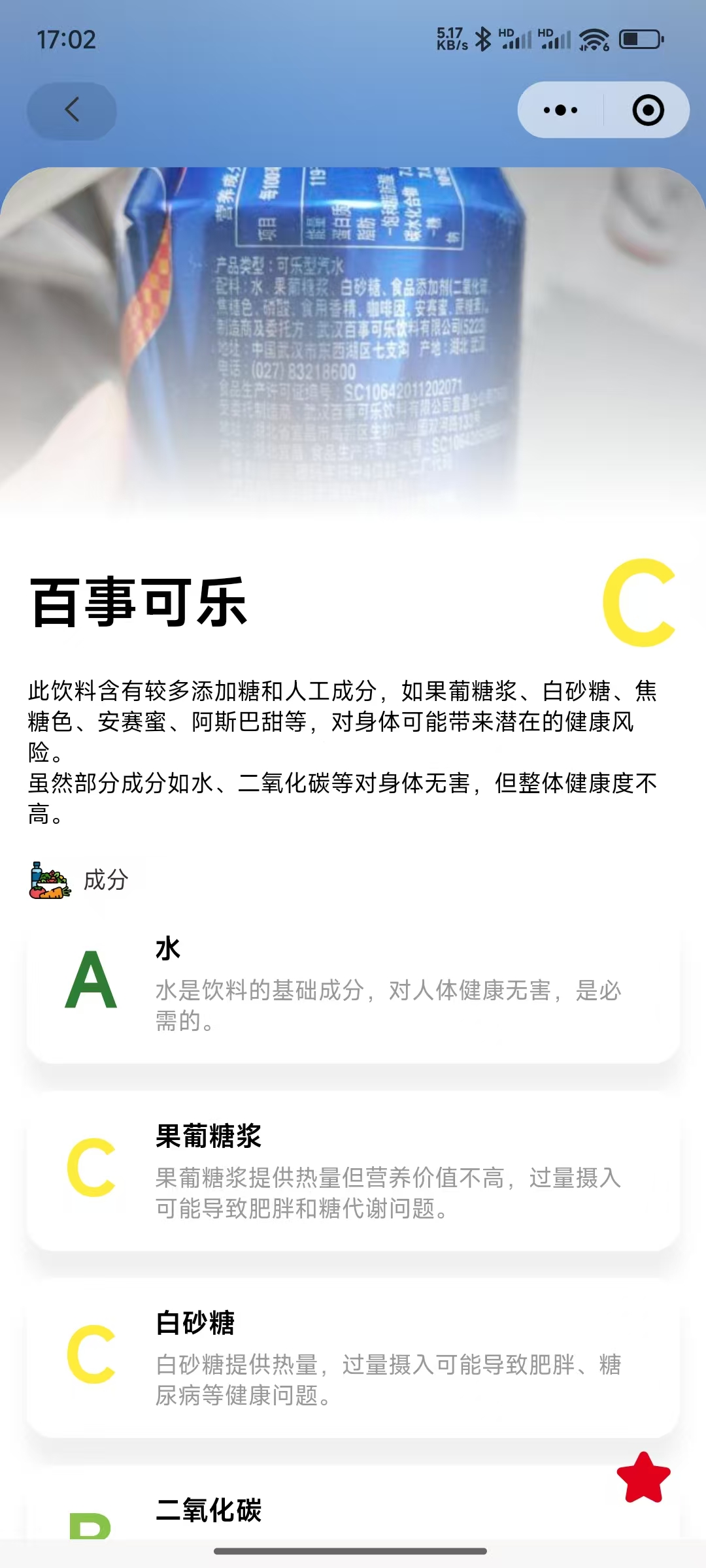

 | 1 hahasong 249 天前 调用的哪个平台,还是自己部署了一套 |
 | 3 shdm520 249 天前 是本地部署的吗 |
 | 5 Solix 249 天前 via iPhone 商业化路径,多加一步,推荐更健康的相同食品 |
 | 7 mumbler 249 天前 chatgpt 出来前夕,正在开发一个拍照识别食物嘌呤,热量的小程序,有大模型简单多了,不过国内没什么人会为这种应用付费,国外同类产品已经千万级收入了 |
 | 8 yoruoxx 249 天前 wanlei ? |

12 4UyQY0ETgHMs77X8 247 天前 @mumbler #7 因为国内这些数据普通人不知道影响什么,国外健身人群和国内对比一下就知道了,国内都是在卷的路上谁在乎这个那个 |
13 4UyQY0ETgHMs77X8 246 天前 用了几天,今天第一次出问题,白色魔爪全部扫描识别完有点乱码合成一个了 |
 | 14 lidinghui OP @FlorentinoAriza 什么图,我试试看 |
15 4UyQY0ETgHMs77X8 246 天前 @lidinghui #14 没保存,就是白色魔爪你给他弄扁了拍一下看看,可能配料太多的问题  |
| 16 lidinghui OP @FlorentinoAriza 确实有这个情况,已做修改 |
17 4UyQY0ETgHMs77X8 245 天前 @lidinghui #16 这执行力 |