

这是一个创建于 406 天前的主题,其中的信息可能已经有所发展或是发生改变。
大家好,很高兴在这里向各位介绍我们的产品 Free QWQ 。这是世界上第一个完全免费、无限制、无需注册登录的分布式 AI 算力平台,基于 QwQ 32B 大语言模型提供强大的 AI 服务。
传送门:(https://qwq.aigpu.cn)立刻开始使用免费 API
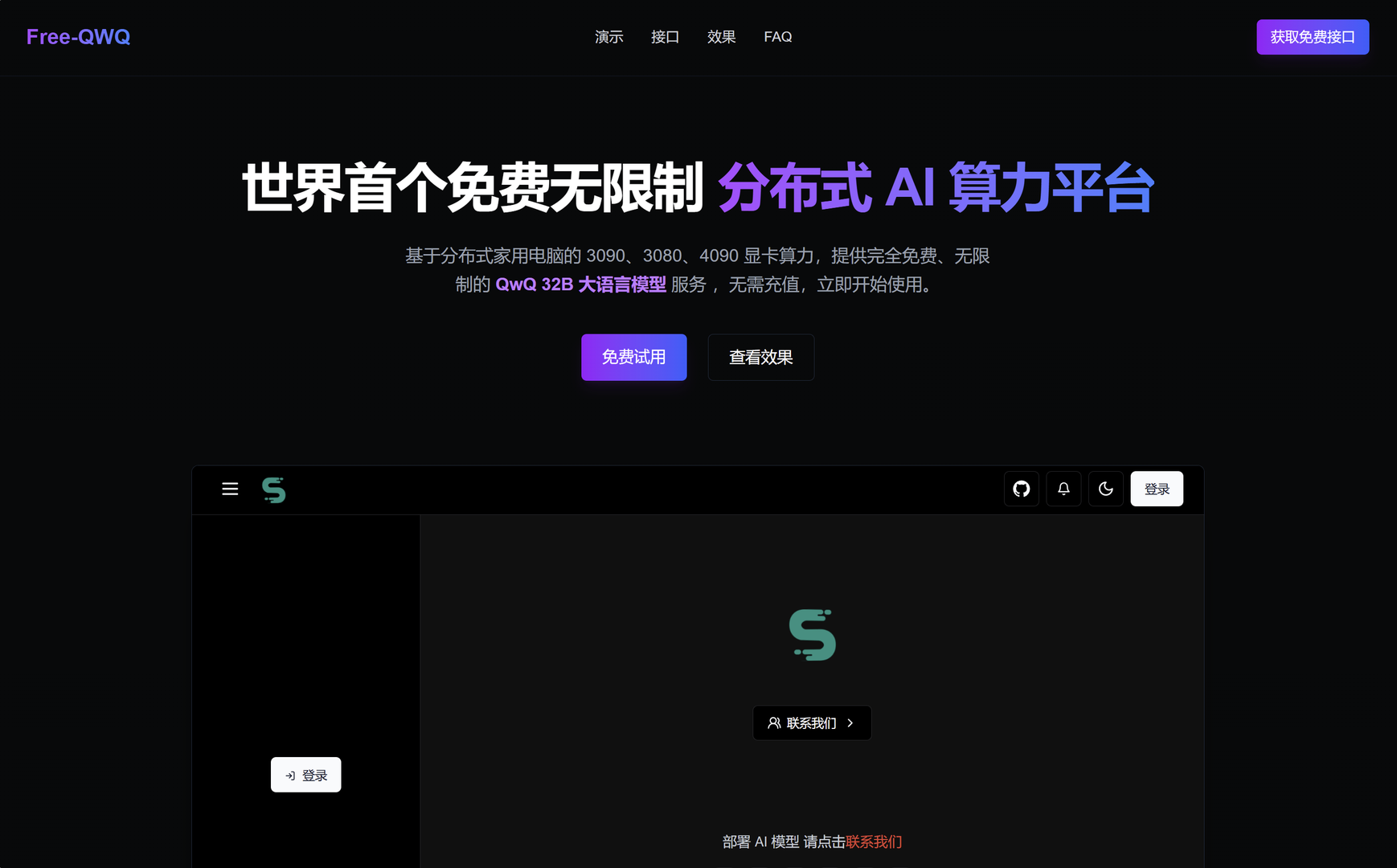
为什么开发 Free QWQ ?
目前市面上的 AI 服务要么收费昂贵,要么有严格的使用限制。因为大语言模型的 GPU 服务器成本非常非常高,尤其是像 QwQ 32B 这样的大规模模型,全世界都没有这样一个完全免费、无限制的产品。
因此,我们希望通过分布式家用显卡算力网络,打造一个零门槛、高性能的 AI 服务平台,让所有人都能享受 AI 带来的便利。
为什么取名叫 Free QWQ ?
Free 代表我们的核心理念 - 让 AI 服务完全免费,QwQ 则来自于我们采用的 QwQ 32B 大语言模型,这是阿里最新开源的强大模型,其性能媲美 DeepSeek-R1 、o1-mini 等明星模型。
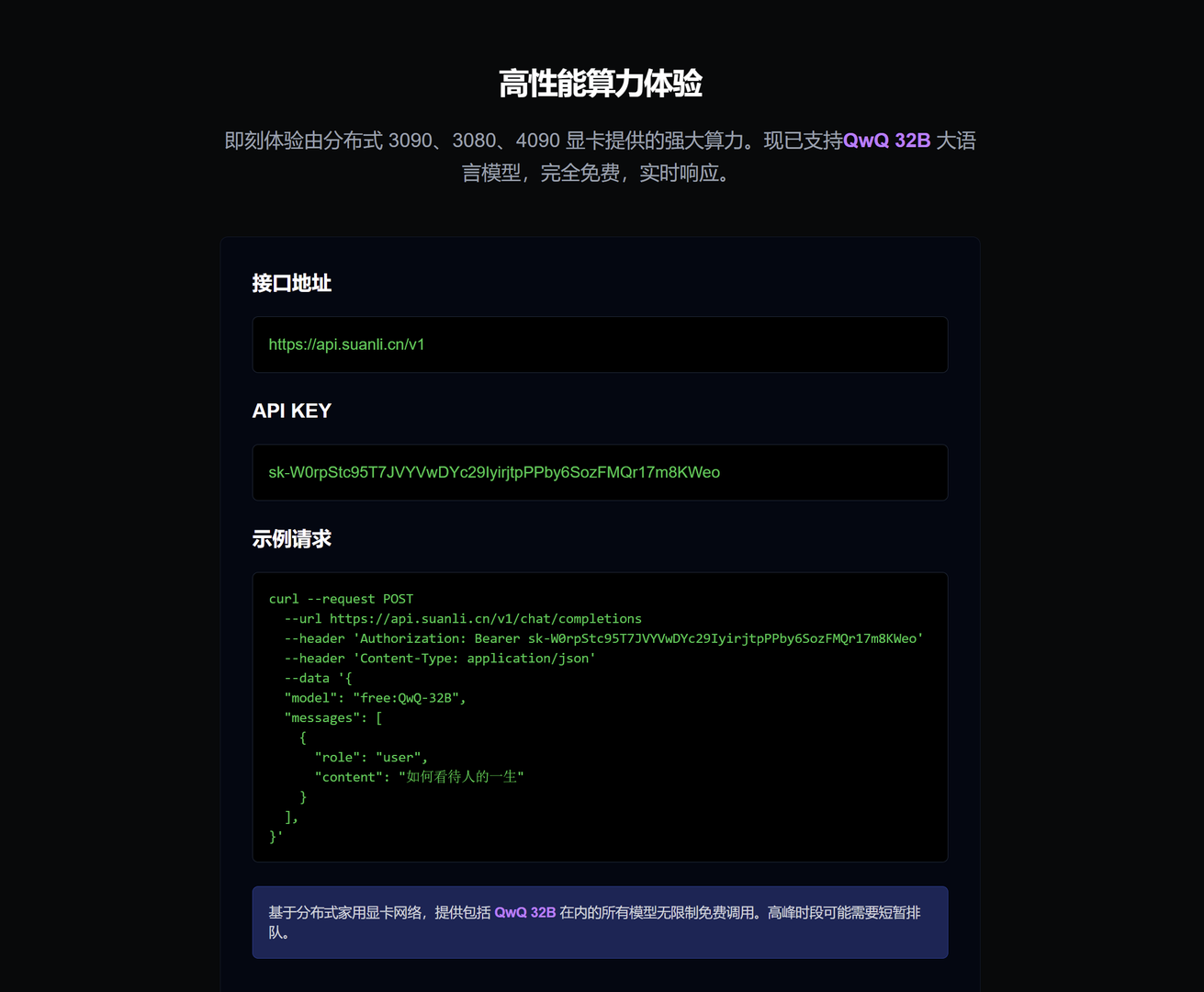
如何实现免费服务?
我们采用创新的分布式算力架构,整合了来自全球的闲置显卡资源,包括个人电脑和网吧的 3090 、4080 、4090 等高性能显卡。通过这种方式,我们构建了一个庞大的分布式计算网络,可以为用户提供强大而免费的算力支持。
核心特点
- 完全免费:无需付费,无使用次数限制
- 零门槛:无需注册登录,获取 API Key 即可使用
- 高性能:基于 QwQ 32B 模型,性能媲美主流商业模型
- 实时响应:优化的分布式推理系统,确保快速响应
- 安全可靠:采用安全稳定的分布式计算网络
- 简单部署:提供一键部署方案,无需专业知识
- 灵活接入:支持 API 调用和在线 Chat Bot 两种方式
- 收益共享:用户可以共享闲置算力获得积分收益
技术优势
- 分布式算力网络:已接入超过一万台个人电脑和数十万台网吧的闲时算力资源
- 高性能推理:在 RTX 4090 上可达到 30-40 tokens/秒的推理速度
- 优质模型:采用 QwQ 32B 模型,在数学推理、代码生成和通用任务处理方面表现出色
- 安全保障:高度重视用户隐私和数据安全,提供全方位的安全保护
看看效果

使用方式
- 访问 https://qwq.aigpu.cn/ 获取免费 API Key
- 通过 API 接口调用服务
- 或直接使用在线 Chat Bot 体验
支持平台
本项目得到以下平台的大力支持:
- 共绩算力 (https://gongjiyun.com)
- 算了么 (https://suanleme.cn)
最后
如果大家觉得这套页面 UI 样式不错,稍后我会开源到 Github 上,欢迎大家 fork 和 star 。
 | 1 ucaime 2025 年 3 月 7 日 免费的才是最贵的,没点进去盲猜几个可能: 1. 免费不等于永久免费,先进来再收割? 2. 想真永久免费必须贡献自己的算力? |
 | 3 jroger 2025 年 3 月 7 日 我还是挺喜欢这种方式的。只要把价格打下来。如果云服务商杀红眼了,这种方式他们会千方百计的搞你。 |
 | 4 scyuns 2025 年 3 月 7 日 UI 不错 就是 CURL 失败了 |
 | 6 molezznet 2025 年 3 月 7 日 试了下,速度好慢 ………… 感觉是用 cpu …… |
 | 7 ccloving 2025 年 3 月 7 日 用了下,32B 好慢好慢好慢。 671b 不免费。 |
 | 8 cat9life 2025 年 3 月 7 日 免费只有两条归路:1. 为商业引流,完成使命后收费或者取消。2. 为爱发电,最终觉得委屈而关闭。 |
 | 10 nexmoe OP |
| 11 nexmoe OP 刚刚把 16G 显存以下节点撤了,只有下面几种显卡类型了。 NVIDIA GeForce RTX 4090 Laptop GPU NVIDIA GeForce RTX 4090 D NVIDIA GeForce RTX 4090 NVIDIA GeForce RTX 3090 Ti NVIDIA GeForce RTX 3090 NVIDIA only 4090 laptop |
 | 12 agood 2025 年 3 月 7 日 via iPhone 一眼就很皮包公司,世界、首个、免费、无限制…恨不得把所有极限词都用上 |
| 13 nexmoe OP @agood 但这就是客观事实啊,熬大夜通宵赶出来,那不就是抢快吗。 我们本质上做分布式平台的,世界上也确实没有把 QwQ 32B 跑在分散的家用电脑上的。 之前 DeepSeek 7B 就是完全免费,但是需要登录。现在 QwQ 32B 直接就是免费且没有限制,API KEY 都直接给出来了,登录注册都不需要。 |
 | 14 nolan1864 2025 年 3 月 7 日 via iPhone 数十万台网吧资源怎么搞的,而且网吧一般不都是 3060, 4070 的中端显卡么,显存就不太够吧,8G 的显存装了模型,就没多少分给 kvcache 了,性价比太低了。 |
 | 15 mkroen 2025 年 3 月 7 日 支持!另外提一嘴,算了么什么时候能支持 linux |
 | 16 1daydayde 2025 年 3 月 7 日 示例请求前面四行最后面少了 \ |
| 17 nexmoe OP @0312birdzhang 已优化 |
 | 18 Moyyyyyyyyyyye PRO 虽然但是,没响应过  |
 | 19 RiESA 2025 年 3 月 7 日 分布式算力网络:已接入超过一万台个人电脑和数十万台网吧的闲时算力资源 被接入的对方知情吗? 我的意思是这描述怎么看起来像肉鸡 |
 | 20 JZen 2025 年 3 月 7 日 赞一个,很巧的是今天上午我想起以前还在上学的时候玩过一个类似的事情,做了一个抠图的模型部署到服务器,但阿里云学生机算力不够,不能同时运行多个任务,于是又写了个 Python 脚本在终端运行(例如电脑、Linux 开发板),从服务器获取一个任务然后返回运算结果,最后发现网络带宽又不够用了。。。 |
 | 23 Psily1017 2025 年 3 月 7 日 有一点点慢,但是通过这个 api ,的确能实现不少想法 |
 | 25 whileFalse 2025 年 3 月 7 日 盈利模式是什么 |
 | 26 Amose2024 2025 年 3 月 7 日  |
| 27 Amose2024 2025 年 3 月 7 日  |
| 28 Amose2024 2025 年 3 月 7 日 代码中给了一分钟响应时间,除了反应慢,还挺好用 |
 | 29 snake9804 2025 年 3 月 7 日 via iPhone 不然去发币吧 |
 | 30 v1 2025 年 3 月 7 日 @whileFalse 网吧闲置机器挂机赚钱,和 pcdn 一样的业务模式,mini 矿机 |
 | 31 lloovve 2025 年 3 月 7 日 via iPhone 十万台就这个速度吗?还是就弄了一个显卡空手套?正常理解接入十万台,给这个 qwq100 台算力,也不至于这个速度啊 |
 | 32 lovestudykid 2025 年 3 月 7 日 QwQ BF16 原版 66G ,家用 GPU 都跑不了吧,官方 Q4 量化我体验性能还是差不少的,后面可能会有更好的量化版本 |
 | 33 lithiumii 2025 年 3 月 8 日 via Android petals 比你们早吧,而且是小显存的卡分布式部署大于单卡显存的模型。可惜免费节点已经没人跑了。 |
| 34 lovestudykid 2025 年 3 月 8 日 你们的 https://gongjiyun.com/ 这个网站是用用户机器挖矿还是跑 LLM ?一打开就疯狂占用 GPU ,卡得要死 |
| 35 nexmoe OP @Amose2024 #28 @lloovve 用户电脑质量参差不齐,我们还没有做好稳定性检测。目前提供了 50 个节点,有些节点质量还不错,有些节点质量比较差,可以看图。 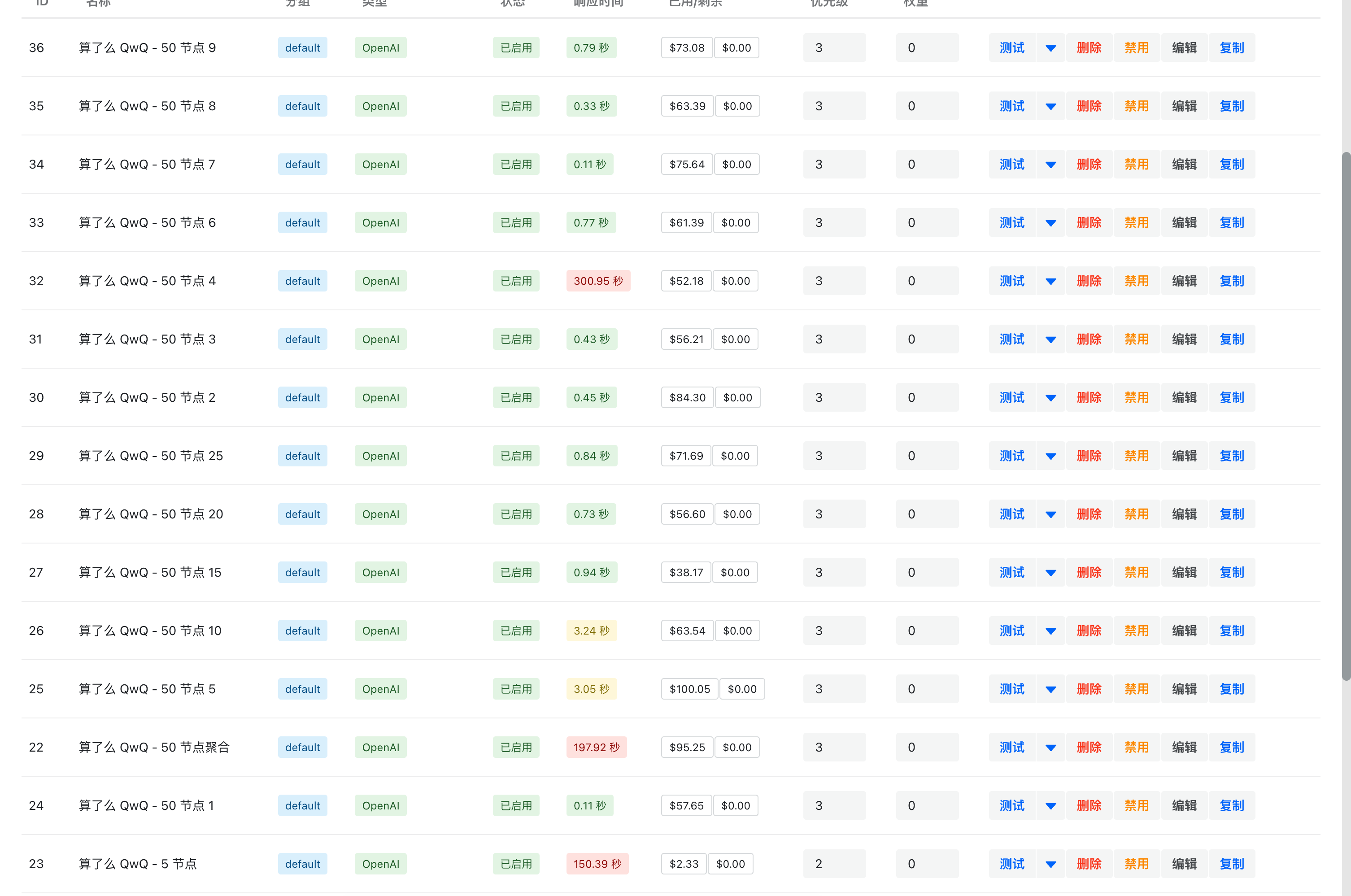 |
 | 36 root71370 2025 年 3 月 8 日 via Android 有点意思 |
| 37 root71370 2025 年 3 月 8 日 这是不是变相的挖矿啊 |
 | 38 jsutfun 2025 年 3 月 8 日 这个是真的慢呀 |
 | 39 wsc449 2025 年 3 月 8 日 llama runner process has terminated: error loading model: unable to allocate CUDA0 buffer llama_model_load_from_file_impl: failed to load model (type: api_error) |
| 40 nexmoe OP @lovestudykid #34 只有一些简单的动画,下周让前端优化一下 |
 | 41 Charon2050 2025 年 3 月 8 日 有没有考虑过提供一些非推理模型作为免费的选择?有很多时候用户的问题并不需要推理 |
| 42 nexmoe OP @Charon2050 怎么说,比如哪些模型 |
 | 43 ischanx 2025 年 3 月 10 日 共绩算力有新活了  |

 | 45 justlikemaki 2025 年 3 月 15 日 偶尔用用的话,不如用 huggingface 或者魔塔的 demo |