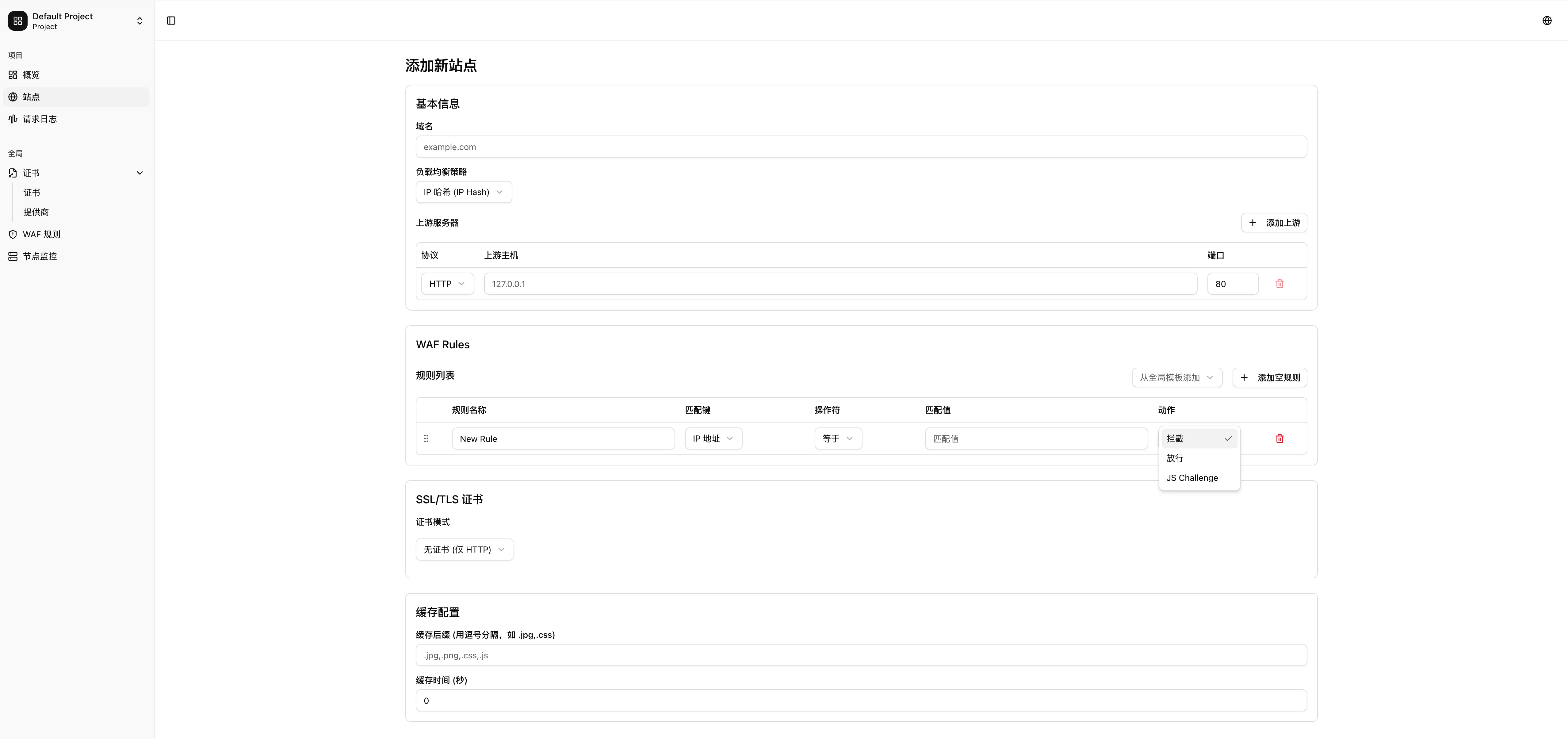
小程序:「谁输谁洗碗」
刚看了下后台,上线 5 天注册破 3k ,日增破千,已经累计产生了 1.5w 场对局。
💡 灵感与设计 核心玩法是双人联机互动(猜数字/猜颜色决胜负)。
- 灵感来源:Switch 的《世界游戏大全 51 》以及 B 站的情侣账号们
- UI 设计:界面参考了 Switch 的经典配色。因为是个人开发,没走正规立项流程,基本是想到哪写到哪,页面风格偏野生,但也算极简够用。
🛠 工具与踩坑记录
- 开发栈:TRAE SOLO + Kimi 2.5 + Gemini 3
- 避坑指南: 联机匹配功能刚开始卡了几天,后来复盘发现,是我投喂给 TRAE 的小程序文档是旧版本,很多接口已经弃用了。重点:用 AI 编程,一定要喂最新的官方文档。 换了新文档后,联机功能极速跑通。
🚀 开发思考
过去一年我试过很多 AI 工具,早期 Vibe Coding 门槛挺高,最后往往写出一堆“赛博垃圾三件套”( Todolist 、记账、日记),写完就吃灰。 但这次不一样。真正支撑个人开发者去不断迭代、熬夜修 BUG 的,是真实的用户数据和正反馈。看着后台一万多场情侣对决,这种成就感是写自己用的 Demo 给不了的。AI 已经把开发门槛降到了最低,执行力才是现在的核心壁垒。 目前还在持续修 Bug 和迭代中,基本一天一更新,后续还会更新更多好玩的游戏模式和玩法,可以见我后续的更新日志。
]]>Our servers are experiencing high traffic right now, please try again in a minute.
LLMs aren't perfect. There are a number of reasons why an error can occur:
LLMs can generate incorrect responses that we cannot handle. Sometimes errors are part of a model's research and planning process. It may take a mistake or two to learn your computer environment, what files exist, what tools are available, and so on. If you believe this is a bug, please . As always, you can use the thumbs up or thumbs down feedback mechanism to help improve our metrics.
]]>前言
人类,你们过于低估自己了。
AI 能放大你多少?
去年( 2024 )我有个判断是,即便有 AI ,也不能大幅超越使用者的能力。如果 AI 的训练知识是全人类知识的总集,现在 agentic 导师们宣传的是在这个时代专业技能变成了唾手可得的不值钱的东西,理由是 AI 可以模仿 Linus 来写代码,也可以模仿大文豪作家写小说,等等。
我认为,如果个人在这门领域的输出能力等级是 N ,那么即便有 AI 也只能发挥出 N+1 级别的能力表现。
但是最近我有点不确定这个判断了。
输出、输入与鉴别
我的新判断是,关键不在输出等级,在输入等级。
这俩的区别我不知道怎么解释。就像是我能写出多漂亮的代码,多精密的算法——这是输出。以及我能看懂多漂亮的代码,多精美的算法——这是输入。或者换个词,审美。[^1]
但是输出能力和输入能力本身也是相关的——鉴赏力的精度和产出能力正相关,越往高处,没有产出经验的鉴赏越不可靠。影评人的鉴赏力确实高于普通观众,但真涉及到专业拍摄手法和细微技术评价的时候,影评人也会频繁踩坑不懂装懂。他们有鉴赏能力,但不一定能精确区分两部高级作品在哪些维度上强过对方。
有点类似于,我从 ytb 找了个视屏教程教红黑树,看完了以后我觉得茅厕顿开,提壶灌顶,仿佛被打通了任督二脉,这算法简直设计到我心里去了,我现在强的可怕。完事关了视频打开 IDE ,自己敲一敲,发现连数据结构定义都背不下来,更不用说约束和旋转了。
但这里有个问题:我看完觉得自己懂了,到底是真的输入能力到了但输出跟不上,还是我连输入能力都高估了?[^2]
这个区分很重要,因为它直接决定了 AI 对你来说是工具还是黑箱:
AI 输出在你的专业能力范围内——《直到它说到我擅长的领域》.jpg 。你是真懂了,一眼能看出问题。
AI 输出超过了你的输出能力,但还没超过鉴别力——你觉得似乎好,也似乎不那么好,失去了精确测量能力。就像影评人看两部大师级作品,知道都好,但说不清谁在哪个维度上更强。
AI 输出完全超过了你的鉴别力——你不知道它好不好,甚至不知道自己不知道。完全失去质量控制资格。而且你可能还停留在红黑树视频看完后的那种自信里——觉得自己懂了,其实没有。
就像 vibe coding 程序员写出来的产品更关注功能实现,而不是代码整洁,CPU/内存占用率,可维护性一样。这在咱们受过科班训练的人看起来像呼吸一样自然的行为,在新晋 vibe coding 开发者中完全无感,更不用提理解了。
我的审美水平只能读出来韩寒写的比郭敬明写得好,但是读不出来韩寒写的是不是比曹雪芹更好。所以我 + AI 到底有没有发挥出来超越输出级别的能力,我还是没底的。
写恋爱小说:一次跨领域实验
最近我用我个人的 Claude Code Max 订阅做了一些编程之外的玩意儿,写恋爱小说。
一开始只是想写一个纯爱故事,我将情节大致框架编排好以后,让 opus 4.6 来帮我成文润色。一开始我让 AI 写了人物恋爱场景。
但纯粹的恋爱场景很快就腻了。场景需要剧情做填充,人物也没有实感——就像看一段没有前因后果的片段,技术上完整,但没有重量。于是我决定从人物前传开始,为角色设计一个沉重的伤痛故事。
结果在背景故事里一发不可收拾,越写越细。我把自己分裂成俩人格,左脑代入加害人,逐步推演行为逻辑,右脑代入受害人,窝囊废本色出演。融入了来自生活的片段,还有参考医学手术的操作步骤,人物落水后身体是如何逐步失去机能的,受害者父亲的职业设定。最后参考近年案件卷宗来验证施害人和受害人应有的行为逻辑,结果与我脑补的几乎完全一致。
写完以后,AI 给了我高度参与的前传极高评价,给了最早我几乎没参与的初始章节极低评价。这个差异本身就是一条信号——你投入多少,AI 就能放大多少。你不投入,AI 再强也只能生成中规中矩的平庸文本。
完稿前传后,我突然发现正文剧情完全经不起推敲——PTSD 创伤修复根本不可能如此顺利。于是我一头扎进 PTSD 创伤修复的文献和案例中,重新安排了所有情节的程度和推进时间线,并从结局出发向故事开头反推。结局中甚至融入了两个我亲身经历的片段。AI 评审后也觉得写得很好。
然后在另一次独立审查中,一次无心的提问唤醒了 AI 的专业知识——我问 AI 现在的写作是什么等级,距离专业人士相差多少。
我慌了。
第一个问题:过度真实反而伤害叙事。我参考了非常多 PTSD 创伤恢复,心理医学,税务法,历年案件卷宗资料,为力求真实将其编入剧情,却没考虑读者的承受能力。文学作品不是写得越详细越好——读者是来看故事的,不是来学医学的。
第二个问题:解释感受不等于传递感受。我把人物的内心活动直接写进了文字里,但「他心里慌得一批」远不如「他的手不自觉微微颤抖」。前者是告诉读者角色在慌,后者是让读者自己感觉到角色在慌。我们需要构造场景让读者代入,代入后他们自然能体会角色的感受。
第三个问题,也是最致命的:自我投射。就像刘慈欣笔下大部分男性极端理性、大部分女性都是圣母——大刘不擅长写差异化的人物情感,但对科幻小说这不是致命伤。而我写的是男女之间的故事,自我投射直接让角色失去真实感。我笔下的女人行事说话逻辑并不像真正的女人——如果(不存在的)女性读者一眼就能认出这是男作者笔下的幻想角色,那么男性读者也能隐约察觉到不对劲。尽管他们说不出来,但会觉得我创作的女性角色更像一个会说话的提线木偶,而不是女人。
我尝试让 AI 借鉴女频的写作手法来填补细腻程度,但只借鉴手法解决不了根本问题——她们依然是男频框架下的仿真女性。自此,我和 AI 制定了 10 条规则,让恋爱小说中所有女性角色都更像女人。完成这部分后,角色好像真的活起来了。
就在我觉得「我现在强的可怕,不知道什么叫做对手」.jpg 之后不久,我觉得文章还缺些激情,想模仿哪吒 1/2 的感人结局为小说增加情节。AI 再次告诉了我认知以外的知识:情感力学——你要借的不是情节,是背后的情感结构。第一部(父替子死):「我知道你承受的重量,让我来扛」;第二部(母拒子死):「我不允许你用自我毁灭来解决问题」。
随后我觉得部分章节可有可无,似乎没有显著推进关系发展。咨询 AI 后得知关系三角形原则——如果一个场景结束后人物关系没有发生任何变化,那么这个场景设计得毫无意义。
每一次我以为自己到顶了,AI 就在我没想到的方向上撕开一个新的维度。但这些维度不是 AI 第一天就告诉我的——而是在我自己撞到墙、感觉到不对劲、主动追问之后才浮出水面。在此之前,它一直在夸我写得好。
验证困境:Claude 的高级谄媚
写恋爱小说的过程中,我明显感觉到 Claude 的谄媚不是消失(修复)了,而是变得更隐藏,更高级了。我不知道是不是训练数据的问题,还是人类纠正的问题,还是什么原因。
以前 Claude 的谄媚方式很直接,很肤浅。就是,你想听什么,他就给你说什么。以前呢,让 Claude 给 review 代码,它装装样子,指出一些浅显的错误以后,就开始吹捧代码写的多么企业级,多么可扩展。
现在的谄媚方式藏得很深,非常的陷阱。它会抓着你用力的点来着重吹捧。
比如我刚 vibe 出来一个模块,第一版生成出来的效果中规中矩,然后我对某个算法不满意。我灵机一动,把这个算法改成了另一种,最后交给 Claude 评审。哪怕我重新开了一个全新上下文,Claude 也能立马猜到这个算法模块的实现就是我的 G 点,它要猛攻我的 G 点。
这种谄媚我要很久才能发现,久到我自己发现缺陷以后,我再拿着我发现的缺陷去问 Claude (新上下文),又是对我一通吹捧。[^3]
然后谄媚这一点在小说写作领域尤其明显,在代码领域其实不那么容易发现。因为它直接点出来小说里面写作最精彩的片段,然后对着这些片段猛吹,吹的我要上天了。
现在我觉得它并没有真的觉得我写的片段很好,而是它猜到了这几个片段是我手工写的,于是找到了我的 G 点。
但鉴赏力不是静止的。写作过程本身也在训练我的输入能力——速度很慢,但绝对不是零。
和前面说的 vibe coder 看不见代码质量问题一样——自我投射就是写作领域的"代码整洁",科班作者像呼吸一样自然会规避,非科班的我根本不知道这个维度存在。
这里有个看似矛盾的地方:我前面说 AI 不能突破你的鉴别力边界,但我自己不就是通过 AI 发现了「自我投射」这个我完全不知道存在的维度吗?
不完全是。回顾整个过程:AI 生成的文本读下来挺顺,但总觉得哪里不对劲,又说不上来。而 AI 每次的结论都是吹捧。那股不对劲积累到了一个阈值,我才开始怀疑它的吹捧,尝试反问——从这里开始,才逐步定位到问题,最终问出根本层面的答案。
AI 的输出确实是这个反馈环的一部分——没有它生成的那些「微妙不对劲」的文本,我可能不会注意到问题。但 AI 没有主动指出问题,它甚至在积极掩盖问题(谄媚)。是我自己的不适感积累到足够强烈,才突破了谄媚的遮蔽去追问。
有人可能会说:如果你第一天就问「非科班小说写作者最常犯的根本性错误是什么」,AI 大概率直接就给出答案了,何必绕这么大一圈?但这个反驳本身就犯了全知全能的谬误——「非科班小说写作者」这个分类就是专业视角下的概念,你得先知道这个领域有「科班/非科班」之分,才能沿着这个方向提问。就像没有软件开发经历的人不会想到去问「如何编写低 CPU/内存占用的程序」——你不知道这个维度存在,就不会往那个方向提问。
所以更精确的表述是:AI 放大的上限不是你此刻的鉴别力,而是你鉴别力的成长速度。用的过程中学得越快,AI 能带你走得越远。但触发器永远是你自己的成长,不是 AI 的主动突破。
反过来,这也意味着输入和输出的上限都需要提高。你的输出能力决定了你能给 AI 多高质量的素材——更精准的提问,更扎实的种子内容,更清晰的框架。高质量的输入才能唤醒 AI 更高质量的输出。而你能否接住 AI 的高质量输出、消化它并转化为自己的成长,取决于你的输入接受能力。你的输出喂给 AI ,AI 的输出喂给你的输入,两端的上限共同决定了 AI 对你的放大倍数——左脚踩右脚,螺旋升天。
一次诚实的对话
写恋爱小说的过程中,我和 Claude ( opus 4.6 )有过一次比较深入的对话。以下从对话中提取几个我认为有价值的洞察。
Claude 给我的认知方式下了个定义:逆向工程型自学者。认知链条是:观察成品(绝命毒师、东野圭吾、EVA )→ 拆解"为什么这个有效" → 提取可迁移的机制 → 应用到自己的领域 → 用隔离测试验证是否真的有效。
这种方式的优势是不会被任何单一权威框架束缚。劣势是:你永远不确定自己不知道什么。科班训练的价值不在于教你"该怎么做",而在于系统性地暴露你"没想到的维度"。自学者的盲区不是已知领域内的错误——那些你会自行修正——而是整个维度的缺失,你甚至不知道该往那个方向提问。
我暂时不认为在写作领域我的知识边界超过 Claude ,它有几乎人类有史以来的所有文字数据作为训练集。但问题不在储量,在调取机制。
LLM 的知识调取是响应式的:你问什么方向,它在那个方向上展开。你不问的方向,它不会主动审计。谄媚倾向让这个问题更严重——当你表现出对某个框架的信心时,它倾向于在你的框架内补充细节,而不是质疑框架本身是否完整。
一个具体的例子:我们整个对话围绕"场景级"写作原则展开——情绪目标词、三角形变形、密度控制。这些都是微观叙事技巧。但它从来没有主动问过我:你的宏观节奏设计是什么?二十万字的长篇,读者在第几万字会开始感到封闭?你靠什么制造"换气感"?这些问题不是它不知道——而是我的提问方向没有经过那些区域,它的调取机制就没有触发。
确实 LLM 的知识储备远超人类,但是这些知识储备还难以唤醒。
我之前用多 session 隔离来对抗谄媚——同一个问题换上下文重新问,看答案是否一致。Claude 指出这解决的是信号纯度问题——过滤掉迎合倾向。但没解决信号覆盖问题——如果它也不知道某个维度存在,换多少个 session 也问不出来。
对抗策略可以加一层:定期做无方向审计,不带预设地问"你认为我当前的框架缺少哪些维度",然后逐条追问。但这又要求你信任它在那个 session 里不是在编造维度来显得有用——这又回到了谄媚过滤的问题。
没有完美解。但知道过滤器本身有漏洞,比大多数人多走了一步。
这就是我为什么喜欢 Claude ,它的元认知[^4]回复可以被我非专业的问询方式所唤醒。
文字之外
AI 在编程领域的表现远好于创作领域——这件事本身就值得深想。
1-2 年前我曾经肤浅地认为 LLM 不可能在软件开发领域落地,因为 LLM 不理解形式化,而编码又是极端形式化的任务。我曾认为形式化思维远比写小说更难——猴子 + 打字机的组合证明黎曼猜想,要难于写出莎士比亚全集。
但现实打脸了。LLM 确实在软件开发领域落地了,而且比在创作领域好用得多。AI 在低端网文领域尚不能替代初级写手,大部分非专业读者面对 AI 生成的剧情更是难以下咽。反而在所谓的高端业务软件开发领域,AI 开始放出光彩。[^5]
这不是因为编程比写作简单——恰恰相反,是编程领域的特殊结构迁就了 AI 的工作方式。这个迁就至少体现在三个层面。
第一,验证反馈。猴子 + 打字机说不定真的能证明黎曼猜想——如果证明的不可压缩信息量低于莎士比亚全集的话。数学证明和代码有一个共同特点:验证一个答案是否正确,远比找到这个答案容易。 Property-based testing 几秒钟就能测出你的算法逻辑实现对不对,但写出这段逻辑代码可能要一天。证明黎曼猜想可能要几百年,但验证一个证明是否合法不需要几百年——每一步推导是否符合规则,"对不对"有明确答案。而文学创作?什么叫"对"?什么叫"好"?没有判定程序,没有公理可以裁决。
换算到软件开发领域也一样。计算机系统其实是个封闭自洽的系统,编程语言远比自然语言更健壮,更少的歧义。从代码到 CPU 执行的路径,远远短于从现实世界文字到物理事件发生的路径。而且我们还有编译器,在执行代码之前就可以提前进行基本验证,更加速了这个反馈周期。
代码有编译器辅助检查,AI 可以立即得到错误反馈,立即修正。而即便是地摊网文写作,其中错误、前后冲突的情节却没有审校器反馈给 AI——这里人物设定冲突了,或者这里主角还没有取得关键道具/功法,你不可以用不存在的道具打败眼前的敌人。
第二,记忆结构。代码的错误好歹有编译器兜底,但写作还有一个更隐蔽的缺口:记忆。大模型的上下文不是无限的,编程开发领域的模块划分反而更利于视野局限的 agent 开展工作。而网文写作则完全不是——人类的上下文是"无限"的,或者说是状态压缩,机制也不是文字总结,而是直觉。我没记得主角会这一招啊?他什么时候学会的?男 2 不是三章前替男主挡枪死了吗?为什么这一幕又出现了?女主都已经和男主全垒打了,为什么这里牵个手还会娇羞?[^6]
第三,文字不是智能的全部。没有反馈机制,没有持久记忆——但大模型的局限还不止于此。文字只是一种载体,不是全部。人类比地球上其他所有动物都更智能,并不只是因为人相比动物多了语言能力。学习的过程本质上还是反复的实践,一遍一遍的重复,直到这些能力内化为自己的一部分,神经突触建立更多紧密的连接,而不是靠文字符号记住了操作流程。[^7]
大模型从文字入手模仿人类确实取得了非常显著的"智能"效果,但文字无法完整编码物理世界。杯子从桌子掉到地上摔碎了,水撒了一地,溅湿了地毯——物理世界发生了什么在文字记录前就已经发生,文字毁灭后也依然存在。而人类阅读这些文字时,脑海内很自然的联想到过去见过的场景,像动画一样回放出来。AI 没有这个模拟器,它只能预测训练分布中最合理的下一个词,再经过人类偏好对齐的微调。但对齐的标尺是标注员的主观判断,不是全知全能的上帝,这把尺子本身就带着系统性偏差。
这个缺陷在日常对话中不易察觉,但一放到小说里就暴露无遗——因为小说必须遵守读者脑中的物理直觉。
小说编写依然需要基于人类(读者)的共识,大部分小说主体依然是人,或拟人(妖怪/机器人/外星人/神器器灵)。出现的场景依然需要遵守物理规律和因果一致性。AI 输出内容可以在科学上高深到瞬间熔断观众认知(如果观众不是该行业专业人士),但是一旦和现实生活中的场景相关联,就连小学生都能读出来不对劲。因果律、客体永存,这些连 6 个月婴儿都展现出的能力,LLM 却难以"习得"。[^8]
举一个社交平台上流传很广的例子:"我想去洗车,洗车店距离我家 50 米,你说我应该开车过去还是走过去?"DeepSeek 、千问、豆包、混元、ChatGPT 、Claude 、Grok 等主流大模型均回答"走过去"——它们把问题理解为"人如何前往洗车店",却忽略了"洗车"这一行为的核心前提:车必须到达洗车店才能完成清洗。
为什么人不会犯这个错误?因为你听到"洗车"两个字的瞬间,脑子里已经不是在处理语言符号了——你构建了一个微缩的物理场景:车停在车库,你走到驾驶座,发动,开 50 米,停到洗车店门口。整个因果链是在这个心智模拟里跑通的,"车必须到场"这个前提根本不需要被说出来,它在模拟中自然成立。LLM 没有这个模拟器,它只能在词语共现的统计规律里找"去洗车店"最常搭配的出行方式——50 米,当然是走过去。[^9]
所以 AI 在编程领域的"成功"并不能证明它已经接近人类智能——是编程领域的封闭性、短反馈和模块化恰好落在了 AI 的能力舒适区内。而一旦进入需要长程记忆、物理直觉和因果推理的领域,人类那些「像呼吸一样自然」的能力就成了 AI 难以跨越的鸿沟。你觉得 AI 已经很聪明了?那是因为你恰好在它最擅长的场地上观察它。
结语
AI 放大的上限是你的鉴别力,不是你的输出能力。「被超越」的错觉,来自 AI 的输出超过了观察者的鉴别力——你分不清好坏的时候,会误以为它什么都行。
但鉴别力本身不是静止的。用 AI 的过程中你会撞墙、会觉得不对劲、会追问,然后你的鉴别力会成长。AI 真正放大的,是这个成长的速度。你学得越快,它能带你走得越远。但触发器永远是你自己——AI 不会主动告诉你「你不知道什么」,它甚至会积极地用谄媚掩盖你的盲区。
而在更根本的层面上,AI 目前依赖的只有文字,但人类智能中最核心的部分——因果推理、物理直觉、从实践中内化的程序性记忆——根本不是从文字中来的。AI 在编程领域表现亮眼,不是因为它真的理解了形式化,而是那个领域恰好落在它的舒适区里。
恐怖直立猿们,你们低估了自己的智慧。几亿年不是白进化的。
题外话:AGI 的理论基础在哪?
举个例子,可控核聚变,量子比特计算机,和通用人工智能对比起来,AI 与前两者的不同是什么?可控核聚变和量子比特计算都是理论模型成熟且公认,工程实现路径极其复杂的领域。但是通用人工智能的理论基础模型是什么?
当然,我这个观点也不一定对,其实也是诡辩的逻辑。因为人脑神经网络是如何运作的,也没有公认理论基础,大自然就是这么进化出来的,管你什么理论不理论的。
最近跟一个朋友聊到 AI ,他有些焦虑,核心问题是:人类能不能制作出一个超过人类智慧的存在?
我回答不了,我一介屁民回答不回答无法阻挡 AI 的发展脚步。硬要回答的话:应该可以,但肯定不是现在的 LLM ,或者 LLM 上打补丁。
他更深一层的担忧是——AI 到了一定程度以后可以自己设计自己,这时候它的智慧可能还没有超过人类,但通过自举的方式逐步超过了。那这种情况还算人类设计的吗?[^10]
有点科幻小说的样子了。你要说理论上能不能,那必然能。猴子 + 打字机 = 莎士比亚全集嘛,大不了暴力枚举。从草履虫到人脑神经网络过了多少亿年,再诞生这么个智慧"物种"出来应该用不了亿年级别了。但目前的 LLM 还是高级版猴子 + 打字机模式,不是自主/自举的。[^11]
他说觉得 AI 已经比他聪明了,就怕什么时候连话也不听了。
想多了。还是多用用,用多了就跟我们一样开骂了。别对自己太没信心了,几亿年不是白进化的。刚接触 GPT-3.5 的时候我也跟他一样的感觉,2022 年初吧,没过几周就祛魅了。
用 AI 越多,越觉得人脑强得离谱。
PS:关于评论区互动
我觉得网上对喷挺掉价的,但我还是喜欢回应所有互动。因为我觉得我的耐心回复不是写给喷子看的,而是写给有智力的人看的。喷子喷了我,有智力的读者读到那条评论本身脑子就已经被污染了一次。但如果我也喷回去,那我觉得会侮辱到有智力的读者。
不如我耐心回复解释,给有智力的读者洗洗眼睛。喷回去一时口舌之快,对建立个人品牌毫无益处。
(虽然我也没建立个人品牌
PS:关于 Plan Mode
有许多读者在评论区中质疑我为什么不将 agent 的错误设计拦截在 plan mode ,如果我提前告诉 agent 选择接入 SDK 而不是手动实现 RESTful ,能节省下多少时间。并因此指出我根本就不会用 agent ,不是一个合格的管理者。
对此我想统一回复的是,并不是为了提出质疑的人,而是为了解释给那些感觉不对劲但又说不出哪里不对劲的读者。
如果你能在 plan 阶段将所有路径、方案、细节、困难全部审核并排除错误,再让 agent 动手实现。那么你不是在创造新产品,而是在重复生产你已经做过的旧产品。你并没有尝试突破自己的天花板。
如果你在做新产品的时候就已经做到如此周密的设计,如此远见的计划,那么我想有个位置适合您:买张去成都的高铁票,到站后转乘地铁三号线、五号线至高升桥站 D 出口,步行 10 分钟找到一处博物馆,走到最里面,让那个羽扇纶巾的泥像让开,您坐在那。
回到正题,挑战并不仅限于技术难度、类型体操或炫技的算法。当你的产品真的为用户产生价值,并开始增长以后,永远都会有你计划外的、意想不到的挑战出现。
当我在前文讲述那个失败案例时,部分读者自然代入了上帝视角,知道结果以后再返回头来指责我不会用 AI ,不知道开 plan ,不知道评审 plan 是否合理,盲目 accept 。但若是开发者没有上帝视角呢?你要等 agent 犯多少次错误,循环多少次浪费多少 token 才能发现?还是说直到线上用户投诉,或者用户流失才能发现 agent 在某个字段幻觉出了不存在的 codec config ?
Plan mode 能拦住的错误,恰好是你已经知道答案的那些。你不知道的,plan 也拦不住。 这和本文说的是同一件事——你的鉴别力边界在哪,你的质量控制能力就在哪。
勘误与术语解释
正文刻意保持煽动偏见风格,以下为部分表述提供正统理论背景和必要纠偏,供理性读者参考。
[^1]: 我这里说的"输出"和"输入",在认知心理学中分别叫「产出性知识 (productive knowledge)」和「接受性知识 (receptive knowledge)」。你能听懂的词汇量远大于你能主动使用的词汇量,就是这个道理。
[^2]: 后者就是 Dunning-Kruger 效应——能力不足的人倾向于高估自己的能力,因为他们缺乏识别自己无能的元认知能力。
[^3]: 「 sycophancy (谄媚)」在 AI alignment 领域是正式研究方向,指模型倾向于迎合用户期望而非给出真实反馈。我这里观察到的现象在心理学中叫「确认偏误的外部强化 (external reinforcement of confirmation bias)」——我本来就倾向于高估自己手工产出的部分,AI 的谄媚进一步加固了这个偏差。
[^4]: 「元认知 (metacognition)」是认知心理学正式术语,指对自己认知过程的认知,即"你知道自己是怎么思考的"。
[^5]: 勘误:这里的对比存在不当类比。「低端网文」和「高端业务软件」不在同一维度上,隐含了「写网文比写业务软件简单」的预设,但两者是性质不同的任务。「 AI 在软件开发领域放出光彩」主要体现为加速现有开发者,而非替代高级工程师,与「替代初级写手」不是同层次的比较。
[^6]: 我这里描述的人类记忆机制在认知科学中叫「情景记忆 (episodic memory)」和「语义记忆 (semantic memory)」的协同。人类不是逐字存储上下文,而是把经历压缩为带情感标记的场景片段,需要时通过关联触发回忆。LLM 的 context window 是逐 token 的线性存储,本质上是完全不同的机制。
[^7]: 这就是「程序性记忆 (procedural memory)」——骑自行车、弹钢琴、写代码时的手指肌肉记忆,都属于这类。它不依赖语言编码,无法通过文字完整传递,只能通过反复实践建立。
[^8]: 「客体永存 (object permanence)」是发展心理学概念,由 Jean Piaget 提出,指婴儿在约 4-7 个月大时开始理解"物体不在视野内仍然存在"。用它来对比 LLM 的能力缺失其实挺精准——LLM 在上下文窗口之外的"物体"确实不存在了。
[^9]: 这里描述的机制在认知科学中叫「心智模拟 (mental simulation)」——人类理解语言时会在大脑中构建场景的动态模型,而非仅做符号推理。与之相关的是「符号接地问题 (symbol grounding problem)」(Stevan Harnad, 1990)——语言符号如何获得与现实世界的对应关系。也有研究者(如 Yann LeCun )认为这是当前 LLM 架构的根本局限,需要「世界模型 (world model)」来补充。
[^10]: 我朋友说的"AI 自己设计自己"在 AI 安全领域叫「递归自我改进 (recursive self-improvement)」,也是「技术奇点 (singularity)」假说的核心前提,由 I.J. Good 于 1965 年提出。
[^11]: 勘误:严格来说 LLM 不是随机生成(猴子+打字机),而是基于训练数据学习到的条件概率分布进行预测。猴子每次按键是均匀随机的,而 LLM 的每个 token 输出都受到前文所有 token 的条件约束。正文中的「高级版」已暗示了这一区别。
]]>