因为很早以前就了解过 sd 、flux 、comfy ui 的复杂但精确的绘图,但是一直没有深入的学习。
也接触过豆包绘图、即梦、chatgpt4o 生图等“用嘴画图”。还有一些集成平台,比如哩布哩布。
之前有人说过没有一种画图方法比类似 sd 、flux 等精确提示词的画图方法好,因为他们一方面可以本地部署,隐私安全且可以生成自己想要的不用担心被拦截(比如涩涩),另一方面精确的指令可以精确画出画师心中理想的形象,而且还可以精细的改。这两条优势是没有其他渠道可以替代的。
但是随着 ai 画图技术的发展,似乎有人说用嘴改图会是未来的发展趋势,一定会替代 sd 等。
我对 ai 绘图很感兴趣,不知道想要实现辅助生成一些科研的插图或者示意图是否可以通过“用嘴画图”自然语言实现,还是说尽管现在自然语言画图蒸蒸日上但是还是有必要学习 sd 等精细画图?求大佬解答
]]>开源权重还有更大的吗
]]>我希望: 图生图中,输入:原图+衣服蒙版+衣服参考图。
有大佬了解这个吗?
]]>轻度试用 o 大佬们,请不要修改一些配置和重启 ui
轻度炼丹,佛佛佛。。
]]>为了拉点人头,每位邀请人和被邀请人都能获得 150 电量(电量是使用模型的基础)。
这是币圈的网站,积分每个赛季可以兑换成积分。不过现在可能晚了,主要是为了白嫖 GPT 。
]]>欢迎试用,反馈。(之前免费被黑客打了,产生了较高账单,这个加了限制,一个人每 1 分钟只能生成一张,看看能不能防护住哈哈)
]]>请问各位大佬有没有系统化的学习路线, 或者推荐的课程与讲师? 感谢!
]]>我的设想是:当服务器需要处理 AI 生成图片时,可以将计算任务转交给本地 PC ,生成完成后再将结果上传至服务器。想请教大家,这种方案是否可行
另外,如果使用 32G/64G 内存的 Mac 来处理 Stable Diffusion 生成任务,在生图性能上相比 PC 有优势吗?
感谢各位大佬的建议和指导!
]]>网址: https://flux1ai.net/ - FLUX.1 AI: Advanced Text-to-Image Generation Model
]]>离线 AI 图像生成安卓 APP 实际上有不少了:
但是由于单纯使用 CPU 的话,模型的推理速度是非常慢的。因此,我开发了一个能够调用高通 NPU 的图像生成安卓 APP ,能做到在生成 512x512 图像时在一秒左右完成一次迭代(生成一张图片至少需要 20 次迭代),支持以下的高通芯片:
6 Gen 1 、780G 、778G 、7 Gen 1 、7+ Gen 2 、7+ Gen 3 、888 、888+、8 Gen 1 、8+ Gen 1 、8 Gen 2 、8s Gen 3 、8 Gen 3
在 8Gen2 芯片上使用 20 步生成图像只需要 30 秒,8Gen3 甚至会更快一些,当然更精美的图像需要更多的步数。

欢迎 Star: https://github.com/tabelf/ai-gallery
有问题欢迎提出,进行交流!
]]>
保留生成参数:插件不仅同步您的画作,还会详细记录每次创作的生成参数。无论是色彩选择、纹理设置还是其他关键细节,所有信息都将完美保存,方便您日后回顾和再创作。
简化工作流程:不再需要手动上传和记录创作过程中的细节。我们的插件一键搞定,帮助您节省宝贵时间,将更多精力投入到艺术创作中。
支持多用户:我们的插件不仅支持个人用户,还提供强大的多用户管理功能,特设管理员权限便于团队管理和监督,通过数据汇总与分析轻松跟踪创作进度和优化资源分配。
随时访问:无论身处何地,只需登录您的账户,就能随时访问和下载所有创作作品和详细参数信息。
好了,简单介绍完毕,请您动动小手给个 star 吧。
]]>各位好,晚上睡前刚好看到有群友分享了一个 Hugginface 搭建的 Stable Diffusion 3 的在线体验工具,而且推荐采用 iframe 的方式,让大家可以快速上线 Stable Diffusion 3 的免费体验产品。所以灵机一动,马上注册了域名:stable-diffusion-3.online, 完成了一个免费的在线 Stable Diffusion 3 体验工具:Free Stable Diffusion 3 Online, 欢迎大家免费体验使用。
Free Stable Diffusion 3 Online 基于最新的 Stable Diffusion 3 模型,能够从文本提示生成高质量的图像。无论是复杂的空间关系、构图元素、动作还是风格,它都能准确理解并生成符合要求的图像。
该工具克服了手部和面部常见的伪影问题,生成高质量的图像,无需复杂的工作流程。
借助我们的 Diffusion Transformer 架构,Free Stable Diffusion 3 Online 在生成文本时达到了前所未有的效果,没有伪影和拼写错误。
由于其低显存占用,Free Stable Diffusion 3 Online 非常适合在标准消费者 GPU 上运行而不会性能下降。
它能够从小数据集中吸收细微的细节,非常适合定制化需求。
Free Stable Diffusion 3 Online 完全免费使用。您可以随时访问我们的在线平台,体验最先进的文本生成图像技术。
欢迎大家留言交流,希望这款产品可以给大家带来 Stable Diffusion 3 的乐趣。
]]>




不需要任何额外环境 /命令行 /浏览器,双击 app 把图片拖入即可
有任何建议或者使用问题请告诉我
前一段时间有许多内容创作者主动用不同语言撰写和制作介绍和推广相关的文章和视频,说真的我很震撼。最近主 repo 的 stars 也快 1k 了,十分感谢大家的支持。
我其实很好奇国内的正经 Stable Diffusion 社区究竟在哪儿,感觉我能找到的那些全都非常封闭,更新也不太及时。基本就是把外面东西搬运一下做个整合包写个教程之类的。而且材料也都是 A1111 相关的,很少有 ComfyUI 这些的相关的东西。如果有群或者社区平台请务必告诉我,非常感谢。
前几个版本都没有在 V2EX 发主要是因为中文用户比较少,加上没有添加特别重要的新功能。具体的 changelog 可以看release (虽然没写中文版)
另外,大家可能不太相信,但这个 GUI 确实是 Tkinter 写的,为了能做到这个美观度我真的废了好大的劲。主要用了 CustomTkinter ,部分模块自己魔改了一下。配色用的是苹果的 guideline ,功能图标是谷歌的 Material Symbols ,app 图标是用 SD 生成的。至于为什么不用 Qt 写,qml 在我的 Mac 上会有迷之 bug ,而且几个打包工具作者对 PySide 的支持比较迟缓 (提的 issue 等我用 Tkinter 写完之后全修复了..感觉自己像个怨种)。有兴趣的话可以看一下代码,但是个人强烈建议千万别用 Tkinter 写任何东西,里面全是坑。

| 格式 | PNG | JPEG | WEBP | TXT* |
|---|---|---|---|---|
| A1111's webUI | ✅ | ✅ | ✅ | ✅ |
| Easy Diffusion | ✅ | ✅ | ✅ | |
| StableSwarmUI* | ✅ | ✅ | ||
| StableSwarmUI (0.5.8-alpha 之前的版本)* | ✅ | ✅ | ||
| Fooocus-MRE* | ✅ | ✅ | ||
| NovelAI (stealth pnginfo) | ✅ | ✅ | ||
| NovelAI (旧版) | ✅ | |||
| InvokeAI | ✅ | |||
| InvokeAI (2.3.5-post.2 之前的版本) | ✅ | |||
| InvokeAI (1.15 之前的版本) | ✅ | |||
| ComfyUI* | ✅ | |||
| Draw Things | ✅ | |||
| Naifu(4chan) | ✅ |
* 见格式限制.
如果你使用的工具或格式不在这个列表中, 请帮助我支持你的格式: 将你的工具生成的原始图片文件上传到 issues, 谢谢.
对于 ComfyUI 用户,SD Prompt Reader 现在可作为 ComfyUI 节点使用。 ComfyUI Prompt Reader Node 是本项目的一个子项目,建议在你的工作流程中嵌入其中的 Prompt Saver node 以确保最大的兼容性。
从 GitHub Releases 下载可执行文件
从 GitHub Releases 下载可执行文件
你也可以通过 Homebrew cask 安装 SD Prompt Reader.
brew install --no-quarantine receyuki/sd-prompt-reader/sd-prompt-reader 使用 --no-quarantine 参数是因为目前 SD Prompt Reader 并未签名, 具体原因请查看这里




这是 SD Prompt Reader 的一个子项目。它帮助你从 SD Prompt Reader 支持的任何格式的图像中提取元数据,并保存带有额外元数据的图像,以确保与 Civitai 等网站上的元数据检测兼容。

在 ComfyUI Manager 中搜索 SD Prompt Reader 并安装。
请确保在安装主库的同时安装子模块。
cd 到 custom_node 文件夹git clone --recursive https://github.com/receyuki/comfyui-prompt-reader-node.git cd comfyui-prompt-reader-node pip install -r requirements.txt  ]]>
]]>于是我就在想: 有没有小白都能上手使用的 Stable Diffusion 在线生成器,尤其支持图生图,像素高。我们愿意付费
]]>坐标深圳宝安,预算 6.5K ,不带显示器;可以自提,有兄弟只有板 U ,显卡(显存越大越好)单出的话,也可以跟我联系;
张小龙:Y2hhdmluMTk5Mg==
]]>主要是设计,ps ,ai ,和 stable diffusion
要求:
显卡:不知道,想尽量多点预算给显卡
内存:32g
硬盘:1t
其他的都不懂。。。
]]>
前端:NextJS 14 App Router + Tailwind CSS 部署:Vercel
注:本来用 clerk 做了登录功能,结果上线后提交到 Google search console 一直提示 401 ,还没找到原因
第一次在 V 站发帖,环境大家体验网站和提意见。关于 cleark 的 401 问题。如果有用过的大佬请留言,虚心请教,谢谢!
]]>本地生成的图片版权算不算我的呢?
求助各位大佬
]]>联系 V:bHZsaW54aWFvMjAyMw==
]]>stable-fast 是一个为 HuggingFace Diffusers 在 NVIDIA GPUs 上的超轻量级推理优化库。 stable-fast 通过利用一些关键技术和特性提供超快的推理优化:
stable-fast 为各种组合的 Conv + Bias + Add + Act 计算模式实现了一系列功能齐全且完全兼容的 CUDNN 卷积融合运算符。stable-fast 实现了一系列使用 fp16 精度的融合 GEMM 运算符,这比 PyTorch 的默认设置更快(以 fp16 读取和写入,以 fp32 计算)。stable-fast 使用 OpenAI 的triton实现了高度优化的融合的 NHWC GroupNorm + GELU 运算符,消除了内存格式排列运算符的需要。stable-fast 改进了 torch.jit.trace 接口,使其更适合追踪复杂模型。几乎每一部分的 StableDiffusionPipeline 都可以被追踪并转换为 __TorchScript__。它比 torch.compile 更稳定,并且比 torch.compile 的 CPU 开销明显小,并支持 ControlNet 和 __LoRA__。stable-fast 可以将 UNet 结构捕获到 CUDA Graph 格式,当批量大小小时可以减少 CPU 开销。stable-fast 仅仅直接使用 xformers 并使其与 TorchScript 兼容。stable-fast 是专门为 HuggingFace Diffusers 优化的。它在所有库中都实现了最佳性能。stable-fast 作为 PyTorch 的一个插件框架工作。它利用现有的 PyTorch 功能和基础设施,并与其他加速技术兼容,以及流行的微调技术和部署解决方案。| 框架 | 性能 |
|---|---|
| Vanilla PyTorch | 23 it/s |
| AITemplate | 44 it/s |
| TensorRT | 52 it/s |
| OneFlow | 55 it/s |
| Stable Fast (与 xformers & triton 共同工作) | 60 it/s |
| 框架 | 性能 |
|---|---|
| Vanilla PyTorch | 16 it/s |
| AITemplate | 31 it/s |
| TensorRT | 33 it/s |
| OneFlow | 39 it/s |
| Stable Fast (与 xformers & triton 共同工作) | 38 it/s |
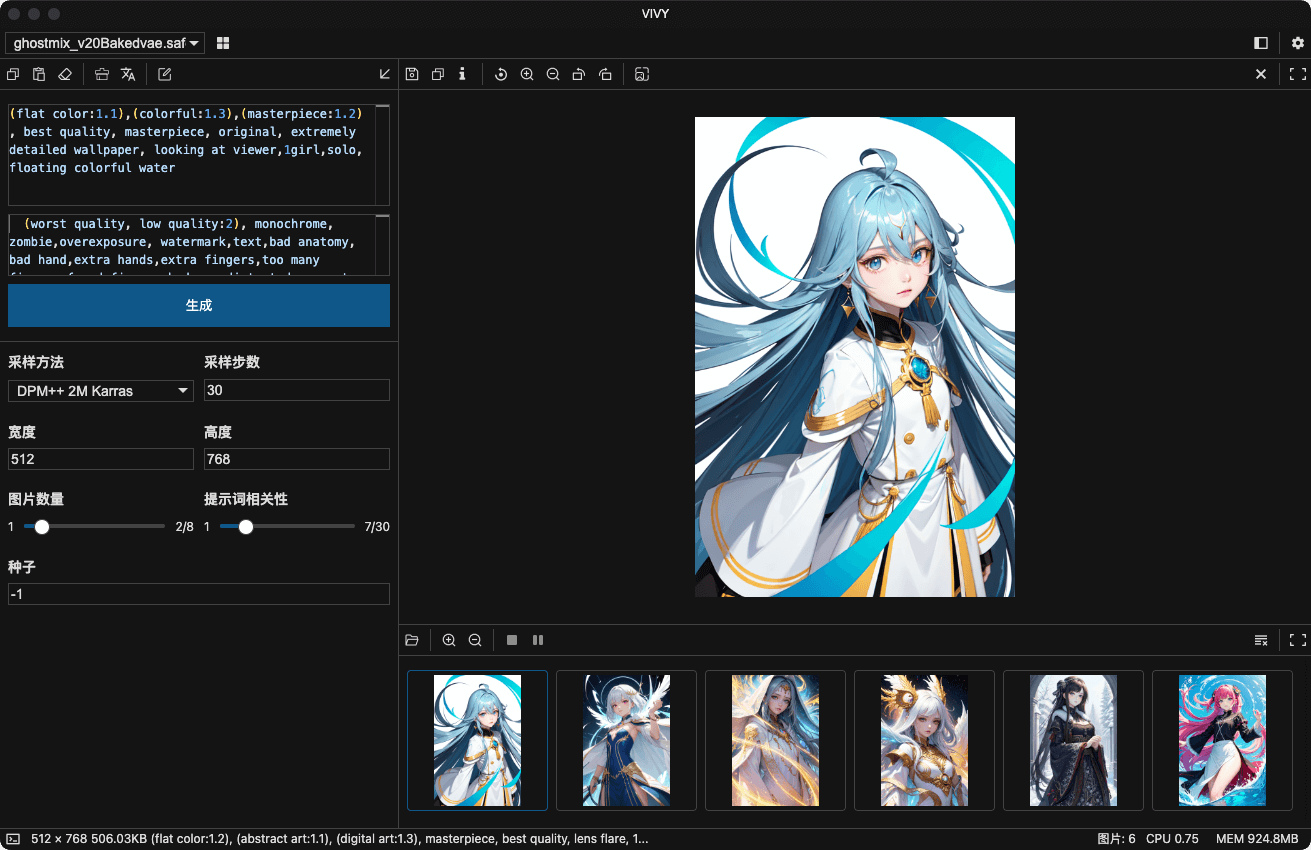
目前只支持文生图,功能还比较基础,有兴趣的可以下载试用看看,支持 mac arm 和 windows x64 ,如果有任何建议或者使用问题可以直接在仓库中反馈。
https://github.com/liriliri/vivy-docs
特性:
应用界面: