
反思了一下也许是因为懒 - 需要搜索的时候习惯无脑 fzf ;没法 fzf 的时候能 glob 就 glob ,再不行就 if else 。。。
今天突然发现终端程序less不能用 glob ,而less这个程序又很好用且哪里都有,无形中给使用者多了一点动力学正则。
大家还有什么时候很需要正则呢。
]]>之前是可以正常识别的,现在不知为何识别不了了。
目前的状态是,第一次匹配是正常的,第二或以上次匹配,会由上一段段尾的空白处开始标注至本段的文本结尾处。
问了 GPT 说是我的设置有问题,但 sigil 并没有相关正则表达式的设置。且给了正确的匹配表达式。
个人分析可能的原因是,之前我是 txt 文本复制到的 sigil 现在是 pages 的文本复制到的 sigil
求指教异常的原因,及方案
另外求个 sigil 搜索模板配制的文件位置 ]]>
只保留 中文与中文 数字和数字 英文和英文 英文和数字 数字和英文之间的空格
其余空格全部去掉,,这种正则应该怎么写 ]]>
<!--#region REMOVE--> <h1>sdfsdf</h1> <h2>sdfsdf</h2> <h1>sdfsdf</h1> <h2>sdfsdf</h2> <h1>sdfsdf</h1> <h2>sdfsdf</h2> <!--#endregion REMOVE--> 正则:
^\<\!\-\-\#region REMOVE.*[.|\n|\W|\w]*^\<\!\-\-\#endregion REMOVE.*$ 哪位好心人帮忙看看 多谢多谢!!
]]>const keywords = [Stop,.............]
monaco.languages.register({ id: "mySpecialLanguage" }); monaco.languages.setMonarchTokensProvider("mySpecialLanguage", { tokenizer: { root: [ [/(?<!\w)Stop(?!\w)/, 'keyword'] ], }, }); monaco.editor.defineTheme("myCoolTheme", { base: "vs", inherit: false, rules: [ { token: 'keyword', foreground: 'f1d710' }, ], colors: { "editor.foreground": "#000000", }, }); monaco.editor.create(document.getElementById("container"), { theme: "myCoolTheme", value: `Stop QdStop qdStop 11Stop StopSS Stop11 Stopdd `, language: "mySpecialLanguage", }); 我期望将 keywords 中的所有单词高亮显示,列表中包含 Stop,但以 Stop 结尾的单词仍会高亮显示
Stop 开头的效果是正确的,但是 Stop 结尾的效果是错误的,应该显示为黑色,而不是黄色
如何将其突出显示为仅用于停用词的关键字,如果前后有字母或单词,则不应突出显示

[ A ] 转发量 [] 5%
[ A ] 评论量 [] 4%
[ A ] 指数 [] 5%
如上面例所示。EM 正则怎么删掉第一行的 [ A ] ,删除之后,在最前面添加一段话:本研究案例参照前文所示。
最终效果如:
本研究案例参照前文所示。
非负信息总量 [] 5%
[ A ] 点赞量 [] 5%
[ A ] 转发量 [] 5%
[ A ] 评论量 [] 4%
[ A ] 指数 [] 5% ]]>
有一段 html 文本,内容是物理或者化学题。
类似于下面这样
实验室用固体 NaOH 配制 250mL1.00mol/L 的 NaOH 溶液。请回答下列问题: ( 1 )配制该溶液需称取 NaOH 固体.................(省略) ( 2 )配制上述溶液时正确的操作顺序是 .................(省略) ( 3 )以下情况会导致所配溶液浓度偏低的是 ( 4 )通入一定量的 CO .................(省略) ..................... ( n )所加盐酸的浓度为 想通过正则进行匹配切割成数组,匹配规则是括号+数字,下方
( 1 )( 2 )( 3 )( 4 ).....................( n )
然后剩下的就是对数组中的每个元素单独做业务上的处理
]]>- Chrome=122.0.6261.69
- Nodejs=v10.19.0
- PHP 7.4.3-4ubuntu2.20 (cli) (built: Feb 21 2024 13:54:34) ( NTS )
- Python 3.8.10
- go version go1.13.8 linux/amd64
(不要吐槽和讨论版本,除非你确定这玩意在新版本上没问题,生产环境随便找台机器测的)
-1 这玩意哪来的?
这玩意是我们前端同学问 GPT ,如何写一个匹配网址的正则问到的。
(/^( https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/).test('https://foo.com/a-long-url-contains-path-and-query-and-anchor/foo/bar/baz?boo=baa#anchor'); *** (这个真的可以执行,建议新窗口 F12 试下) ***
于是,真的匹配一段文本的时候,就导致浏览器卡死了,无法做后续渲染,在 profiling 的时候查到是这个正则的问题。
0 MVP 测一下
function testRegexPerformance(repeatCount) { var testString = 'a'.repeat(repeatCount) + '#'; var regex = /(\w*)*$/; var startTime = process.hrtime(); var result = regex.test(testString); var endTime = process.hrtime(startTime); var executiOnTime= endTime[0] * 1000 + endTime[1] / 1000000; console.log("Repeat Count:", repeatCount); console.log("Execution Time:", executionTime + " milliseconds"); console.log("-----------------------------------" + result); } // 测试从 1 到 50 的重复次数 for (var i = 1; i <= 50; i++) { testRegexPerformance(i); } Repeat Count: 20 Execution Time: 35.191223 milliseconds -----------------------------------true Repeat Count: 21 Execution Time: 71.355698 milliseconds -----------------------------------true Repeat Count: 22 Execution Time: 140.852157 milliseconds -----------------------------------true Repeat Count: 23 Execution Time: 287.687666 milliseconds -----------------------------------true Repeat Count: 24 Execution Time: 577.368917 milliseconds -----------------------------------true Repeat Count: 25 Execution Time: 1148.243059 milliseconds -----------------------------------true Repeat Count: 26 Execution Time: 2297.804939 milliseconds 在i=25的时候,执行时间就到了秒级,之后都是指数级增长。
1 结果是 true 是符合预期的
*表示 0 个或者多个,没有任何一个\w 也是没问题的
2 Regexp.test vs String.match
# 不匹配 > 'a'.match(/(b)/) null # 匹配 > 'a'.match(/(b)/) null # 匹配 > 'aa'.match(/(a)/) [ 'a', 'a', index: 0, input: 'aa', groups: undefined ] # 不那么匹配 > 'aaa#'.match(/(\w*)*$/) [ '', undefined, index: 4, input: 'aaa#', groups: undefined ] # 匹配? > /(\w*)*$/.test('aaa#') true > 起因是我旁边的同学说.net 没有 test ,只有 match ,而且结果是 false
所以,js 里面如果用 match 试下,大概有三种结果:
- 匹配:test=true
- 不匹配:test=false
- 不太匹配:test=true ,但是 match[0]是空,1 是
undefined
3 其他语言的表现?
-
js:匹配,衰减
-
PHP: 不匹配,不衰减
-
Python:None(不匹配),衰减
-
Go: 匹配,不衰减
-
F#: 匹配,衰减
4 所以是为啥?
二楼放测试程序,不占地儿了
]]>mark123 test test test test test test mark123 test mark123 mark123 mark123 test test mark123 mark123 删除编辑 mark123 之前的回车,当然 test 是随机字符,但 mark123 是确定的
mark123testtesttesttesttesttest mark123test mark123 mark123 mark123testtest mark123 mark123 感谢
]]>将
第一行 第二行 转换为
<p>第一行</p> <p></br></p> <p>第二行</p> 本人对正则表达式不太了解,特来 V 站问问万能的 V 友们。
不求最优解,有思路就好。
]]>... abc.js: actual output: { "loc": { "start": { "line": 1, }, "end": { "line": 1, } } } Error: xxxx abc.js: actual error: ... abc.js 不是固定内容(可能有 xxx.js 等),
abc.js 的数量不止一对,
actual output 和 actual error 是固定存在内容的有且仅有一对。
保留 abc.js 信息。
需要匹配多组
]]>效果前
〖 BH 〗 AAA 〖〗〖〗〖〗〖〗 0.020 〖〗-0.017
〖 BH 〗〖〗〖〗〖〗〖〗(0.027)〖〗(0.015)
〖 BH 〗 BBB 〖〗〖〗〖〗〖〗-0.225**〖〗 0.018**
〖 BH 〗〖〗〖〗〖〗〖〗(0.113)〖〗(0.009)
〖 BH 〗 CCC 〖〗-1.087***〖〗 0.413***〖〗〖〗-0.966***〖〗 1.033***
〖 BH 〗〖〗(0.147)〖〗(0.081)〖〗〖〗(0.175)〖〗(0.323)
效果后
〖 BH 〗 AAA 〖〗〖〗〖〗〖〗 0.020(0.027)〖〗-0.017(0.015)
〖 BH 〗 BBB 〖〗〖〗〖〗〖〗-0.225**(0.113)〖〗 0.018**(0.009)
〖 BH 〗 CCC 〖〗-1.087***(0.147)〖〗 0.413***(0.081)〖〗〖〗-0.966***(0.175)〖〗 1.033***(0.323) ]]>
问过 gpt ,给不出答案。 ]]>
[.characters.]
Within a bracket expression (written using [ and ]), matches the sequence of characters of that collating element.
mysql> SELECT '~' REGEXP '[[.~.]]'; -> 1 为啥不是单[?结果也是 1 呀 mysql> SELECT '~' REGEXP '[.~.]'; [=character_class=]
Within a bracket expression (written using [ and ]), [=character_class=] represents an equivalence class.
里面没举例,可否写个例子?
[:character_class:]
Within a bracket expression (written using [ and ]), [:character_class:] represents a character class that matches all characters belonging to that class.
mysql> SELECT 'justalnums' REGEXP '[[:alnum:]]+'; -> 1 为啥不是单[?结果也是 1 呀 mysql> SELECT 'justalnums' REGEXP '[:alnum:]+'; [[:<:]], [[:>:]]
These markers stand for word boundaries. They match the beginning and end of words, respectively.
怎么需要 2 个来分别表示?
]]>忽略前面的各种括号国籍(包括括号,引号,〖 JP2 〗等,),有方法能实验吗?
]]>- 想要一块代码中抽取出 函数返回值, 函数名 函数类型,用来编出 main 函数
想要的功能,这能用正则做吗?
- 可以匹配 c++函数的 返回值类型、函数名、参数类型列表
- 返回值类型、参数类型会有:
- 类型 1:
- int
- char
- string
- TreeNode *
- Node *
- vector<类型 1>
- vector<类型 1> &
- vector<vector<类型 1>>
- vector<vector<类型 1>> &
- 类型 1:
问了 OpenAI 感觉不太对,每次问结果都不一样
Here's a regular expression that matches the return value type, function name, and parameter type in C++: (int|vector<int>|vector<vector<int>>|string|vector<string>|vector<vector<string>>|ListNode\*|vector<ListNode\*>|char|vector<char>|vector<vector<char>>|TreeNode\*|Node\*)\s(\w+)\((.*)\) The regular expression uses the following components: (int|vector<int>|vector<vector<int>>|string|vector<string>|vector<vector<string>>|ListNode\*|vector<ListNode\*>|char|vector<char>|vector<vector<char>>|TreeNode\*|Node\*) matches the return value type, which can be one of the specified types. \s matches a whitespace character. (\w+) matches the function name, which is one or more word characters. \(.*\) matches the parameter list, which is zero or more characters enclosed in parentheses. 举个例子
vector<int> f(vector<int>& a, TreeNode *b, int d){ } - 提取类型为了初始化
vector<int> arg1 = {}; TreeNode * arg2 = new TreeNode(xxx); int arg3 = 0; vector<int> result = f(arg1, arg2, arg3); 如果不能做,那只能写代码硬匹配了?
]]>@ 符号 @any => true
xxx @any => true
xxx@any => false
* 表名有单词字母.和_
* 目前写法:`const fromTable = lowerSql.match(new RegExp('\\b(from)\\b[\\s\\S]*?\\s+([\\w._]+)\\', "gi")) || []`
但 safari 不兼容零宽断言 ]]>
Invalid regular expression,看了一下原因是 Safari 不支持向后匹配 ((?<!),见 can i use 如下是我的正则:
/(?<!\/.*?)showLineNumbers(?:\{(\d+)})?/ 期望的效果如图:
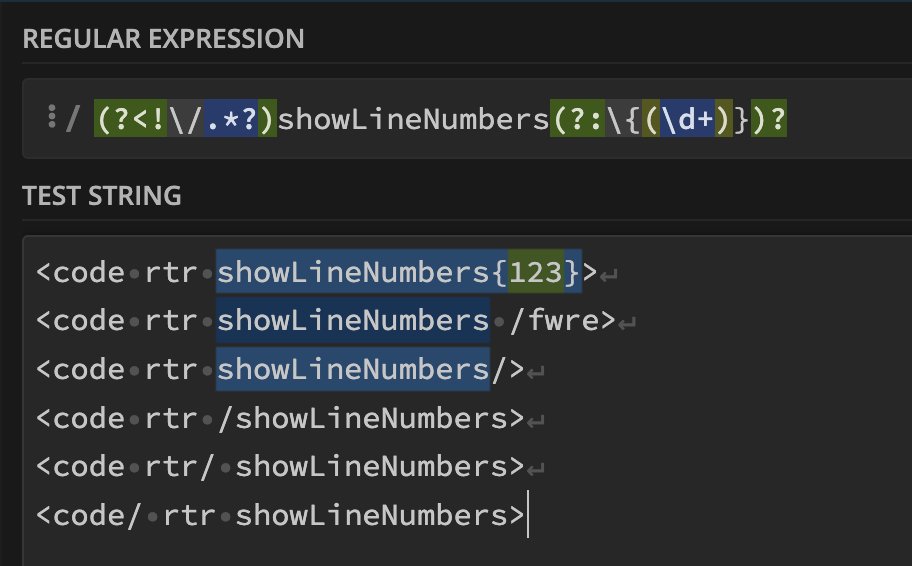
求一个不使用向后匹配表达式((?<!)的替代方法 🙏
PS. 这个正则工具挺好用的: https://regex101.com
]]>a = 'abc[账号]def[密码]xyz' b = 'aaa[账号]还有"子字符串[无效内容]子字符串"bbb[密码]zzz' 我想提取所有中括号里面的内容,但忽略双引号内部的中括号中的内容。
以上面两个字符串 a 和 b 为例,需要提取的内容都是『账号』和『密码』
目前我能想到的办法是使用状态机来做。请问有没有使用正则表达式就能实现的方法?
]]> rewrite ^(.*)$ https://$host$1 permanent; 但是出现了循环重定向
因为用的是 xinnet 的虚拟主机,rewrite 不能指定写在 80 端口下,所以导致 https 也重定向
哪位大佬能帮忙写一个,判断 scheme 是 http://时,重定向到 https://
]]><!DOCTYPE html> <html> <body> <h2>xxx</h2> </body> <script> function myFunction() { token = "xxxxxxxx" } </script> </html> 名字取得也很有意思。
]]><html> <p> Have a/ good/ day! 祝你 /开心! </p> </html> 我想要把在
之间的 /去掉,变成<html> <p> Have a good day! 祝你开心! </p> </html> 请问该通过正则表达如何实现?
]]>效果如 100 cm 200 kg 5 GB/s 100 t 200 M
求个安全的正则。。 ]]>
我想只替换没有被标签包裹的 target ,如果被标签包裹则忽略,应该怎么匹配啊,感谢感谢。 ]]>
问题如下:
待匹配字符串:ABCD
我的正则:(?>AB|BC)D
按照我的理解我的正则应该不能匹配给定的字符串 ABCD 。但实际情况是匹配到了 BCD 。 我的理解是:先匹配 |的左边 pattern: AB, 在字符串里面匹配到了 AB 。继续前进匹配 D,匹配失败,字符串里面没有 ABD, 此时应当 backtrack, 使用 |的右边 pattern: BC。但问题在于,我使用了 atomic group ,而且此时的位置已经超出了 atomic group ,所以应当是不能 backtrack 的。所以整个正则应当匹配失败。 但测试结果证明我理解错了。
所以请教一下大家为什么会这样,谢谢。 正则引擎:Boost 1.76.0
]]>例如 0.001 、9999 、-1.010 、01.32 不合法 99.99 、0 、-1.2 合法
]]>比如 9.2 改成 9.20 8.50 18.50
这个在 eme 或 eeditplus 正则该怎么写
查找什么 替换什么 ]]>
abc 组成的字符串 str = "abcaada2abcbfb3abccdsc4abcddd5" 想要匹配 abc 和 4 及之间的字符:
abccdsc4 使用 abc 和 4 作为定位符,结果
>>> print(re.search('abc.*?4', str)) <re.Match object; span=(0, 23), match='abcaada2abcbfb3abccdsc4'> 请教一下大家,该如何实现需求?感激
]]> //匹配后面字符不为 10 的 win var str = "win7 win8 win10"; var res = str.match(/win(?!10)/g); console.log(res); //["win", "win"] 在以下文本中
-0"][-ext-cOntains="/欧美(.*?)极乐天堂 /"],tbody[-ext-cOntains="/欧美(.*?)极乐天堂 /"] -0"][-ext-cOntains="/欧美(.*?)自由通行证 /"],tbody[-ext-cOntains="/欧美(.*?)自由通行证 /"] -0"][-ext-cOntains="/欧美(.*?)陶醉的芬香 /"],tbody[-ext-cOntains="/欧美(.*?)陶醉的芬香 /"] -0"][-ext-cOntains="/史上最贵 RPG:命中注定的召唤术(.*?)1.17/"] -0"][-ext-cOntains="/欧美(.*?)身心荡漾 /"] -0"][-ext-cOntains="/欧美(.*?)恶女管教所 /"] 使用d\-0\"\]\[\-ext\-contains\=\"(.*?)\"\](?!\,) 或 d\-0\"\]\[\-ext\-contains\=\"(.*?)\"\](?!,)
只能匹配-0"][-ext-cOntains="/欧美(.*?)极乐天堂 /"],tbody[-ext-cOntains="/欧美(.*?)极乐天堂 /"]
无法匹配-0"][-ext-cOntains="/欧美(.*?)身心荡漾 /"]这种不带","标点的字符串
编写的正向否定环视哪里出问题了
]]>只保留英文和数字,数字和数字,英文和英文之间原有的空格。
其他的空格全部替换掉,包括标点符号之间的空格也替换掉。
懂正则的朋友麻烦给我看看能否行的通。谢谢
]]>正则验证数字,并且最多保留 2 位小数。
实现
const regExp1 = /^(-)?\d+(?:.\d{1,2})?$/ const regExp2 = /^(-)?\d+(.\d{1,2})?$/ 测试
// assume the value is: // 1,1.1 regExp1.test(value:number) regExp2.test(value:number) 测试发现,value 的结果都一样,请请教下大家,该如何理解?:的作用,不胜感激~
]]>(?=(?:\d{3}) 可以匹配到 "333" 前面的空字串 ""
(?=(?:\d{3})+ 一到多个 但匹配里的 $ 号,或者有些人写的 (?!\b) 是啥意思呢
'8123456789'.replace(/\B(?=(?:\d{3})+$)/g,',') // 8,123,456,789 "8123456789".replace(/\B(?=(?:\d{3})+(?!\d))/g,",") // 8,123,456,789 为什么不能写成
'8123456789'.replace(/\B(?=(?:\d{3}))+$/g,',') // '8123456789' 期望把“574”提取出来。 ]]>
我想要的结果 求个正则 const s = '/hello' // match[1] = hello const s = '/hello/abcd' // match[1] = hello // match[2] = /abcd const s = '/hello/' // match[1] = hello // match[2] = / console.log(s.match(/\/([^\/]+)?(.+)/i)) ]]>const regKey: string = /^google-(.+){10,}-name$/; const name1: string = "google-15922231201-name"; const name2: string = "google-dbid%3AAACd8VcY240_OYIPqr4L-8M6RvNEDErLG1s-name"; const matches1 = name1.match(regKey); const matches2 = name2.match(regKey); 在这里,matches1[1],是能够拿到 "15922231201",但是,matches2[1],却拿不到中间的那一长串字符串。返回值是 "s",只有一个 s......
我在 https://regex101.com/ 这里试过,引擎选 Javascript,这两字符串,都是符合要求的。
请问一下,这里的 reg 哪里写的不对。
另,我知道可以直接用 substring + 长度,直接拿到 google- & -name 匹配的中间的字符串,但这里,我想了解下,这个正则是哪里写得不对了?
]]>当前规则是 6-20 位,大写字母,小写字母,数字和标点符号(除空格)满足两种即可。
如果我想改造这个正则,分别判断满足一种,二种,三种,四种应该怎么改写,正则不会写,拜谢大佬们了
]]>RegionInfoMessage `json:"RefreshAfter"` 需要匹配
开头:
json:" 结尾:
" 内的单词的大写
即匹配结果为
R A 我只知道这样
(?<=json:").*?(?=") 可以匹配出
RefreshAfter 之后应该怎么做
]]>文字 demo:
你好啊 010-6565656 你好!
我的正则
/\d+-\d+/
这样拿到的匹配结果是 010-6565656,但是如果我只想要匹配结果中的电话号码,而不要区号的话怎么写呢(匹配语句里面还是得包含区号,只是输出结果不要区号)?我依稀记得有个什么写法可以只拿到想要的部分。但是太久没写正则了,不记得叫啥了,搜索引擎搜了半天也不知道关键字是啥
]]>