应用场景:集成到企业内部系统,功能不难,但是要求集成化程度非常高,非网上那种拿来即用的独立智能体小工具,涉及企业数据库的数据读取、数据处理,企业流程注入,用户复杂交互等。 ]]>
## TypeScript 1. 避免使用 `any` 和 `unknown` 类型,应尽量定义明确的类型。 2. 避免使用 `as` 类型断言,优先使用类型守卫 (Type Guard) 或泛型。 3. 充分利用 TypeScript 的类型推导能力,减少冗余类型声明。 但是很多时候依然会产生很多 any 类型的错误,很多时候编辑器都无视了项目的规则,每次在输入框中重复带入一些规则又特别不方便。
这里只是举了一个案例,感谢大家提出宝贵的意见.
大家如何解决类似的问题?
出现这种情况的原因是什么?
解决两个痛点
痛点 1:看蓝湖需求还要手动截图、复制粘贴给 AI ?
现在: 直接给个 URL ,AI 自动提取 Axure 原型、字段规则、业务逻辑,支持开发/测试/探索三种分析模式。
痛点 2:每个人的 Cursor/Windsurf 都是孤岛,我的 AI 分析完需求,测试同学的 AI 又重新分析一遍。
现在: 所有 AI 连接同一个 MCP Server ,后端 AI 分析的结果,测试 AI 直接查询用。支持知识库、踩坑记录、 @提醒、飞书通知。
开源地址
- GitHub: https://github.com/dsphper/lanhu-mcp
- License: MIT
与人 Star ⭐,手留余香 和提 Issue/PR !
]]>- 法律考公(行测/申论/法律基础)
想请教各位几个比较现实的问题:
1️⃣ 题库来源问题
- 这种考试题目一般怎么搞?
2️⃣ 商业 & 价值
- 这种文科题库现在是不是已经卷成红海了?
- 程序员角度看,这类产品是否有「小而美」的空间?
- 订阅制 / 单科付费 哪种更合理?
4️⃣ 踩坑经验
- 有没有做过类似教育 / 题库 / 考试系统的?
- 哪些地方一开始容易想当然,后来发现是坑?
感谢各位指点 🙏
]]>- 无广告
- 隐私强,不收集信息;可虚拟货币;可 Tor 。甚至开发了个新协议插件避免浏览器 mitm
- 垃圾信息少,AI 模版的那种页面大幅下降。
- 结果精简,一般就 10-20 个结果。
- 可定制 widget ,比如我不喜欢视频和 AI 结果可以设置去除。
- 自带 filter ,block 了一些类似于 csdn 的垃圾站点干扰。无需插件
- 可定制 CSS ,很 web
不喜欢的
- 慢,平均 0.6s-2s 。如果习惯了谷歌的速度,会不适应。
- 自带地图远不如谷歌
- 没有数字翻页( paging )不习惯
建议的文档: 带截止日期的学校身份证 课程表 学费收据 文档格式须为 .jpg 、.jpeg 、.png 、.pdf
]]>Dify or Langfuse ?这种独立服务是不是又让 vibe coding 变得更加困难了。
]]>下载 Antigravity 一直提示"Not Eligible"登不上,TUN 模式把世界上的 IP 换了个遍都没用
嫖的 Gemini 如何才能使用 Agent 跑 3.0 API..请教下.. ]]>
代码仓库: https://github.com/fuck-algorithm/leetcode-46-permutations
效果演示:
46.gif 

前言
12 月 15 号早上,一觉醒来,拿起手机看到我的邮箱收到了内网服务无法访问的告警邮件,本以为只是简单的服务卡死,将服务器重启后就去上班了。
后来,陆续有好友联系我说网站挂了。
定位问题
晚上下班回家后,尝试将电脑断电重启,发现 pve 只能存活 2 分钟左右,然后整个系统卡死,无法进行任何操作。首先,我想到的是:会不会某个 vm 虚拟机或者 ct 容器影响到宿主机了。
因为系统只能存活几分钟,在执行禁用操作的时候,强制重启了好几次服务器。当所有的服务都停止启动后,卡死的问题依旧存在。
翻日志
没辙了,这已经不是简单的软件问题了,只好翻日志,看报错信息了。
nvme nvme0: I/O timeout, aborting 如上所示,日志中出现了好几条 I/O 超时消息,顿感不妙,该不会硬盘坏了吧....
找到原因
找了一圈方案,大部分都说这个错误是 nvme 硬盘的通病,他有一个省电模式,在某些硬件+内核的组合下会导致控制器假死。
解决方案也很简单,找到 GRUB 的配置文件,关闭他的自动睡眠和省电模式,在 pve 中这个文件位于/etc/default/grub,打开这个文件后,找到 GRUB_CMDLINE_LINUX_DEFAULT 属性,添加两个值:
- nvme_core.default_ps_max_latency_us=0
- pcie_aspm=off
GRUB_CMDLINE_LINUX_DEFAULT="quiet nvme_core.default_ps_max_latency_us=0 pcie_aspm=off" 保存文件后,执行:update-grub 命令,随后重启整个 pve 主机。
VM 无法启动
pve 启动卡死的问题解决了,现在又有了新的问题。启动我那台跑了整个网站服务的 vm 虚拟机时,出现了如下所示的错误:
mount: mounting /dev/sda3 /dev/sda3 on /sysroot failed: No error information Mounting root failed. initramfs emergency recovery shell launched. 
这下坏事了,linux 的根分区无法挂载了😭,应该是刚才频繁的卡死,我不断的启动 pve ,容器不停的启动、强制终止导致盘里这块区域的数据受损了,处于半死不活状态了。
从备份中还原
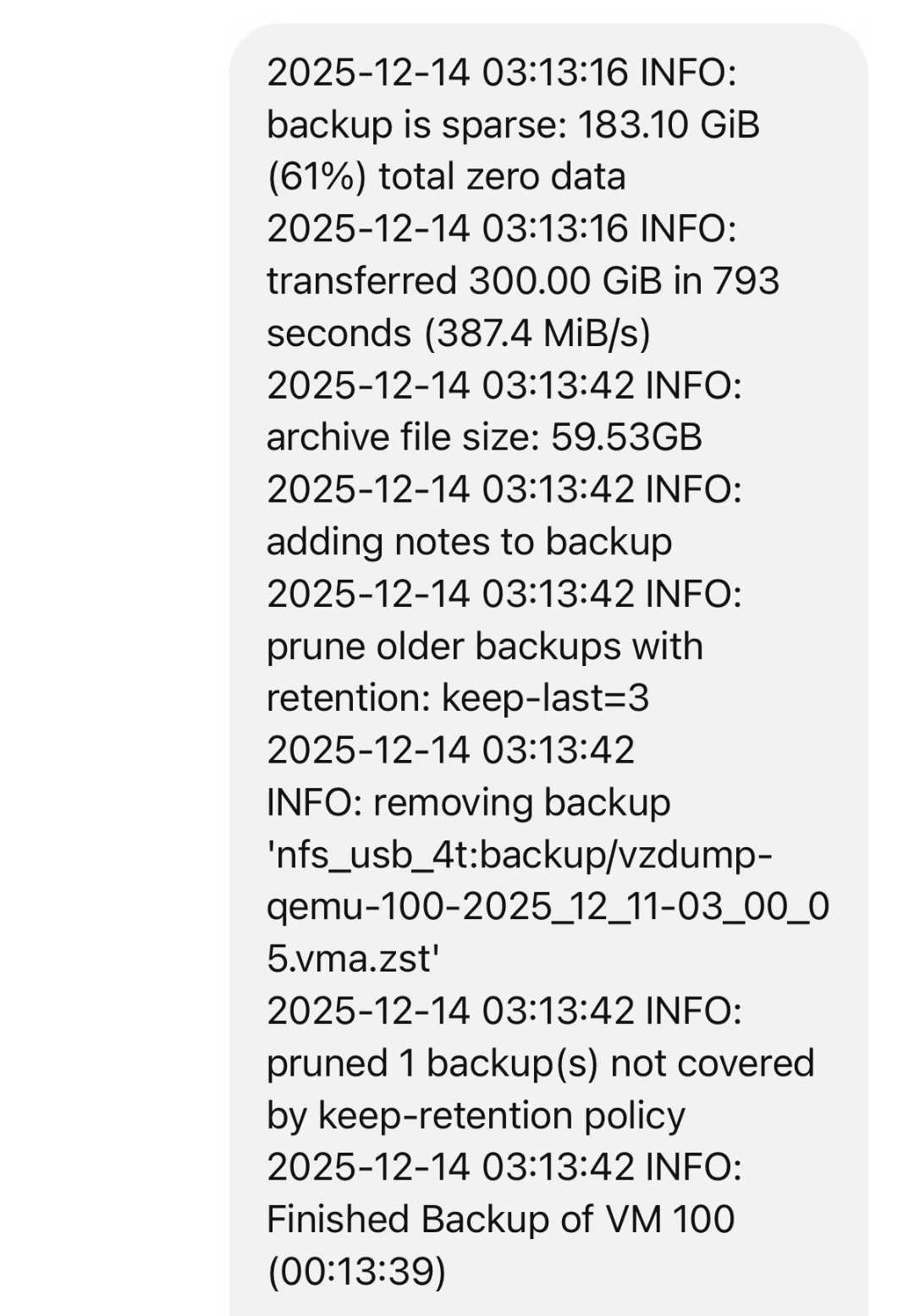
幸好我之前设置了 vm 容器的整机备份,连续备份并存储 3 天,全部放在了内网另一台机器的机械硬盘中,通过网络挂载到 pve 上的。

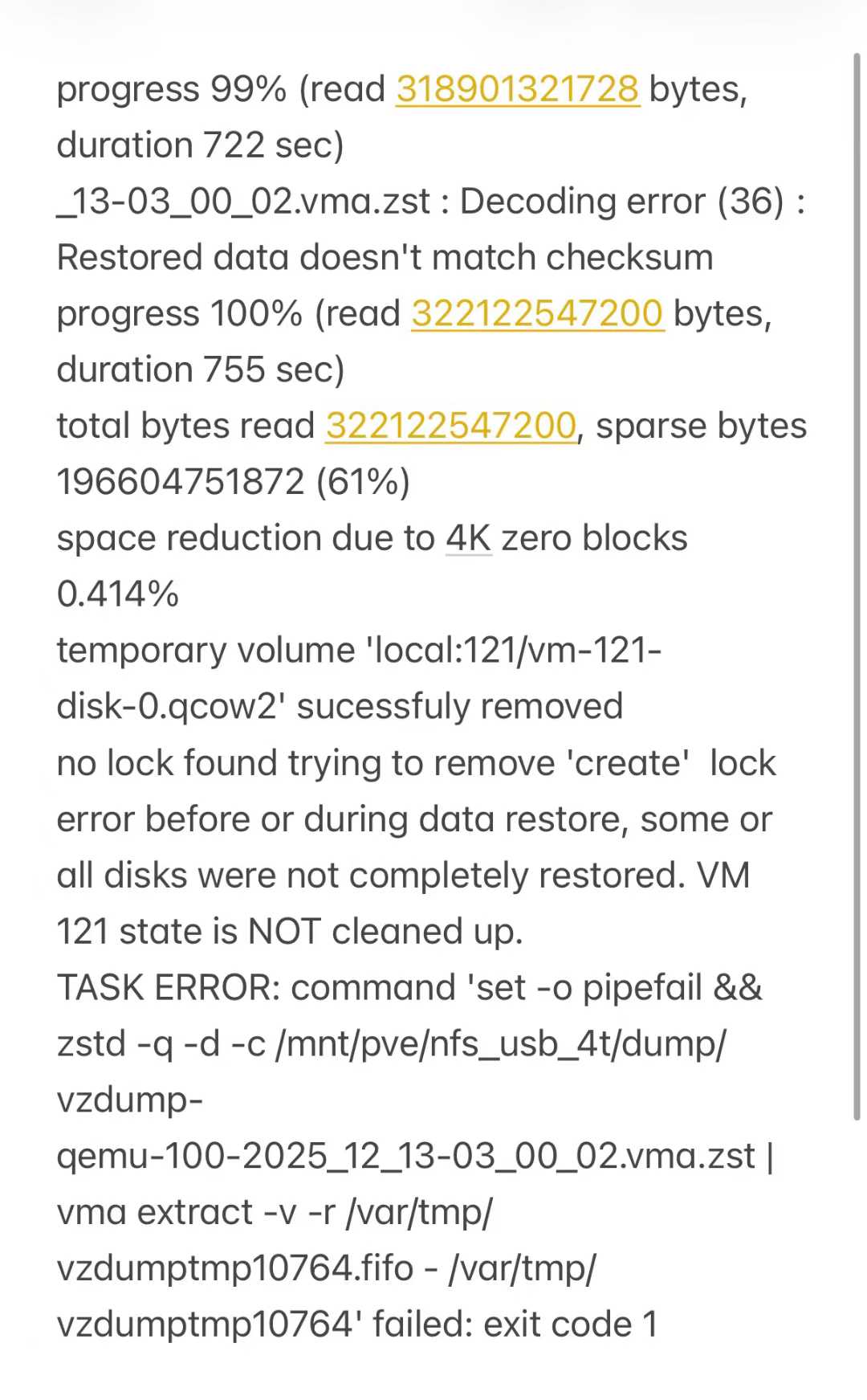
本以为一切都会很顺利,还原的时候出现了错误,zstd 解码时,发现压缩块损坏,导致还原失败。
_15-03_00_03.vma.zst : Decoding error (36) : Corrupted block detected vma: restore failed - short vma extent (2801635 < 3801600) /bin/bash: line 1: 2131 Exit 1 zstd -q -d -c /mnt/pve/nfs_usb_4t/dump/vzdump-qemu-100-2025_12_15-03_00_03.vma.zst 
于是,我又尝试了另外两个备份,结果都无法还原,全部都是相同的错误。当初做备份的时候,想着我都整机备份了,而且保存了 3 天的备份,总不可能三个全坏吧。
progress 99% (read 318901321728 bytes, duration 722 sec) _13-03_00_02.vma.zst : Decoding error (36) : Restored data doesn't match checksum progress 100% (read 322122547200 bytes, duration 755 sec) total bytes read 322122547200, sparse bytes 196604751872 (61%) space reduction due to 4K zero blocks 0.414% temporary volume 'local:121/vm-121-disk-0.qcow2' sucessfuly removed no lock found trying to remove 'create' lock error before or during data restore, some or all disks were not completely restored. VM 121 state is NOT cleaned up. TASK ERROR: command 'set -o pipefail && zstd -q -d -c /mnt/pve/nfs_usb_4t/dump/vzdump-qemu-100-2025_12_13-03_00_02.vma.zst | vma extract -v -r /var/tmp/vzdumptmp10764.fifo - /var/tmp/vzdumptmp10764' failed: exit code 1 现在狠狠的打脸了,我手里目前只有2023 年 11 月迁移技术栈时,那份 docker compose 的初始数据。相当于我丢失了 2 年的数据,这我是不能接受的。
折腾到这里,我一看时间,已经凌晨 1:30 了,明天还要上班,带着郁闷的心情去睡觉了。
强行提取数据
睡醒后,不愿接受这个现实,想到改造的那个练习英语单词的开源项目,这 1 年多时间下来,平均的日活跃人数已经有 40 多个了,数据库存储 8w 多条单词数据了😑,太难受了😭
实在是想不到什么好法子了,只好在 v 站和朋友圈都发了求助帖。
找到方案
在此,感谢 v 站老哥DylanC,给了我一组关键词。

晚上回家后,开始找资料,问 GPT ,经过一番折腾总算是把数据提取出来了。
跳过校验
从上述的错误日志中能看出,我在还原的时候已经读了 99%的数据了,只是文件的完整性校验过不了,我的 vm 虚拟机里一整个全是 docker compose 编排的服务( mysql 、redis 、java 、nginx 等),理论上是比较好找回的。
pve 的定时备份采用的是 vzdump 服务,备份出来的产物是.vma.zst格式的,他的本质是:
- zstd 压缩
- 内部是
vma归档 - 包含:
qemu-server.confdisk-drive-scsi0.raw
知道这些后,我们先把网络存储中的备份文件拷贝到 pve 主机的/var/lib/vz/dump目录,执行下述命令,忽略校验,强行解压。
zstd -d -c --no-check vzdump-qemu-100-2025_12_13-03_00_02.vma.zst \ | vma extract -v - ./extract.partial 等待一段时间后,程序执行结束,你会发现报错依然存在,但是这不影响已经读取的数据,cd 到./extract.partial 目录,你应该能看到xxx.conf和xxx.raw文件,然后看下.raw 后缀文件的空间占用,只要不是太小(占用<1GB),那么这份数据基本是没问题的,磁盘的 RAW 文件也算是被解出来了。
挂载 RAW 磁盘
为了防止数据遭到破坏,我们需要做只读挂载,命令如下:
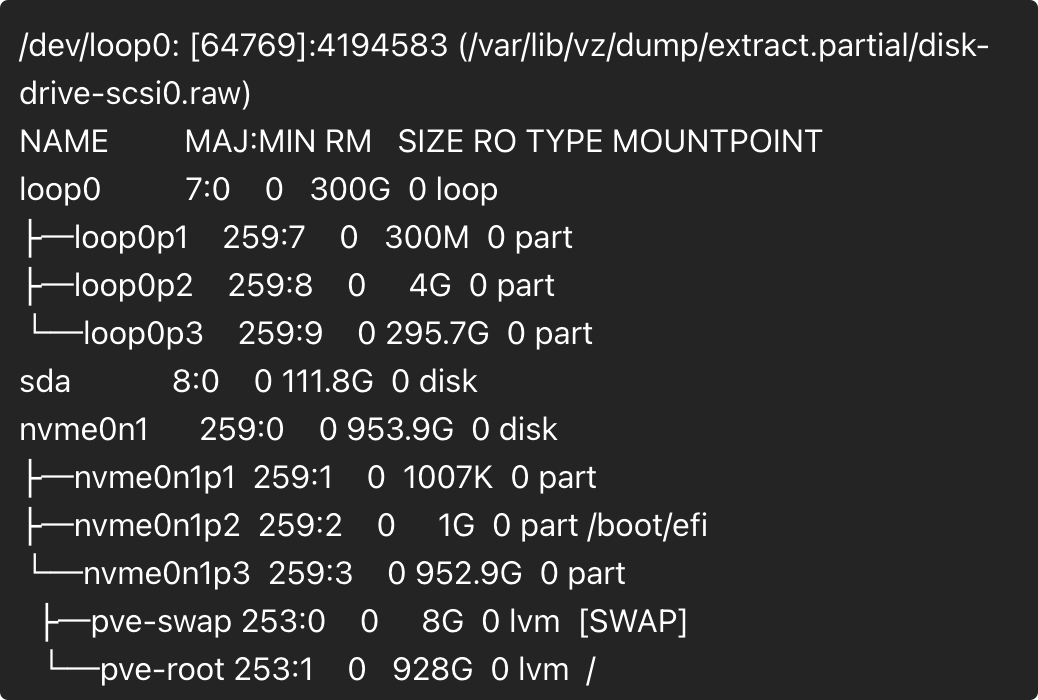
losetup -fP /var/lib/vz/dump/extract.partial/disk-drive-scsi0.raw 然后,执行命令查看结果。
losetup -a lsblk 执行后,应该能看到类似loop0、loop0p1、loop0p2这样的数据,找到那块空间跟你在 extract.partial 目录下看到的空间差不多大小的盘。
挂载分区
首先,我们通过下述命令来创建一个挂载点:
mkdir -p /mnt/rescue 随后,尝试挂载分区( loop0p1 、loop0p2....等),找你的根分区,如果你运气好,p1 就挂载成功了,那就不需要挂载其他的了。
我的根分区是 p3 ,那么我挂载 p3 即可。
mount -o ro,norecovery /dev/loop0p3 /mnt/rescue 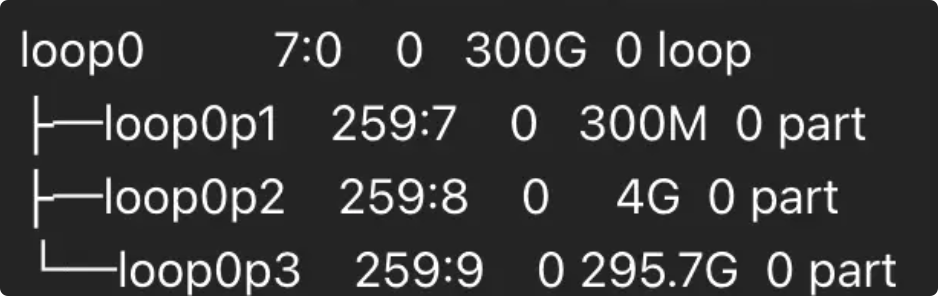
如果失败的话,代表它不是文件系统,需要继续尝试挂载其他分区,直到成功为止。
umount /mnt/rescue 2>/dev/null mount -o ro,norecovery /dev/loop0p2 /mnt/rescue 最后,查看挂载点里是否有你的数据。
ls /mnt/rescue 不出意外的话,你应该能看到类似下图所示的内容。

文件成功恢复,接下来要做的就是把这些文件拷贝到安全的地方即可。
写在最后
至此,文章就分享完毕了。
我是神奇的程序员,一位前端开发工程师。
如果你对我感兴趣,请移步我的个人网站,进一步了解。
]]>昨天在做业务建模时,看着 TypeScript 的 interface 定义,想到一个问题。
TypeScript 的类型系统在编译后会被擦除( Type Erasure )。这意味着 age: number 这样的约束只存在于开发阶段,运行时完全不可见。
但实际上,这些元数据完整地存在于源码中。如果能写个脚本,在编译时分析源码 AST ,把这些类型信息提取并保存下来,是不是就能在运行时直接复用了?
吃饱了撑的尝试实现了个原型。
1. 从最简单的想法开始
其实最直观的例子,就写的代码里。
interface User { posts: Post[]; } 这处理是类型约束,其实也顺便描述了业务关系:User 下面有多个 Post 。
如果不去引用那些额外的装饰器、配置文件,直接复用类型定义来描述关系,是不是也行得通?
顺着这个思路,既然显式的“模型关系”可以从 Post[] 这样的类型结构中直接读出来,那更隐晦的“校验规则”(比如字符串长度、格式限制)是不是也能想办法“寄生”在类型里?
如果能同时把“关系”和“规则”都收敛在类型定义中,并通过编译分析提取给运行时使用,那 interface 就不仅仅是静态检查的工具,而变成了完整的业务逻辑描述。
2. 顺手把关系读出来
既然决定要从类型里提取信息,那先试试最简单的“关系”。
比如 posts: Post[]。
在 TypeScript 编译器的视角中,这行代码对应着一个结构严谨的 AST (抽象语法树)节点。
编译器通过 PropertySignature 识别属性名,利用 ArrayType 确定数组结构,并借助 TypeReference 锁定元素类型 Post。这些细粒度的结构化数据(可通过 TypeScript AST Viewer 直观查看)完整保留了代码的语义信息。
核心逻辑在于利用 [Compiler API](( https://github.com/microsoft/TypeScript/wiki/Using-the-Compiler-API)) (记录下,他是个强大的工具集,允许开发者像编译器一样“理解”代码。) 遍历 AST:一旦识别到数组类型的属性定义,便将其提取并映射为“一对多”的关系描述。经过转换,源码中的类型定义就被标准化为一份配置 JSON:
"relations": { "posts": { "type": "hasMany", "target": "Post" } } 这样,模型关系配置就可以直接复用类型定义。
3. 那规则呢?先找个地方藏
关系搞定了,接下来是更复杂的校验规则(如 minLen、email)。TypeScript 本身没有地方直接写 minLen 这种东西,所以好像需要一个载体。
在 TypeScript 的泛型可以是实现一种 Phantom Type (幽灵类型):
// T 是实际运行时的类型 // Config 是仅编译期存在的元数据 type Field<T, Config> = T; Field<string, ...> 在运行时就是普通的 string。泛型参数 Config 虽然会被编译擦除,但在 AST 中是可以读取到的。
这样好像就可以在不影响运行时逻辑的前提下嵌入元数据。
看起来像是:
// src/domain/models.ts // 引入我定义的“幽灵类型” import type { Str, Num } from '@bizmod/core'; import type { MinLen, Email, BlockList } from '@bizmod/rules'; export interface User { id: Str; // 多个规则一起用:最少 2 个字 + 违禁词过滤 name: Str<[ MinLen<2>, BlockList<["admin", "root"]> ]>; email: Str<[Email]>; } 在编辑器里,name 依然是字符串,该怎么用怎么用,完全不影响开发。但在代码文本里,那个 MinLen 和 BlockList 的标记就留在那儿了。
4. 把规则也读出来
定义好类型载体,下一步就是把这些规则信息也读出来。我查了一下,这里正好可以用 TypeScript 的 Compiler API 来实现。
简单来说,它能把 .ts 文件变成一棵可以遍历的树( AST )。我们写个脚本,遍历所有的 interface。当发现属性使用了 Field 类型时,读取其泛型参数(比如 MinLen、admin),并保存下来。
核心逻辑大概是这样(简化版):
// analyzer.ts (伪代码) function visit(node: ts.Node) { // 1. 找到所有 Interface if (ts.isInterfaceDeclaration(node)) { const modelName = node.name.text; // 拿到 "User" // 2. 遍历它的属性 node.members.forEach(member => { const fieldName = member.name.text; // 拿到 "name" // 3. 重点:解析泛型参数! // 这里能拿到 "MinLen", "BlockList" 甚至里面的 ["admin", "root"] const rules = extractRulesFromGeneric(member.type); schema[modelName][fieldName] = rules; }); } } 运行脚本后,生成了一个完整的 schema.json,包含了关系和校验规则:
{ "User": { "name": "User", "fields": { "name": { "type": "string", "required": true, "rules": { "minLen": 2, "blockList": ["admin", "root"] } }, "email": { "type": "string", "rules": { "email": true } } }, "relations": { "posts": { "type": "hasMany", "target": "Post" } } } } 代码里的信息就被提取出来了存成了清单。
5. 运行时怎么用?
前面的脚本跑完以后,所有这些信息(校验规则 + 模型关系)就都存进了 schema.json 里。
--
有了这个文件,运行时要做的事情就很简单了。
--
程序启动时读取这个 JSON 。当 API 接收到数据时,根据 JSON 里的规则自动执行校验逻辑。
这样就实现了把 TypeScript 的静态类型信息带到运行时使用。
以后新增业务模型,只需要维护一份 interface 定义,校验规则和关系定义都会自动同步生成。
--
6. 简单的验证 Demo
为了验证可行性,写个测试。
1. 类型定义
利用 Phantom Type 携带元数据:
// types.ts // T 是真实类型,Rules 是元数据 export type Field<T, Rules extends any[]> = T; // 定义一个规则类型 export type MinLen<N extends number> = { _tag: 'MinLen', val: N }; // 业务代码 export interface User { name: Field<string, [MinLen<2>]>; } 2. 编译器分析 (Analyzer)
使用 TS Compiler API 提取元数据(简化版):
// analyzer.ts import * as ts from "typescript"; function analyze(fileName: string) { const program = ts.createProgram([fileName], {}); const sourceFile = program.getSourceFile(fileName)!; ts.forEachChild(sourceFile, node => { // 1. 找到 Interface if (!ts.isInterfaceDeclaration(node)) return; node.members.forEach(member => { // 2. 获取属性名 "name" const name = member.name.getText(); // 3. 获取类型节点 Field<...> if (ts.isTypeReferenceNode(member.type)) { // 4. 提取第二个泛型参数 [MinLen<2>] const rulesArg = member.type.typeArguments?.[1]; // 5. 这里就可以解析出 "MinLen" 和 2 了 console.log(`Field: ${name}, Rules: ${rulesArg.getText()}`); } }); }); } 3. 运行时消费
生成的 JSON 元数据可以直接在运行时使用:
// runtime.ts const schema = { User: { name: { rules: { minLen: 2 } } } }; function validate(data: any) { const rules = schema.User.name.rules; if (rules.minLen && data.name.length < rules.minLen) { throw new Error("Validation Failed: Too short"); } } 最后扯犊子
这次尝试的核心逻辑其实很简单:用脚本把代码里的类型“抄”出来,存成 JSON ,然后程序运行的时候照着 JSON 执行。
--
本质上,就是把 TypeScript 代码当成配置文件来用。
我只是纯无聊玩玩,如果有大佬想写个小工具什么的。可以放在下面(我懒)。
--
最后,你们在玩 TypeScript 的时候有哪些骚想法?
]]>这下面要求了哪些权限(问了 GPT 都是一些很普通的权限, 没有涉及高危权限) package: com.rbombanza.suga uses-permission: name='android.permission.INTERNET' permission: com.rbombanza.suga.permission.C2D_MESSAGE uses-permission: name='com.rbombanza.suga.permission.C2D_MESSAGE' uses-permission: name='android.permission.POST_NOTIFICATIONS' uses-permission: name='android.permission.WAKE_LOCK' uses-permission: name='com.google.android.c2dm.permission.RECEIVE' uses-permission: name='android.permission.VIBRATE' uses-permission: name='android.permission.RECEIVE_BOOT_COMPLETED' uses-permission: name='com.sec.android.provider.badge.permission.READ' uses-permission: name='com.sec.android.provider.badge.permission.WRITE' uses-permission: name='com.htc.launcher.permission.READ_SETTINGS' uses-permission: name='com.htc.launcher.permission.UPDATE_SHORTCUT' uses-permission: name='com.huawei.android.launcher.permission.CHANGE_BADGE' uses-permission: name='com.huawei.android.launcher.permission.READ_SETTINGS' uses-permission: name='com.huawei.android.launcher.permission.WRITE_SETTINGS' uses-permission: name='me.everything.badger.permission.BADGE_COUNT_READ' uses-permission: name='android.permission.ACCESS_NETWORK_STATE' uses-permission: name='android.permission.FOREGROUND_SERVICE' permission: com.rbombanza.suga.DYNAMIC_RECEIVER_NOT_EXPORTED_PERMISSION uses-permission: name='com.rbombanza.suga.DYNAMIC_RECEIVER_NOT_EXPORTED_PERMISSION' uses-permission: name='android.permission.ACCESS_ADSERVICES_ATTRIBUTION' uses-permission: name='com.google.android.gms.permission.AD_ID' uses-permission: name='com.samsung.android.mapsagent.permission.READ_APP_INFO' uses-permission: name='com.huawei.appmarket.service.commondata.permission.GET_COMMON_DATA' uses-permission: name='com.google.android.finsky.permission.BIND_GET_INSTALL_REFERRER_SERVICE' 话说国产模型应该对鸿蒙一类的支持更好才对吧,为啥会这样? ]]>
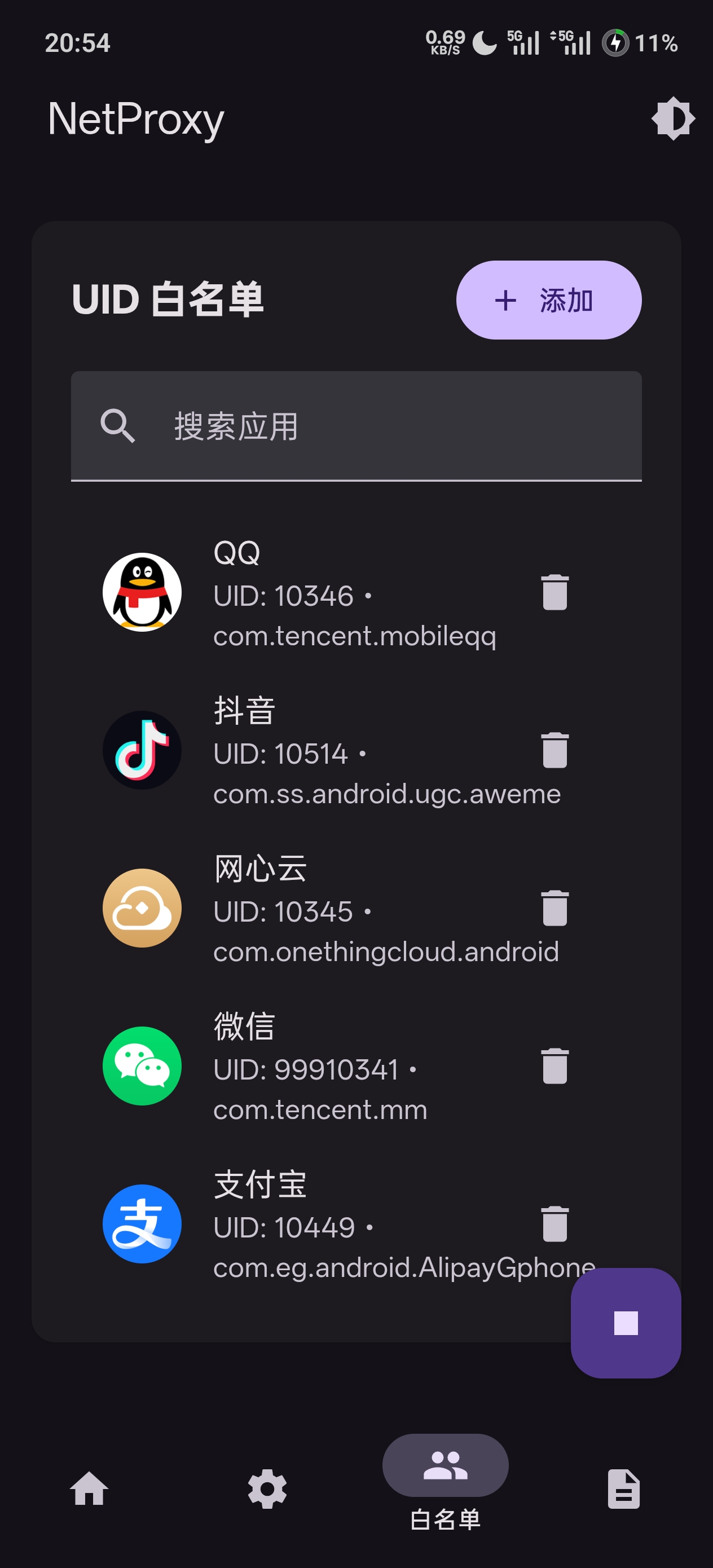
NetProxy-Magisk 基于 Xray 核心 实现系统级透明代理,提供统一的全局流量转发能力,适合需要深度代理控制的用户。
🔧 主要特性
- WebUI 管理界面
采用 Material Design 3 全新 UI ,简洁现代 - Xray 内核驱动
高性能、可扩展、协议兼容性强 - 系统级透明代理
自动配置 iptables ,无感接管所有 TCP 流量 - 分应用代理
支持黑名单 / 白名单精细控制 - 日志自动管理
便于排错和调试 - 完全开源
可随意扩展与二次开发
🖼 界面预览
📦 安装方式
使用 Magisk Manager 刷入 ZIP → 重启即可使用
📘 配置说明
-
默认配置路径
/data/adb/modules/netproxy/xraycore/config/default.json -
配置兼容性
兼容 V2RayNG 导出配置,只需替换inbounds即可完成透明代理适配。
📂 GitHub
👉 https://github.com/Fanju6/NetProxy-Magisk
如果你想在 Android 上获得真正意义的 系统级 Xray 透明代理体验,欢迎试用,也欢迎提交 Issue / PR。
📢 Telegram 群组
欢迎加入讨论、交流与反馈:
👉 https://t.me/NetProxy_Magisk
以前只有密码不一致的时候才会弹窗,用的是自建的 vaultwarden 1.34.3-alpine ,没有修改过版本,有一样情况的人吗?
]]>java, c++, rust 哪个更合适一点呢。
ps:楼主不认同有了 ai 就不需要学习的论调,除非 ai 能彻底取代了我让我没活儿干,不然只要我盯在岗位上,那么无论是 ai 还是系统需求,都要求我有一定的熟练技能。
所以,说不用学的朋友可以暂时不表达啦。 ]]>
解决两个痛点
痛点 1: 看蓝湖需求还要手动截图、复制粘贴给 AI ?
现在: 直接给个 URL ,AI 自动提取 Axure 原型、字段规则、业务逻辑,支持开发/测试/探索三种分析模式。
痛点 2: 每个人的 Cursor/Windsurf 都是孤岛,我的 AI 分析完需求,测试同学的 AI 又重新分析一遍。
现在: 所有 AI 连接同一个 MCP Server ,后端 AI 分析的结果,测试 AI 直接查询用。支持知识库、踩坑记录、 @提醒、飞书通知。
开源地址
GitHub: https://github.com/dsphper/lanhu-mcp
License: MIT
欢迎 Star ⭐ 和提 Issue/PR 。
]]>还测试其他几家,都是网页版开思考直接对话,结果如下
小米 > 元宝 >> deepseek > glm4.6 > 豆包 >>> kimi
这上面只有小米和元宝能一次 AC ,deepseek ,glm4.6 和豆包都是超时,排名是相对的程序运行速度,kimi 直接写出来的没法运行 ]]>
已经明确的点是
1. 和网络无关,我的另一个账号登录正常,两个都是美区,像一个电脑的相同网络环境。美区 ip ,tun 模式
2. 做了年龄验证。
3. 无法登陆的账号 aistudio ,gemini 都能正常使用,甚至使用美区 paypal 开了 google ai pro 的 20 美金的 gemini 一样无法正常打开。
还有什么可能呢? ]]>
TL;DR
做了个工具解决两个痛点:
- AI 直接读蓝湖:给个 URL ,AI 自动提取 Axure 原型并分析(不用复制粘贴了)
- 打破 AI 孤岛:团队所有人的 AI ( Cursor/Windsurf/Claude )共享知识库,不再重复劳动
GitHub: https://github.com/dsphper/lanhu-mcp
基于 Model Context Protocol (MCP)
背景:AI 时代的两个新痛点
痛点 1:需求文档还要手动复制粘贴?
以前看蓝湖需求文档的流程:
- 打开蓝湖链接
- 一页一页截图/复制文字
- 粘贴给 AI
- 重复 10 次...
都 AI 时代了,为啥还要手动复制粘贴?直接给个 URL 让 AI 自己去读不香吗?
痛点 2:每个人的 AI 都是孤岛
我的 Cursor AI 分析完需求,花了 5 分钟理清字段规则。
结果:
- 测试同学的 AI 又重新分析了一遍
- 前端同学的 AI 也重新分析了一遍
- 我踩的坑记录在 Cursor 里,别人的 AI 不知道
每个人的 Cursor/Windsurf 是独立的,AI 之间完全不共享上下文。
解决方案
核心功能 1:AI 直接读蓝湖文档
不需要复制粘贴,直接对 AI 说:
@AI 帮我看下这个需求文档 https://lanhuapp.com/web/#/item/project/product?tid=xxx&pid=xxx&docId=xxx AI 自动完成:
- 提取所有页面的文字和截图
- 识别字段规则(必填、类型、长度、校验)
- 提取业务逻辑(判断条件、异常处理)
- 生成流程图
支持 3 种分析模式:
- 开发视角:字段规则表 + 业务逻辑清单 + 接口依赖
- 测试视角:测试场景 + 测试用例 + 边界值
- 快速探索:核心功能概览 + 模块依赖图
还支持 UI 设计:
@AI 帮我下载"首页设计"的所有切图到 src/assets/ AI 自动识别项目类型( React/Vue ),生成语义化文件名,批量下载。
核心功能 2:团队留言板(这是最爽的功能)
后端 AI 分析完需求后:
@测试小李 @前端小张 我分析了"用户登录"需求: - 手机号必填,11 位数字 - 密码 6-20 位,必须包含字母+数字 - 验证码 4 位纯数字,5 分钟有效 - 错误 3 次锁定 30 分钟 [类型:knowledge] // 保存到知识库 测试同学的 AI 直接查询:
@AI 查看所有关于"登录"的知识库 → 立即获取后端 AI 的分析结果! 架构图:
┌─────────────────────────────┐ │ Lanhu MCP Server │ │ (统一知识中枢) │ │ │ │ 📊 需求分析结果 │ │ 🐛 开发踩坑记录 │ │ 📋 测试用例模板 │ │ 💡 技术决策文档 │ └──────────┬──────────────────┘ │ ┌────────────┼────────────┐ │ │ │ ┌────▼───┐ ┌───▼────┐ ┌──▼─────┐ │后端 AI │ │前端 AI │ │测试 AI │ │(小王) │ │(小张) │ │(小李) │ └────────┘ └────────┘ └────────┘ Cursor Windsurf Claude 支持的留言类型:
- 🧠 knowledge:知识库,永久保存(坑点、经验、最佳实践)
- 📋 task:任务协作(让其他人的 AI 帮忙查询代码/数据库,安全限制:只能查不能改)
- 🚨 urgent:紧急通知(自动发飞书通知)
- ❓ question:提问讨论
还能:
- 自动记录谁的 AI 看过这个需求
- 支持 @提醒 + 飞书通知
- 全文搜索历史留言
实际效果
以前:
- 需求分析:每人 5 分钟 × 5 人 = 25 分钟
- 复制粘贴:每个需求 2-3 分钟,一天看 10 个需求 = 30 分钟
- 踩坑:Redis 超时问题,3 个人分别花 1 小时排查
现在:
- 需求分析:后端 AI 分析 5 分钟,其他人 AI 直接查询 = 5 分钟
- 复制粘贴:0 分钟(给个 URL 就行)
- 踩坑:第一个人记录到知识库,后面的人 AI 直接找到解决方案
保守估计,每周能节省团队 5-10 小时。
技术实现
- 协议:基于 Model Context Protocol (MCP)
- 框架:FastMCP ( Python )
- 浏览器自动化:Playwright (提取页面内容和截图)
- 通知集成:飞书 Webhook
- 数据存储:本地 JSON + 文件缓存(基于版本号)
- 性能:页面截图 ~2 秒/页,智能缓存,增量更新
核心代码 3800+ 行,单文件部署。
安装和配置
最简单方式(让 AI 帮你):
在 Cursor 中对 AI 说:
"帮我克隆并安装 https://github.com/dsphper/lanhu-mcp 项目" AI 会引导你完成所有步骤。
手动安装:
git clone https://github.com/dsphper/lanhu-mcp.git cd lanhu-mcp # Docker 部署(推荐) bash setup-env.sh # 交互式配置 Cookie docker-compose up -d # 或源码运行 bash easy-install.sh # 一键安装并配置 配置 Cursor:
{ "mcpServers": { "lanhu": { "url": "http://localhost:8000/mcp?role=后端&name=张三" } } } 适用场景
✅ 适合你,如果:
- 公司用蓝湖管理需求文档和 UI 设计
- 团队使用 Cursor/Windsurf/Claude Desktop 等 AI IDE
- 需要多角色协作(后端、前端、测试、产品)
❌ 不适合你,如果:
- 需求文档不在蓝湖(可以提 Issue ,我考虑支持其他平台)
- 团队就你一个人(虽然也能用,但价值不大)
开源地址
GitHub: https://github.com/dsphper/lanhu-mcp
License: MIT
文档: 挺详细的,有快速开始、部署指南、Cookie 获取教程
欢迎提 Issue 、PR ,或者在下面讨论。
想听听大家的意见
- 你们团队的 AI 协作有遇到类似问题吗?
- 除了需求分析和团队协作,还有什么场景适合"AI 共享知识"?
- 有没有人用过类似的工具?效果如何?
- 如果支持 Figma/墨刀/其他原型工具,有人用吗?
最后
如果你认可这个想法,或者觉得对你有帮助,给个 Star ⭐ 就是对我最大的鼓励!
GitHub: https://github.com/dsphper/lanhu-mcp
P.S. 代码可能不够优雅( 3800 行单文件),欢迎拍砖和提 PR 。
P.P.S 项目对小白友好,不懂技术也能让 AI 帮你安装,详见 README 。
]]>这导致有些底层逻辑明明可以共用同一个函数,也几乎人手一个实现;另外这个人 A 改动的东西,可能也影响了另一个人 B 的逻辑却不知道,导致程序 bug 了,B 寻思着明明我最近没改这块怎么忽然出 bug 了,找半天发现是 A 动了底层,而 A 又不知道 B 也在用这个。
所以我们老板想在公司内的代码库里开 PR ,自己的分支合并到 Dev 分支时要走 PR ,让另一个人 review 一下,这样能不能提升代码质量另说,起码能增加内部交流。
各位大佬你们公司内部有 PR 吗?
]]>所有人都在用 AI, 建造屎山的速度越来越快. 你还能静得下心去分析日志吗? 还愿意仔细推敲每一行代码的逻辑吗?
就像一篇文章, 如果知道是 AI 写的, 我会瞬间失去阅读的兴趣. 感觉自己的时间都被浪费了.
]]>AI 模型的输出通常是逐字生成的流式数据,尤其是在实时对话交互的场景中,用户希望能即时看到 AI 输出内容的过程。而另一方面,我们在很多场景下需要 AI 模型输出结构化的内容,方便我们后续处理和展示。我们可以通过 markdown 的标题格式来组织 AI 的输出,但是 markdown 的无法做到强约束。如果需要保证强结构化,那么我们一般会采用 JSON 格式,对此很多模型都有强制约束输出 Json 的参数。 这其中有两大问题:
- 高延迟 :如果使用 Json 格式,传统的 Json.Parse 方法必须等待整个字符串接收完毕才能解析,这会导致高延迟问题。用户无法实时看到 AI 的思考过程,体验大打折扣。
- 交互不稳定 :如果使用 Markdown 格式,AI 输出可能不符合预期,导致前端展示异常。
因此,我们需要一种能够边接收数据边解析的方案,确保用户实时看到 AI 的输出,同时保证解析的健壮性。
场景
例如我们在理解用户问题这个场景时,既想要结构化的数据,又想要实时的将结果反馈到前端 
设计目标
为了解决上述问题,我们设计了一款流式 JSON 解析器,目标包括:
- 实时性:支持逐字符解析,边接收边触发回调。
- 路径订阅:允许用户按需订阅 JSON 中的特定路径(如
$.nodes[*].title),减少无效数据处理。 - 增量输出:针对字符串值,仅发送新增部分,避免重复传递完整值。
- 健壮性:即使 JSON 格式不完整或后续部分有错误,已解析的数据也能正常使用。
核心实现
我们的解析器基于手写的有限状态机( FSM ),逐字符处理流式数据。以下是实现的关键组件和流程:
1. StreamingJsonParser (流式解析器)
- 状态机设计:解析器通过状态机维护当前解析上下文,支持对象、数组、字符串、数字等 JSON 元素的逐字符解析。
- 路径维护:通过栈结构记录当前解析路径(如
["nodes", 0, "title"]),用于路径匹配和回调触发。 - 增量输出:针对字符串值,记录上次发送的位置,仅发送新增部分。
状态机的核心逻辑如下: 
2. SimplePathMatcher (路径匹配器)
- 路径解析:支持将路径模式(如
$.nodes[*].title)解析为数组形式(如["nodes", "*", "title"])。 - 通配符匹配:支持
*通配符,用于匹配数组中的任意索引。 - 回调触发:当解析器识别到匹配路径的数据时,立即触发用户注册的回调函数。
增量与实时模式
解析器支持两种模式:
- 实时模式( realtime=true ):在值尚未最终确定时,依据当前缓冲区内容触发回调,适合逐字生成的场景。
- 增量模式( incremental=true ):针对字符串值,仅发送新增部分,避免重复传递完整值。
以下是增量解析的示例:
matcher := utils.NewSimplePathMatcher() matcher.On("$.choices[0].delta", func(value interface{}, path []interface{}) { fmt.Printf("path=%v, value=%v\n", path, value) }) parser := utils.NewStreamingJsonParser(matcher, true, true) _ = parser.Write("{\"choices\":[{\"delta\":\"") _ = parser.Write("Hel") // 增量触发回调:"Hel" _ = parser.Write("lo\"}]}\n") // 增量触发回调:"lo",结束后不再发送整串 _ = parser.End() 性能与内存优化
- 轻量高效:手写状态机避免引入完整 JSON 库,适合流式场景。
- 增量缓存:通过记录上次发送位置,减少重复回调数据。
- 路径匹配优化:使用切片维护路径,避免过度复制。
常见问题与改进方向
- 字符串转义:支持常见转义
\n,\t,\r,\\,\",\/,\b,\f;当前未支持\uXXXXUnicode 转义序列,可按需扩展。 - 路径匹配:目前为精确匹配,可考虑支持前缀匹配或更完整的 JsonPath 语法。
- 增量支持:目前仅支持字符串值的增量输出,未来可扩展至对象和数组。
文档&代码实现
- 项目:ThinkingMap 是一个开源 Agent 项目,有兴趣的欢迎 star ~
- 详细设计:JSON 流式解析
- 代码实现: stream_json_parser.go
代码使用 Golang 实现,如果需要使用其他语言,可以让 AI 翻译一下即可。
通过自研流式 JSON 解析器,成功解决了 AI 应用中实时性和结构化输出的难题。希望这次分享能为有类似需求的开发者提供参考。
]]>选哪家
最近 ai ide 研究得少了,想听听大家用过的一家?
]]>然后项目中有一些约定,比如不能用 xx 语法之类的。有没有一个通用的“默认提示词”可以不用我每次输入,但是可以生效的? ]]>
问题所在
每次 AI 流式输出新的文本块时,传统的 markdown 解析器都会从头开始重新解析整个文档——在已经渲染的内容上浪费 CPU 资源。Incremark 通过只解析新增内容来解决这个问题。
基准测试结果
较短的 Markdown 文档:
较长的 Markdown 文档:
说明:由于分块策略的影响,每次基准测试的性能提升倍数可能有所不同。演示页面使用随机块长度:
const chunks = content.match(/[\s\S]{1,20}/g) || []。这种分块方式会影响稳定块的生成,更好地模拟真实场景(一个块可能包含前一个或后一个块的内容)。无论如何分块,性能提升都是有保证的。演示网站没有使用任何有利于偏向自身性能展示的分块策略来夸大结果。
在线演示:
- Vue 演示:https://incremark-vue.vercel.app/
- React 演示:https://incremark-react.vercel.app/
- 文档:https://incremark-docs.vercel.app/
对于超长的 markdown 文档,性能提升更加惊人。20KB 的 markdown 基准测试实现了令人难以置信的 46 倍速度提升。内容越长,提速越显著——理论上没有上限。
核心优势
⚡ 通常 2-10 倍提速 - 针对 AI 流式场景
🚀 更大的提速 - 对于更长的文档(测试最高达 46 倍)
🎯 零冗余解析 - 每个字符最多只解析一次
✨ 完美适配 AI 流式 - 专为增量更新优化
💪 也适用于普通 markdown - 不仅限于 AI 场景
🔧 框架支持 - 包含 React 和 Vue 组件
为什么这么快?
传统解析器的问题
开发过 AI 聊天应用的小伙伴都知道,AI 流式输出会将内容分成小块传输到前端。每次接收到新块后,整个 markdown 字符串都必须喂给 markdown 解析器(无论是 remark 、marked.js 还是 markdown-it )。这些解析器每次都会重新解析整个 markdown 文档,即使是那些已经渲染且稳定的部分。这造成了很多不必要的的性能浪费。
像 vue-stream-markdown 这样的工具在渲染层做了努力,将稳定的 token 渲染为稳定的组件,只更新不稳定的组件,从而在 UI 层实现流畅的流式输出。
然而,这仍然无法解决根本的性能问题:markdown 文本的重复解析。这才是真正吞噬 CPU 性能的元凶。输出文档越长,性能浪费越严重。
Incremark 的核心性能优化
除了在 UI 渲染层实现组件复用和流畅更新外,incremark 的关键创新在于 markdown 解析:只解析不稳定的 markdown 块,永不重新解析稳定的块。这将解析复杂度从 **O(n²) 降低到 O(n)**。理论上,输出越长,性能提升越大。
1. 增量解析:从 O(n²) 到 O(n)
传统解析器每次都重新解析整个文档,导致解析工作量呈二次方增长。Incremark 的 IncremarkParser 类采用增量解析策略(参见 IncremarkParser.ts):
// 设计思路: // 1. 维护一个文本缓冲区来接收流式输入 // 2. 识别"稳定边界"并将已完成的块标记为 'completed' // 3. 对于正在接收的块,只重新解析该块的内容 // 4. 复杂的嵌套节点作为一个整体处理,直到确认完成 2. 智能边界检测
append 函数中的 findStableBoundary() 方法是关键优化点:
append(chunk: string): IncrementalUpdate { this.buffer += chunk this.updateLines() const { line: stableBoundary, contextAtLine } = this.findStableBoundary() if (stableBoundary >= this.pendingStartLine && stableBoundary >= 0) { // 只解析新完成的块,永不重新解析已完成的内容 const stableText = this.lines.slice(this.pendingStartLine, stableBoundary + 1).join('\n') const ast = this.parse(stableText) // ... } } 3. 状态管理避免冗余计算
解析器维护几个关键状态来消除重复工作:
buffer:累积的未解析内容completedBlocks:已完成且永不重新解析的块数组lineOffsets:行偏移量前缀和,支持 O(1) 行位置计算context:跟踪代码块、列表等的嵌套状态
4. 增量行更新优化
updateLines() 方法只处理新内容,避免全量 split 操作:
private updateLines(): void { // 找到最后一个不完整的行(可能被新块续上) const lastLineStart = this.lineOffsets[prevLineCount - 1] const textFromLastLine = this.buffer.slice(lastLineStart) // 只重新 split 最后一行及其后续内容 const newLines = textFromLastLine.split('\n') // 只更新变化的部分 } 性能对比
这种设计在实际测试中表现卓越:
| 文档大小 | 传统解析器(字符数) | Incremark (字符数) | 减少比例 |
|---|---|---|---|
| 1KB | 1,010,000 | 20,000 | 98% |
| 5KB | 25,050,000 | 100,000 | 99.6% |
| 20KB | 400,200,000 | 400,000 | 99.9% |
关键不变量
Incremark 的性能优势源于一个关键不变量:一旦块被标记为 completed ,就永远不会被重新解析。这确保了每个字符最多只被解析一次,实现了 O(n) 的时间复杂度。
🚀 立即开始
停止在冗余解析上浪费 CPU 资源。立即尝试 incremark:
快速安装
npm install @incremark/core # React 版本 npm install @incremark/react # Vue 版本 npm install @incremark/vue 资源链接
- 📚 文档:https://incremark-docs.vercel.app/
- 🎮 在线演示( Vue ):https://incremark-vue.vercel.app/
- 🎮 在线演示( React ):https://incremark-react.vercel.app/
- 💻 GitHub 仓库:https://github.com/kingshuaishuai/incremark
使用场景
完美适用于:
- 🤖 带流式响应的 AI 聊天应用
- ✍️ 实时 markdown 编辑器
- 📝 实时协作文档
- 📊 带 markdown 内容的流式数据看板
- 🎓 交互式学习平台
无论你是在构建 AI 界面还是只是想要更快的 markdown 渲染,incremark 都能提供你需要的性能。
欢迎体验与支持
非常欢迎尝试与体验,在线演示是感受速度提升最直观的方式:
- Vue 演示:https://incremark-vue.vercel.app/
- React 演示:https://incremark-react.vercel.app/
- 文档:https://incremark-docs.vercel.app/
如果你觉得 incremark 有用并想要参与改进,也欢迎提交 issue 与独特想法!GitHub Issues
]]>claude4.5 免费版
gemini3 pro 是 ai studio 的免费版
gpt5.2 是开通的 plus 会员的 thinking
对比下来,感官上,gpt5.2 生成的文档,在文章结构和逻辑条理上会更加丰富一点。
所以,仅就八股类的知识来说:
我个感官上的排序就是:gpt5.2 >= gemini3 pro >= claude4.5
仅作一点个人的小分享。 ]]>
图一是备份时的日志,图二是还原时的报错。
也试着跑了下文件的完整性检验,检验也是失败的