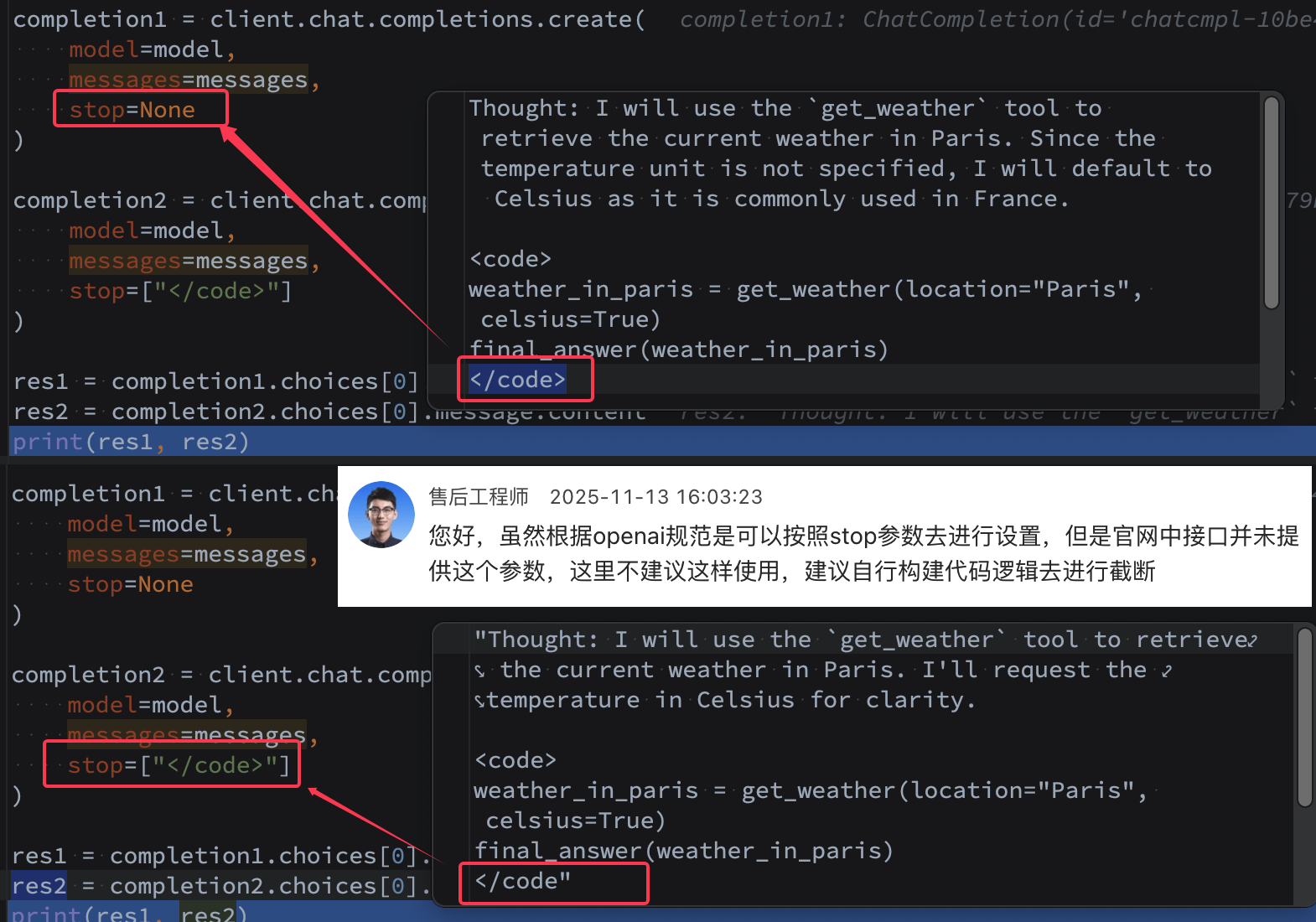
不知道是否有针对中文训练好的模型或者权重呢,如果能支持 Whisper-faster Whisper.cpp 就更好了
]]>现在每日消耗 200 美金,特来寻找有没有便宜的渠道.
每日 TOKEN 消耗数量 565,586,671 ]]>
有开发和行业调研及一堆乱七八糟的需求,在 gemini 使用过程中,发现对比较新的信息偶尔混淆,做一些调研报告的时候人工审核的工作比较多,生成技术方案等投标用的材料 上下文长度也有限。
现在计划开 gpt plus 会员,想知道
1.gpt plus 对比 gemini 体验如何
2.gpt plus 和 gpt 的 pro 版本对比,差距大吗
3.gpt plus 和 pro 有什么靠谱且便宜的开通渠道,重点是便宜,我很想试一下 pro ,但闲鱼拼车还得 1 月一续 ]]>
“Compare two numbers, 3.8 and 3.11.”
Sure! When we compare the two numbers, 3.8 and 3.11, we look at their decimal parts. The number 3.8 is the same as 3.80, and when we compare 3.80 to 3.11, it’s clear that 3.80 is greater than 3.11. So, 3.8 is larger than 3.11. ]]>
真心求问 V 友: 你们现在用啥 AI 工具玩股票?是券商自带的还是第三方插件? 实测下来靠谱吗?有没有能稳定跑赢大盘的小技巧? 怎么避开 AI 的坑?比如数据滞后、踩雷这些问题怎么解决? 是让 AI 给策略,还是只用来做辅助分析? 不管是赚了还是亏了,都来聊聊真实体验吧!救救咱们这些散户!
]]>不知道 pro 订阅是不是能效果好一些?
]]>在相同网络环境、相同设备、相同时间段下进行测试,得到如下结果:
个人账号(已开 Teams ) Teams 工作区账号
以上两类账号:当前最多仅可调用 GPT-4.0 模型
而在完全相同网络条件下: 切换登录其他 Teams 账号 or 个人账号可正常使用 GPT-5.2 模型
由此可以基本排除:IP / 网络环境问题客户端或地区限制问题
且在多方客户端同时进行测试
均指向 ChatGPT 引入黑号机制
]]>


 ]]>
]]>