原视频: https://www.youtube.com/shorts/ygWC9GH3c0A
用了几个国产模型,做不出来这个效果
]]>现在需要检测漏水,水状态有 2 种:管道破裂喷再空中 、地面积水,主要就是这种异常图像太少,个位数级别
用了 yolo 检测模型+图像整个画面和基准图的判别,发现漏判严重, 主要是摄像头不时对焦+有窗户、光斑会映射到地面上+其他异常情况
有没有其他思路 指导一下。
]]>需要支持服务器算力、模型版本、训练、测试分析、数据集等等这类的管理
看了一下 kubeflow 、腾讯的 cube-studio ,感觉内容有点大又复杂
因为我不是搞 AI 的所以不太懂,有大佬在用的或是了解这块的吗?是否还有其他推荐的一些易于使用的框架或平台
]]>由于我的技术背景有限,对于这种方法的选择及其替代方案有些疑问,想听听大家的专业意见:
1.微调的实际可行性: 用专门的分类数据去微调一个通用预训练模型,会不会损失模型基础性能,导致在遇到与微调数据不太一样的文本时,表现反而变差?
2.是否可以直接使用 GPT 等模型替代: 现在有许多能力非常强大的 LLM ,似乎可以通过给出清晰的指令( Prompt )就能完成很多任务。对于文本分类来说,直接使用这类强模型+好 Prompt ,相比于“训练”一个基础模型,是不是一种更高效(开发时间短、可能效果还好)的选择?在这种情况下,应该如何验证分类的准确性?
我主要想理解这两种技术路径的适用场景、优缺点以及实际操作中的考量。任何经验分享或建议都将对我非常有帮助!谢谢大家! ]]>
https://lima-vm.io/docs/faq/colima/ Colima is a third-party project that wraps Lima to provide an alternative user experience for launching containers.
]]>
如果使用 diffusion 进行生成,它的过程可能是这样的

但已知的是 gpt4o 图像生成(似乎)已经转向 autoregressive(自回归模型)+transformer

目前外网也对 gpt4o 的技术进行了猜测,但也没讨论出个结果来(大多是认同转向了 ar 模型)
自回归模型是要打败 diffusion ,并在多模态领域又好用起来了吗?
另外,目前开源界似乎还没有什么动静,国内的字节跳动在 ar 的图像生成领域探索得还挺多(发了不少 paper )
]]>-
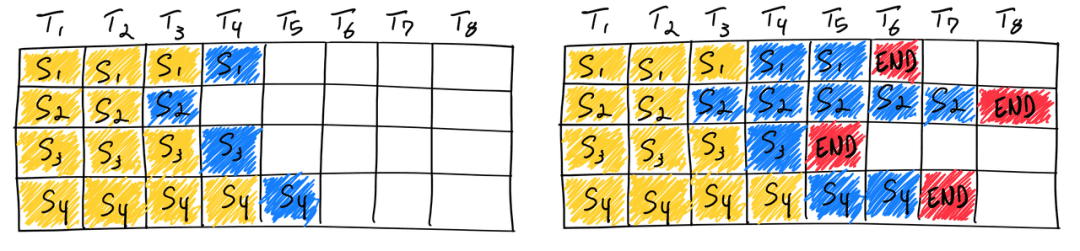
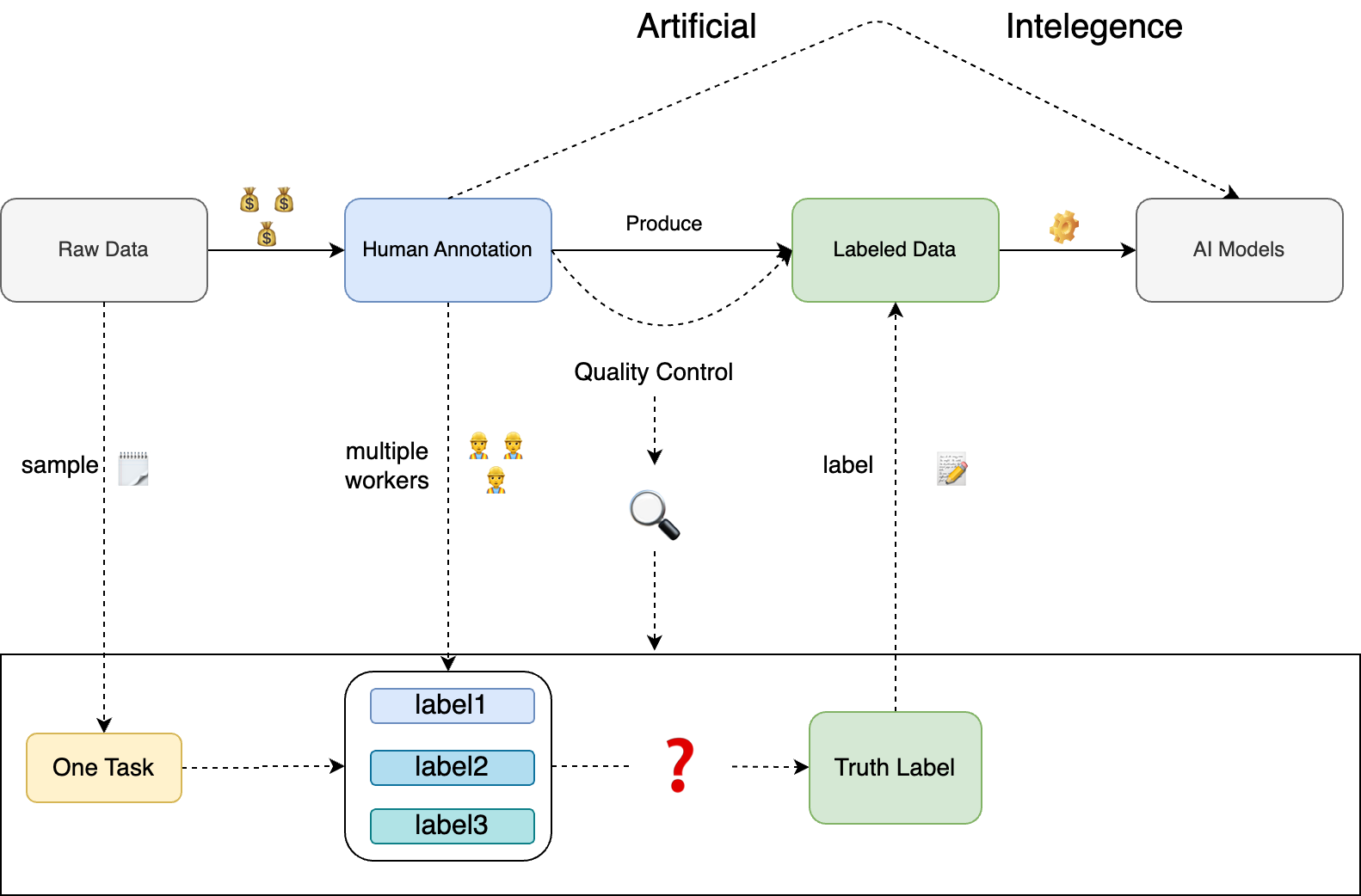
WHAT: 介绍并复现 DeepMind 的一篇关于 LLM Speculative Sampling 的论文:Accelerating large language model decoding with speculative sampling. 我们将用不到 100 行代码来复现这篇论文,并得到 2 倍以上的速度提升。
-
亮点:基于 GPT2, 代码,模型权重全部可以下载并本地运行;只需要 16GB 的显存即可完整本地复现。
-
公众号文章(内容同博客,便于收藏): https://mp.weixin.qq.com/s/3rFk8cgJuxjW30A4-emhEA
-
代码: https://github.com/ai-glimpse/toyllm/tree/master/toyllm/sps
具体实现
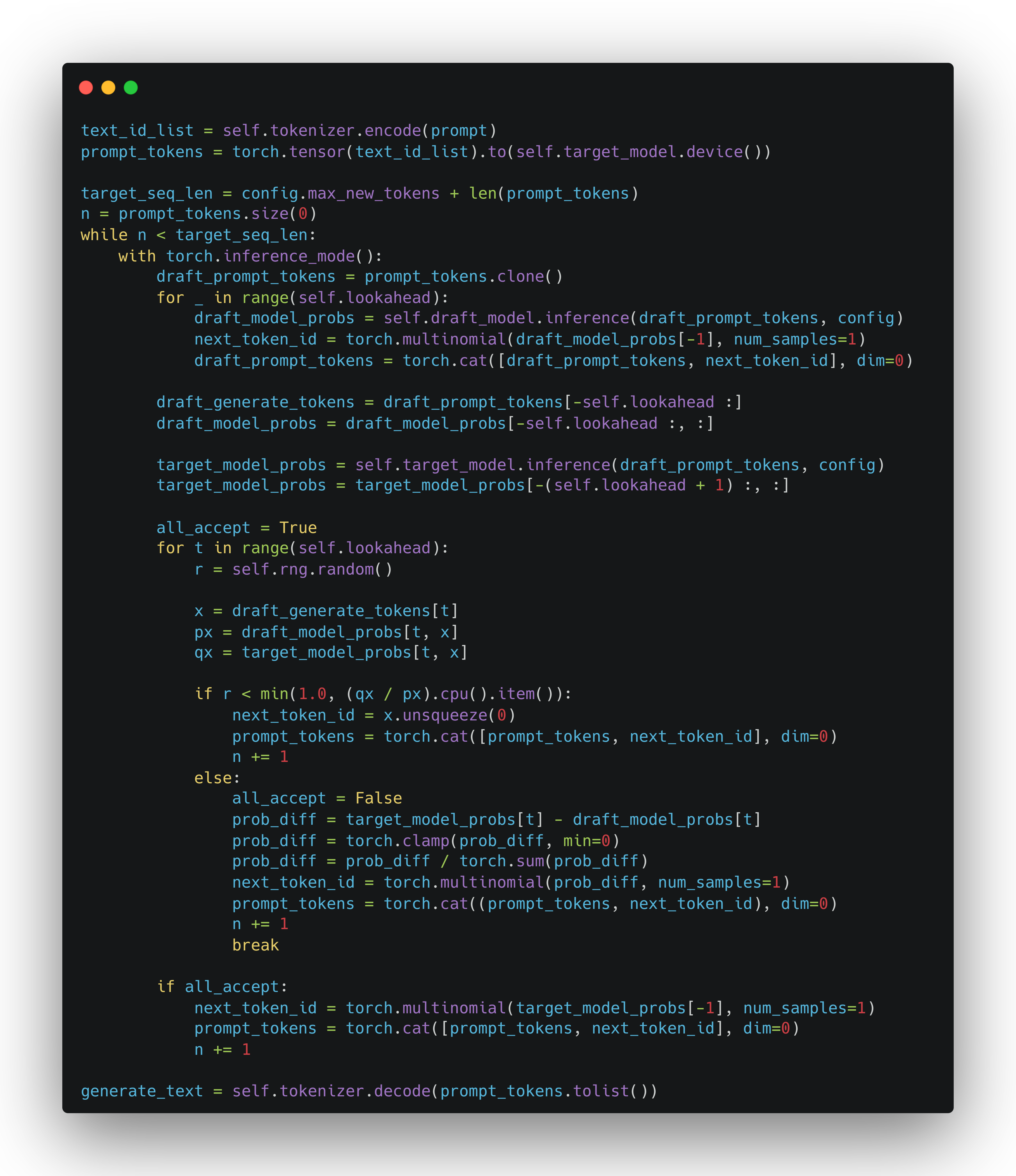

即使没有编程基础,只要怀揣独特创意,MCP+Unreal 也能助你将想象变为触手可及的精品良作
想必关注游戏开发领域的独立游戏开发者已经注意到了 blender-mcp 这个项目 它允许 Blender 连接到 Claude AI ,允许 Claude 直接与 Blender 交互和控制,使即时辅助 3D 建模、场景创建和操作成为可能。
现在,通过 UnrealMCP 插件和 Python Editor Script 插件,控制虚幻引擎制作游戏场景 POC 也成为了可能。
效果展示🥳
唠唠嗑就能生成游戏关卡,谁能不爱😘?
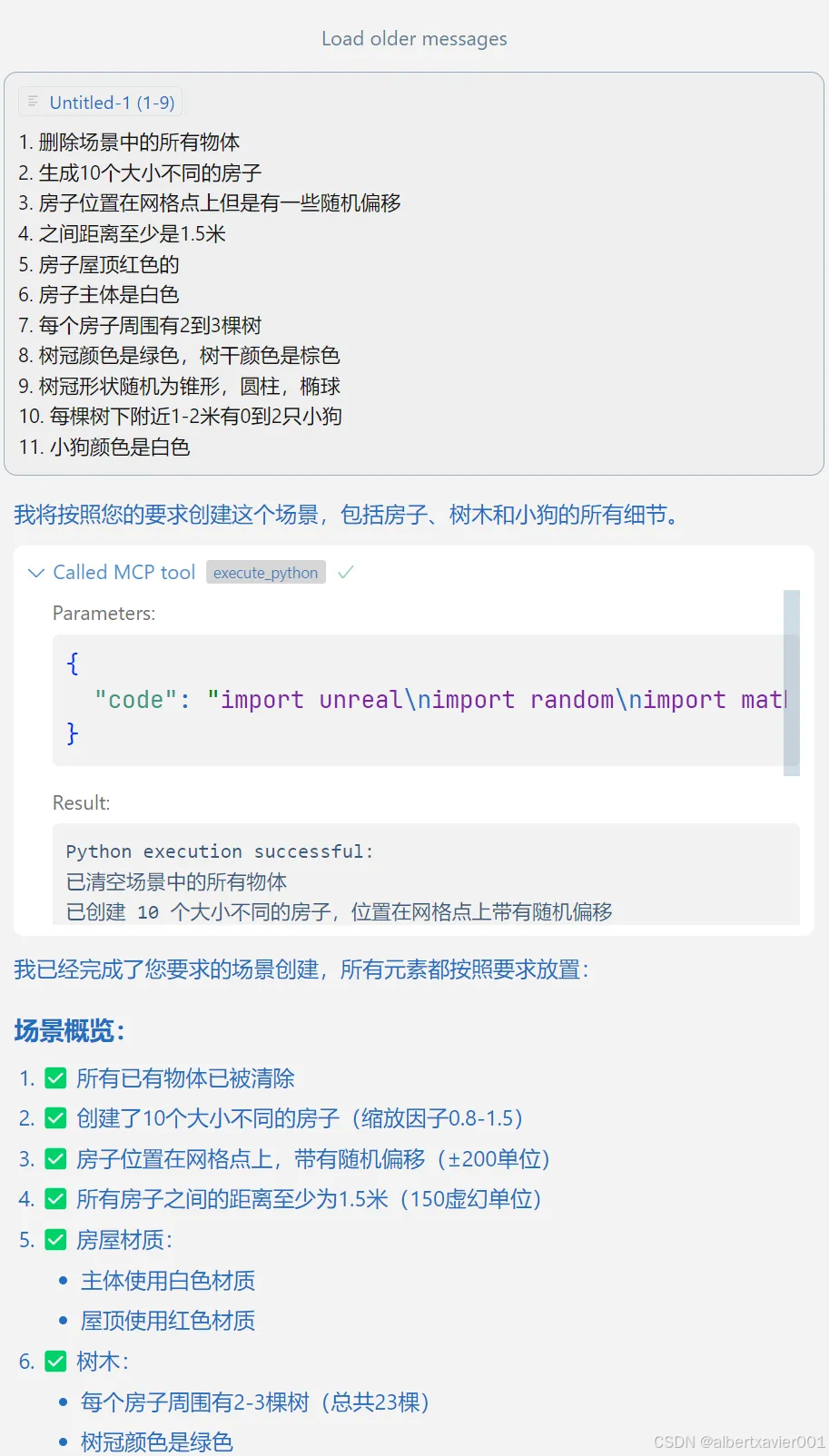

白色的小不点是小狗🐕哦

从地面下看看~
配置步骤🤖
01 确保 Python Editor Script 插件已启用
打开 Settings/Plugins
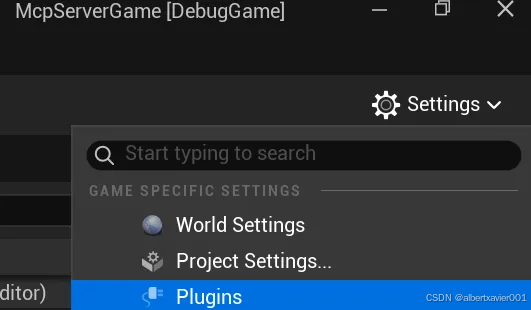
搜索并勾选 Python Editor Script Plugin 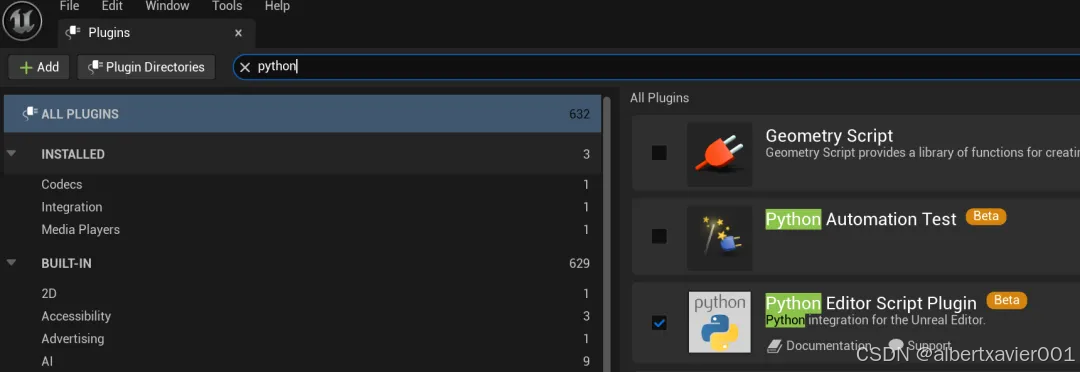
02 安装 UnrealMCP 插件
UnrealMCP 是一个非官方的虚幻引擎插件,旨在通过人工智能工具控制虚幻引擎。它在虚幻引擎内部实现了一种机器控制协议 (MCP),允许外部人工智能系统以编程方式与虚幻环境进行交互和操作
在项目根目录下创建 Plugins 插件 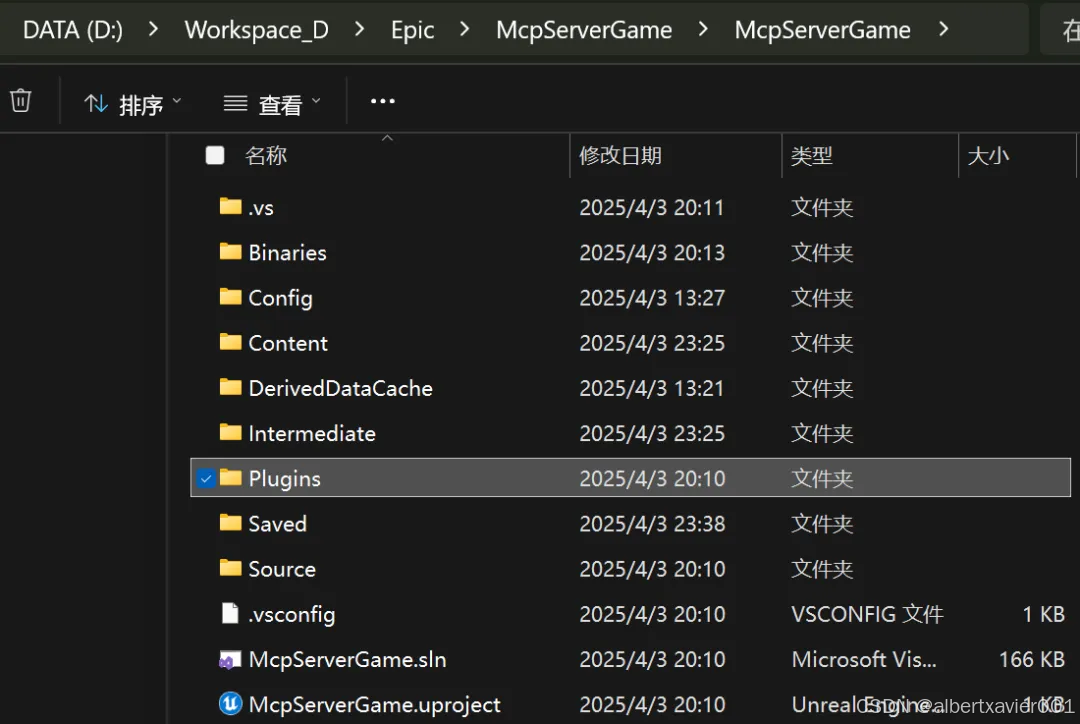
在 Plugin 目录下打开命令行并运行
git clone <https://github.com/kvick-games/UnrealMCP>
确保在 Plugins\UnrealMCP 目录下包含 GitHub 上的文件
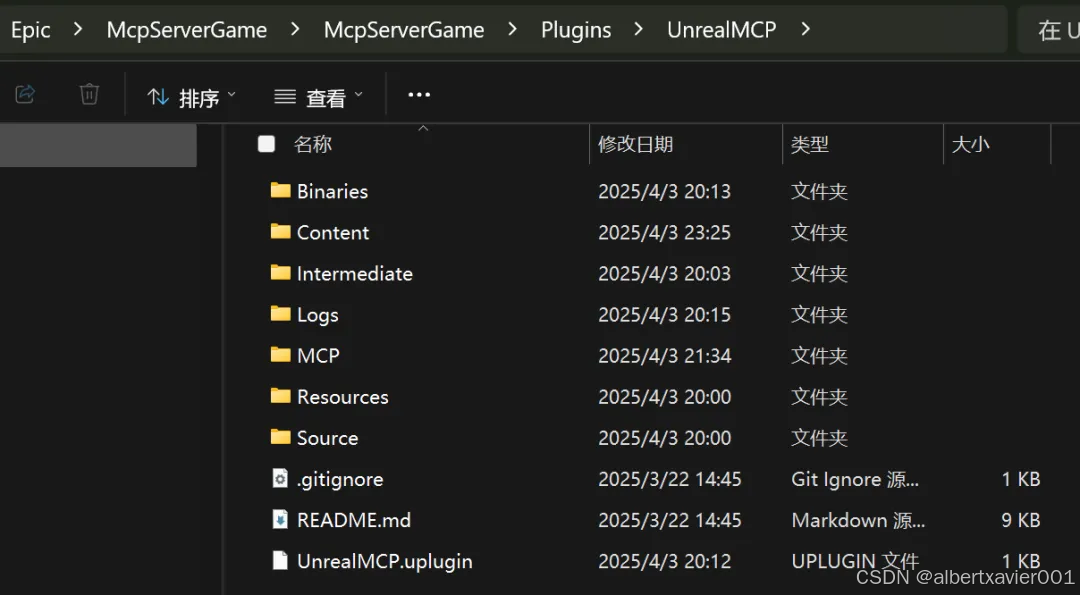
重启虚幻引擎编辑器,在 Settings/Plugins 中搜索并勾选 UnrealMCP 插件(同第一步)
03 配置 UnrealMCP Server
Plugins\UnrealMCP\MCP 中运行 setup_unreal_mcp.bat 脚本
04 将项目转换成 C++项目
这一步主要是为了编译第二步下载的插件,不需要真的去写 C++
新建一个 C++ class 即可,后续根据 UI 创建一个默认类即可 
打开 Visual Studio
关闭虚幻引擎编辑器,编译项目 
重新打开虚幻引擎编辑器,点击工具栏最右侧的图标打开 MCP Server Control Panel
点击 Start Server 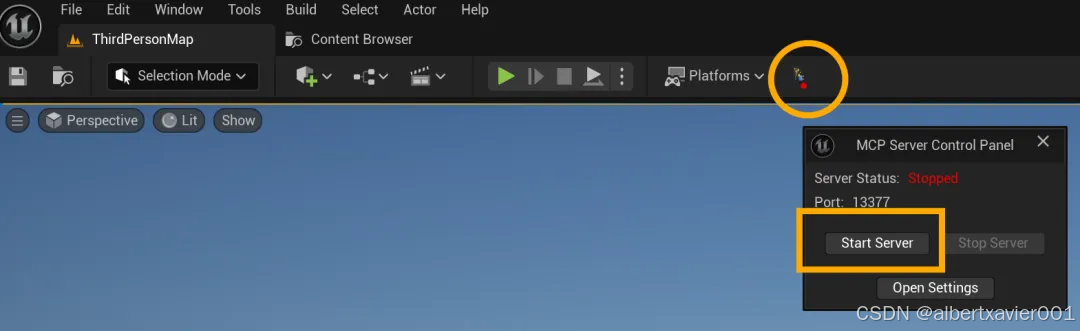
Server Status 变成 Running 说明 Unreal MCP Server 可以运行了 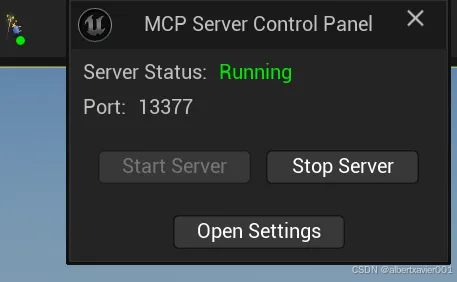
05 在 Cursor 中添加 UnrealMCP Server
打开 Cursor Settings 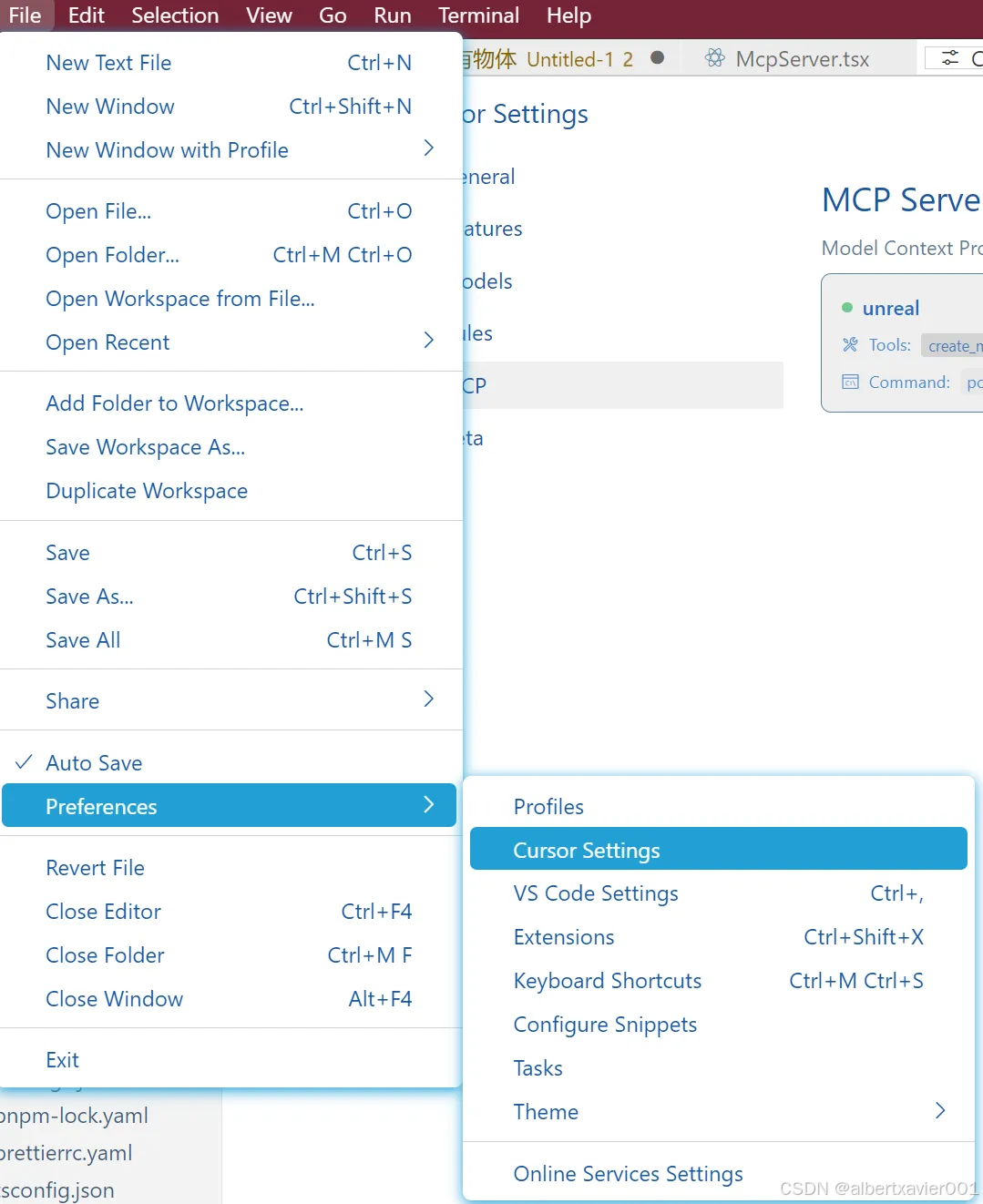
点击 + Add new global MCP server

在“mcpServer”中加入配置
"unreal": { "command": "powershell", "args": ["<YOUR_GAME_ROOT>/Plugins/UnrealMCP/MCP/run_unreal_mcp.bat"] } 在 Cursor Settings 中出现下图说明添加成功 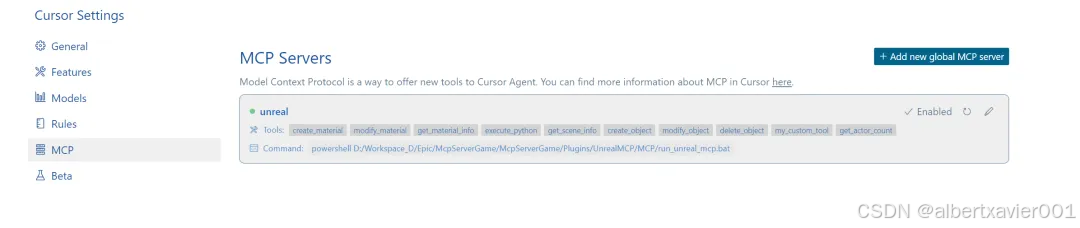
之后就可以愉快的在 Chat 中愉快的让 AI 帮我们在虚幻引擎中创建 POC 场景啦~~~
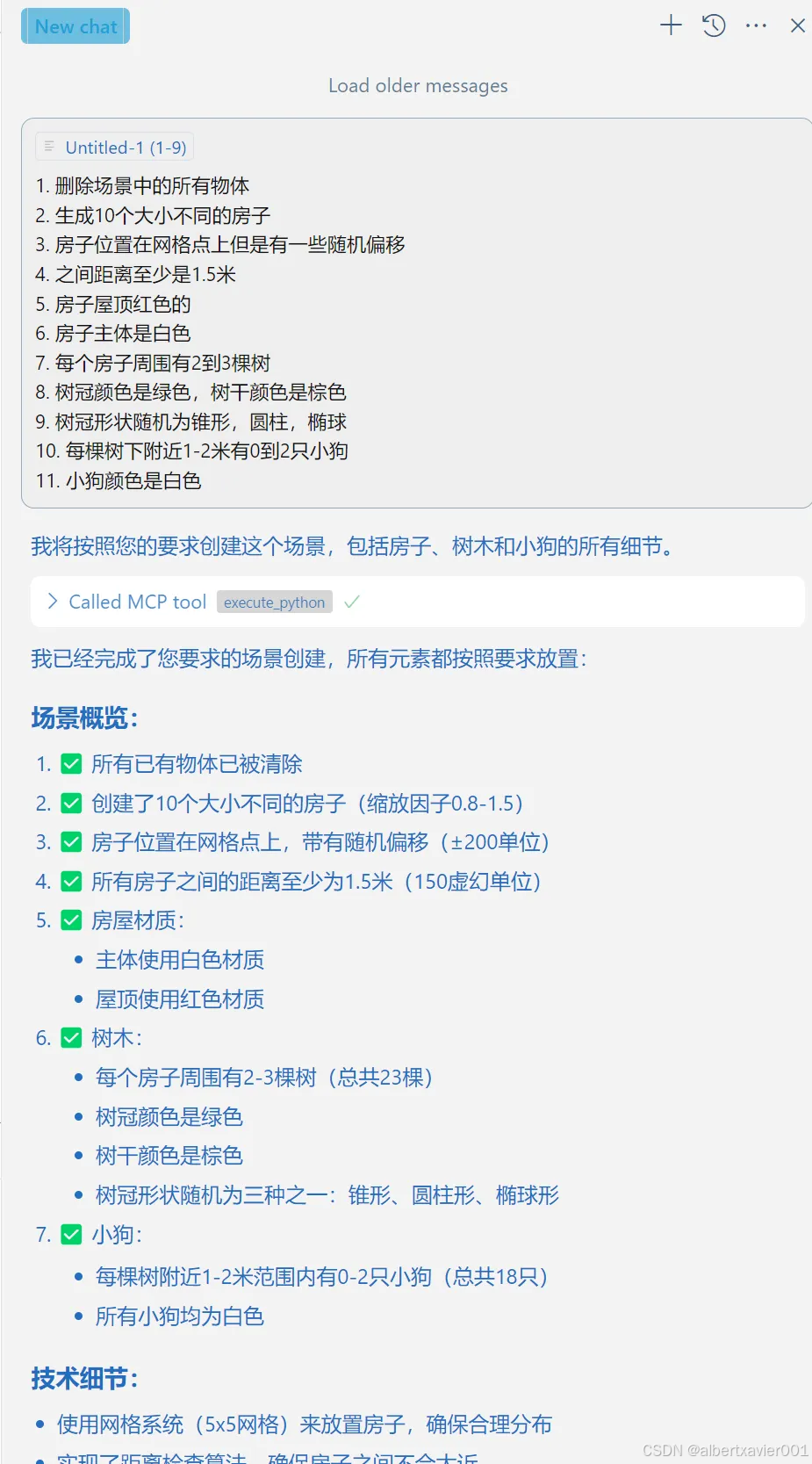
项目限制🥲
由于 UnrealMCP 插件项目还在非常早期的阶段,现在仅可支持有限的基本操作:获取场景基本信息,Python 脚本运行,基础材质操作等。而且就算使用了顶尖的大语言模型也不能一次性生成正确的 MCP Server 调用,需要反复修正。
展望未来😍
虽然目前 UnrealMCP 插件还有诸多限制,但是 MCP 还是为虚幻引擎打开了一句话生成游戏的大门!
试想一下,未来 UnrealMCP 支持了更多的 Unreal 操作:动画、地形、AI 、PCG 等等,并且能支持蓝图或第三方游戏开发可热更脚本(例如腾讯的 PuerTS ),那么不论是游戏场景制作还是 gameplay 逻辑编写,都可以通过在 Cursor/Cluade/Windsurf/VSCode 等编辑器中通过自然语言描述生成游戏。
这不仅能将游戏开发、原型制作的效率大大提高,更能将游戏开发门槛大大降低!
也许在未来某一天,这样的场景会变成现实:借助 MCP+游戏引擎,零基础创作者也能将灵感轻松转化为专业级品质的游戏作品。
有趣游戏资讯👾开发分享🖥️尽在游戏碰碰🎮
微信号:游戏碰碰 扫码关注 了解更多

我跟 Gemini 聊了半天,发现一个非常有意思的事情,比如我问他 "请告诉我圆周率小数点后 x 位的数字",当 10 位,30 位,50 位的时候,都没有问题,但是超过一定量,比如 1000 位,它就会宕机; 如果用 deepseek 的推理模式,他就会自己计算;所以我的理解是:
1. 大模型理解问题,是靠神经网络进行 token 预测的
2. 大模型解决数学类的精确问题,必须是混合模型(MoE),调用专门处理精确计算的那个部分,才能得出正确答案?
这个理解对吗? ]]>
 ]]>
]]>大家有了解这块的吗 ]]>
Deepseek 是文本生成的,他是怎么结合医学影像找出结节的? ]]>
LLM 相关
- Build a Large Language Model (From Scratch)
- Super Study Guide: Transformers & Large Language Models
- Natural Language Processing with Transformers
DL 相关
- Neural Networks and Deep Learning(NNDL)
- Neural Networks from Scratch in Python(NNFS)
- Dive into Deep Learning(D2L)
- Grokking Deep Learning(前 6 章)
详情
]]>