
初学者有很多基本的概念和理念还没有搞清楚,所以这可能是一个非常蠢的问题。求有经验的大佬们点拨一二
]]>请问部署方式是选择仅部署一个 datanode ,让这个 datanode 使用 10 块磁盘?
还是部署 10 个 datanode ,每个 node 仅使用一块磁盘?
请问两种姿势各有什么优势和缺点呢? ]]>
 hbase-env.sh 配置
hbase-env.sh 配置 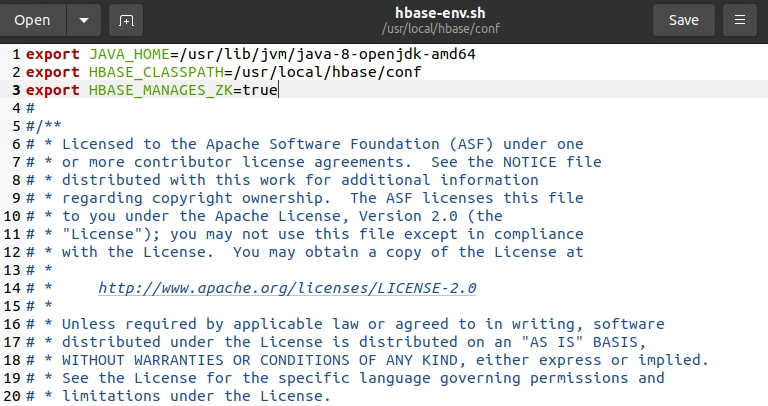 hbase-site.xml 配置
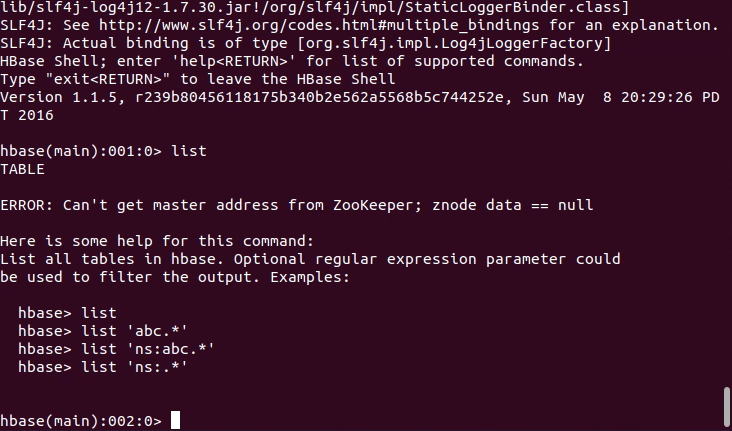
hbase-site.xml 配置 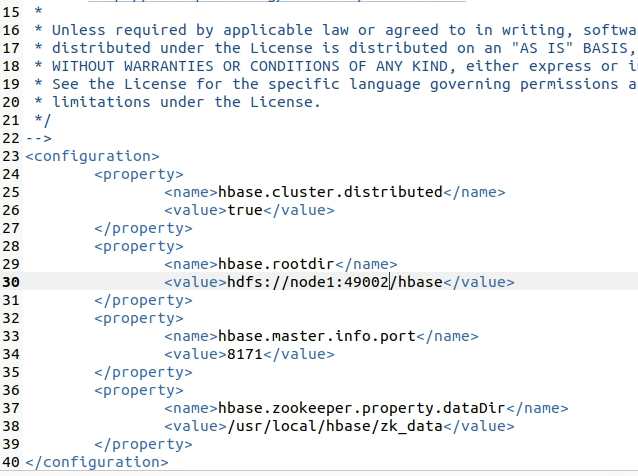 jps
jps 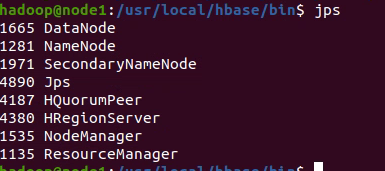 ]]>
]]>难道要自己下 Apache 的发行版,纯手工部署么
]]>mapreduce.application.classpath,而该值中使用了环境变量HADOOP_MAPRED_HOME。 实际上,我在没有手动设置HADOOP_MAPRED_HOME的情况下,里面的 example 还是能够正常运行。所以 Hadoop 内部是如何得到HADOOP_MAPRED_HOME的默认值的?
此外,即使是在 Hadoop 2 中,配置文件里面也有mapreduce.application.classpath这个属性,只是文档里面没有让设置。那么,究竟是什么场景下需要用到这个值?
遇到的问题:
hbase 的服务端 rpc 频繁超时, 导致数据堆积
已采用的方案:
与服务端沟通, 增加 hbase 离线集群,增加服务端数量(结果: 轻度缓解超时问题, 但仍未解决问题)
待选方案:
1. 更换存储, 改为 mongodb 或者其他存储
2. 直接把数据写入到 hive 表(这里想请教一下两个问题:1. hive 表中外部表和内部表在读写性能方面是否有区别,2. hive 表的写入效率如何, 是否能支持 100w/天的写入效率)
想请教一下各位大大, 待选方案是否可行, 以及是否有更好的解决方案 ]]>
• 轻松愉快的工作氛围,众多优秀以及 nice 的小伙伴 • 超长的假期 —— 每年 15 天年假起,每工作满 1 年加一天(最多 20 天);除此以外,工作满 5 年还将获得额外的 4 周带薪假期!以及 15 天带薪病假等等等。 • 包容、多元以及国际化的公司文化 • 市值 2000 亿美元,全民持股,股票激励,薪酬不输 996 公司的“福报”。work-life balance,生活不应只有加班。
PayPal 的大数据组会做什么?
At PayPal Global Data Science(GDS) team, we develop machine learning platform and AI applications to improve PayPal’s global business. Machine learning and AI is one of the core competitive advantage of PayPal, which significantly reduced payment risk loss, brought million dollars’ revenue and expanded to multiple domains rapidly. As an engineer in GDS, you will work closely with analytical team, understand the requirement with cutting-edge algorithm, contribute to the core platform, make the research work to a real product. We are looking for strong technologists who are passionate to solve machine learning problems and able to continuously deliver AI solutions in scalable way.
这个职位的要求是什么?
Qualifications • BS, MS, or PhD in Computer Science or related technical discipline (or equivalent). • 8+ years’ work experience in software development area with at least 5+ years’ experience in Java programming. • Excellent understanding of computer science fundamentals, data structures, and algorithms. • Excellent problem solving skills, can triage and resolve critical tech issues without supervision. • Expertise required in object-oriented design methodology and application development in Java. • Experience in big data technology such as Hadoop/Spark/Pig/HBASE/Streaming • Mastering at least one scripting language such as Unix Shell/Python/Perl/JS • Hands on web application development skill (HTML5/CSS/JS) is a very big plus • Knowledge on Machine Learning application pipeline is a very big plus • Proven results oriented person with a delivery focus in a high velocity, high quality environment. • Strong communication skills in Oral and Written English. • Working Experience in Multi-national Company is a plus. • Geek style is a big plus.
还有附加!!!!!!!!:
如果有兴趣的小伙伴,同时又有点担心年终奖的损失的话。 不用担心!基于面试情况,PayPal 会考虑给予额外奖金或者 Sign-On Bonus 之类减少你的年终奖损失, 让你在年底既能轻松搞定新的 Exciting 的工作机会,又能即时得到一些补偿,何乐不为呢? ]]>
-
在之前公司轻微接触过 hive,es 等(之前公司是分布式,机器还不少),不过本职是抓数据入 kafka 以及部分从 MySQL,MongoDB 之类的数据库做数据处理,一般只是给研究部门用。所以对于数仓之类的操作也只是见同事用,自己操作次数为个位数,各种工具的概念也只是一知半解,我觉得这样的就称之为不会。
-
现公司是传统公司,在一个互联网部门,并且各种氛围个人觉得较老套,技术流程什么的相对不那么'互联网'(不过好处就是项目不那么着急,准时上下班)。所以整个公司就只有一台 linux 服务器(都用 Windows 服务器),还是我申请来的..不过没那么重要了,有的 linux 用就很满足了(来之后一直在用 windows,还不是特别习惯)。
需求
-
领导想要把公司各个业务的数据汇一起,做个数据仓库,短期需求就是各个业务部门从这里取数据,只取历史速度要求不高。长期希望做一些大数据应用。
-
数据量的话,目前业务大多使用 sqlserver 和 oracle,也没什么问题(明天问一下 dba )。大概不是很大。
想法和问题
-
想自己动手搭起来但是苦于几个问题:
1.有无必要用 hadoop 生态的东西,而且是单机,没必要的话我也想自己试着动手(反正项目也不急,而且之前的工作太简单了,觉得太无聊了。项目用什么技术领导也不懂也无所谓),或者有没有其他的工具?
2.一直主要用 python,java 只知皮毛,当然能借此学 java 进步一下也可。但是有没有 python 比较紧密的工具?
总之就是想用这个机会学习动手点新东西而且做好,但是这个架构什么的对我来说还是比较难,所以想得到各位大佬的建议
]]>但是程序依旧不能正常运行。
问题详细: https://bbs.csdn.net/topics/396194270?page=1#post-411038079
]]>问题是:拷贝过来的配置文件,里面涉及到端口的内容(对外的 web 端口和内部通信端口)需不需要调整?还是保持原来的配置?
]]>我之前使用的集群,在 sqoop 导入、create、insert 等操作,都会将大的表格分割为 100-200M 的小文件。但目前所用的 hadoop 集群上面操作时,永远是在原文件上 append,导致文件越来越大,hdfs dfs ls 查看到表格仅由单个文件组成,个别表格文件大小甚至可能超过数十 GB。
我个人也不知道是否因为这个原因导致速度非常差。
请问是否有配置需要修改?有没有可能对现有表格进行分割? ]]>
- 公有云环境搭建,但是费用有点贵。
- 树莓派,有些如
redis搭建起来要至少 6 个节点,感觉也很吃钱。另外都得上散热,也是个问题。 - Docker。目前很多如 Zookeeper、hadoop 这些似乎都有镜像可以使用,不过 Docker 毕竟不是真的节点,目前正在踩坑。
- 虚拟机。本子不够好,开很多虚拟机内存消耗吃不起。
Java 后端入门小生,很多的中间件、框架等都需要分布式环境,希望各路大神分享下宝贵意见!
]]>为什么不可以随机指定一个活跃节点作为 leader 节点呢? 使用算法进行选举有什么好处?
]]>但是没找到获取全部 namenode(主备模式,两个 namenode)信息的接口。
怎样用代码获取全部 namenode 的节点信息呢?
]]>19/04/03 21:44:35 INFO mapreduce.Job: The url to track the job: http://cdh1:8088/proxy/application_1553483085921_3757/ 19/04/03 21:44:35 INFO mapreduce.Job: Running job: job_1553483085921_3757 19/04/03 21:44:40 INFO mapreduce.Job: Job job_1553483085921_3757 running in uber mode : false 19/04/03 21:44:40 INFO mapreduce.Job: map 0% reduce 0% 19/04/03 21:44:45 INFO mapreduce.Job: map 100% reduce 0% 19/04/03 21:44:45 INFO mapreduce.Job: Job job_1553483085921_3757 failed with state FAILED due to: Task failed task_1553483085921_3757_m_000003 Job failed as tasks failed. failedMaps:1 failedReduces:0
19/04/03 21:44:45 INFO mapreduce.Job: Counters: 13 Job Counters Failed map tasks=1 Killed map tasks=3 Launched map tasks=3 Data-local map tasks=2 Rack-local map tasks=1 Total time spent by all maps in occupied slots (ms)=40720 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=5090 Total vcore-milliseconds taken by all map tasks=5090 Total megabyte-milliseconds taken by all map tasks=41697280 Map-Reduce Framework CPU time spent (ms)=0 Physical memory (bytes) snapshot=0 Virtual memory (bytes) snapshot=0 19/04/03 21:44:45 WARN mapreduce.Counters: Group FileSystemCounters is deprecated. Use org.apache.hadoop.mapreduce.FileSystemCounter instead 19/04/03 21:44:45 INFO mapreduce.ExportJobBase: Transferred 0 bytes in 12.0892 seconds (0 bytes/sec) 19/04/03 21:44:45 INFO mapreduce.ExportJobBase: Exported 0 records. 19/04/03 21:44:45 ERROR tool.ExportTool: Error during export: Export job failed! at org.apache.sqoop.mapreduce.ExportJobBase.runExport(ExportJobBase.java:439) at org.apache.sqoop.manager.SqlManager.exportTable(SqlManager.java:931) at org.apache.sqoop.tool.ExportTool.exportTable(ExportTool.java:80) at org.apache.sqoop.tool.ExportTool.run(ExportTool.java:99) at org.apache.sqoop.Sqoop.run(Sqoop.java:147) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183) at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234) at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243) at org.apache.sqoop.Sqoop.main(Sqoop.java:252)
]]>| Error: Unable to find a compatible version of Java on this host,|
| either because JAVA_HOME has not been set or because a |
| compatible version of Java is not installed. |
+----------------------------------------------------------------------+
| Please install either: |
| - a supported version of the Oracle JDK from the Oracle Java web |
| site: |
| > http://www.oracle.com/technetwork/java/javase/index.html < |
| OR |
| - a supported version of the OpenJDK from your OS vendor. Help for |
| some OSes are available at: |
| > http://openjdk.java.net/install/ < |
| |
| Cloudera Manager requires Oracle JDK or OpenJDK 1.8 or later. |
| NOTE: Cloudera Manager will find the Oracle JDK when starting, |
| regardless of whether you installed the JDK using a binary |
| installer or the RPM-based installer. |
+======================================================================+
error: %pre(cloudera-manager-server-6.2.0-968826.el7.x86_64) scriptlet failed, exit status 1
Error in PREIN scriptlet in rpm package cloudera-manager-server-6.2.0-968826.el7.x86_64
验证中 : cloudera-manager-agent-6.2.0-968826.e 1/3
验证中 : cloudera-manager-daemons-6.2.0-968826 2/3
验证中 : cloudera-manager-server-6.2.0-968826. 3/3
已安装:
cloudera-manager-agent.x86_64 0:6.2.0-968826.el7
失败:
cloudera-manager-daemons.x86_64 0:6.2.0-968826.el7
cloudera-manager-server.x86_64 0:6.2.0-968826.el7
只要是 sudo,就会报这个错,如果 su - root 后,就可以成功。
新手上路有点懵,一般情况下 root 用户都不大用的啊。 ]]>
我本来以为 zookeeper、hbase 都应该全集群部署,hive 是哪个机器需要用,就装在哪个机器。
但是看了几个帖子,发现有人是部分机器部署部分功能。
新手,不懂,请大佬指点,谢谢。
上面提到的帖子
https://blog.csdn.net/lepton126/article/details/60866664 ]]>
之前是好的。重启之后突然不行了。非常奇怪
Error: Another program is already listening on a port that one of our HTTP servers is configured to use. Shut this program down first before starting superv isord.
[08/Mar/2019 09:18:07 +0000] 98011 MainThread agent INFO SCM Agent Version: 5.14.2 [08/Mar/2019 09:18:07 +0000] 98011 MainThread agent INFO Re-using pre-existing directory: /opt/CDH/cm-5.14.2/run/cloudera-scm-agent [08/Mar/2019 09:21:21 +0000] 98463 MainThread agent INFO SCM Agent Version: 5.14.2 [08/Mar/2019 09:21:21 +0000] 98463 MainThread agent INFO Re-using pre-existing directory: /opt/CDH/cm-5.14.2/run/cloudera-scm-agent [08/Mar/2019 09:54:53 +0000] 2843 MainThread agent INFO SCM Agent Version: 5.14.2 [08/Mar/2019 09:54:54 +0000] 2843 MainThread agent INFO Re-using pre-existing directory: /opt/CDH/cm-5.14.2/run/cloudera-scm-agent [08/Mar/2019 10:15:19 +0000] 2482 MainThread agent INFO SCM Agent Version: 5.14.2 [08/Mar/2019 10:15:19 +0000] 2482 MainThread agent INFO Re-using pre-existing directory: /opt/CDH/cm-5.14.2/run/cloudera-scm-agent [08/Mar/2019 10:30:21 +0000] 4208 MainThread agent INFO SCM Agent Version: 5.14.2 [08/Mar/2019 10:30:21 +0000] 4208 MainThread agent INFO Re-using pre-existing directory: /opt/CDH/cm-5.14.2/run/cloudera-scm-agent [08/Mar/2019 10:30:29 +0000] 4397 MainThread agent INFO SCM Agent Version: 5.14.2 [08/Mar/2019 10:30:29 +0000] 4397 MainThread agent INFO Re-using pre-existing directory: /opt/CDH/cm-5.14.2/run/cloudera-scm-agent
]]>自己写了一个简单的 MapReduce 应用。用来解析集群 HDFS 上面的一个文件内容。
本地在 idea 中调试,main 函数执行是正常的,很快可以跑出结果。
maven 打成 jar 包后,本地 hadoop jar 执行也是正常的。
但是拿到集群上面(一个小集群,一主二仆),再使用 hadoop jar 去运行就会一直卡住。
前面几行日志是正常打印的,但是到了
2019-02-14 16:02:34,991 INFO mapreduce.Job: Running job: job_1542766536312_0001
之后就挂在那里了,久久没有反应。
求指点,是我哪里操作有问题吗?还是可能哪里的问题?
多谢
]]>1 2 1 3 1 4 1 5 1 6 1 7 1 8 2 3 3 9 9 10 7 9 2 7 我想实现如下功能,求 3 节点与它的二跳节点的好友之间的共同好友个数,实现类似 QQ 好友推荐功能:
3 和 5 的共同好友个数为:1 3 和 10 的共同好友个数为:1 3 和 6 的共同好友个数为:1 3 和 7 的共同好友个数为:3 3 和 8 的共同好友个数为:1 3 和 4 的共同好友个数为:1 ———————————————————————————————————— 排序之后,这里可以给 3 推荐 7 认识。 - 简单的通过 for 循环(得到好友节点的会触发 action)算出这样的关系在 spark 中估计也没什么优势吧(千万节点,亿条关系)?但是求二跳节点通过 graphx 自带的 api 还是有很大优势的。
- saprk graphx 可以通过它自带的 pregel API 直接求出一个节点的一跳到 N 跳的节点。
- neo4j 一条语句实现如下:
match (n:Person {name:"A"})-[:Follow]->(m)<-[:Follow]-(b) with n,b,count(m) as summ where (not (n)-[:Follow]-(b) ) return b,summ - 腾讯的两篇文章参考
搭建过程和配置文件专门用 VuePress 记录了一下:前往日志
-
集群单个节点的配置:1VCPUs 2GB 5Mbps , 内存分配策略:参考了 Linode 的 2GB 节点配置教程
-
服务器用的廉价的阿里云的轻量应用服务器学生版,几个同学一人一台,拼凑了一个拥有 5 个节点的集群。
数据处理
任务
使用 Hive 导入社交用户数据 CSV 文件,使用 SQL 塞选出用户表中的共同爱好、共同好友。
Map Reduce 作业问题
在这个集群上做简单的 Map 和 Reduce 作业是极其缓慢的,从 0% 跳到 100%可能会经历数十分钟,效率堪忧。由于各个节点是同学自己买的,不能走 VPC 内网互通,只好用公网互通。👈怀疑问题会出现在这里
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2019-01-09 19:56:25,499 Stage-1 map = 0%, reduce = 0% INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 INFO : 2019-01-09 19:56:25,499 Stage-1 map = 0%, reduce = 0% 2019-01-09 19:57:26,238 Stage-1 map = 0%, reduce = 0% INFO : 2019-01-09 19:57:26,238 Stage-1 map = 0%, reduce = 0% 2019-01-09 19:58:26,818 Stage-1 map = 0%, reduce = 0% INFO : 2019-01-09 19:58:26,818 Stage-1 map = 0%, reduce = 0% 2019-01-09 19:59:27,374 Stage-1 map = 0%, reduce = 0% INFO : 2019-01-09 19:59:27,374 Stage-1 map = 0%, reduce = 0% 2019-01-09 20:00:27,878 Stage-1 map = 0%, reduce = 0% ... 2019-01-09 20:17:32,700 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.69 sec INFO : 2019-01-09 20:17:32,700 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.69 sec 2019-01-09 20:18:33,218 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.69 sec INFO : 2019-01-09 20:18:33,218 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.69 sec 测试
使用相同的 SQL 语句换做在 E-MapReduce 上能很块跑出结果(加钱世界可及)。
还未结束
- Q1: 同样的 2G 内存节点,在本地虚拟机上就能正常运行,不会在 MapReduce 作业上卡数十分钟
请问哪里有类似的书或者文章可以参考一下吗?
是通过将配置内容放在不同的配置文件中来完成作用域的控制,还是有其他的机制?
新手上路,请多指点,多谢 ]]>
环境:CDH 5.13.1,hadoop-2.6.0-cdh5.13.1,spark 2.2.0 社区版
Google 了一圈,加了 --conf spark.hadoop.fs.hdfs.impl.disable.cache=true,说是在 HDFS HA 模式下,必须关掉 cache 功能,但是加上了并没有什么用。
有遇到过类似 TOKEN 问题过期的大佬吗?指点一下
]]>我有一张预分区的 Hbase 表, split key 是 000| 001| ... 199|这样,200 个分区.
我的 rowkey 是这样设计的 001|20180928001122+ 业务 ID + 6 位随机数
这样设计的话避免了 Spark 读取时数据倾斜啊,插入时数据热点问题.
但是我想用 Spark 读取某一天的数据,还想用 scan 操作的话,貌似很难实现.
比如我的 startrow=001|2018092800 + 0000 + 0000 + 000000 endrow=001|2018092899 + 0000 + 0000 +000000
我想读取完这一天的数据,难道得循环 200 个 region 吗?
单机多线程的话是可以这么做的,但是我想用 spark 分布式环境来操作.
我查阅了 TableSnapshotScanner 类,对其 regions 属性不甚理解,望高手给个思路(给个 demo 最好了...
]]>任职资格 1.精通 Scala/Python 程序开发(至少一种),熟悉 Linux/Unix 开发环境; 2. 2 年以上分布式大数据开发、数据挖掘、机器学习等领域的开发经验; 3. 熟悉常用分类、聚类算法,如朴素贝叶斯,KNN,SVM,逻辑回归等; 4. 熟悉 Spark(Streaming/MLlib)、有 Hadoop 的分布式数据挖掘开发经验
有意者请联系 Claire 13751127682 (手机&微信) 简历可投递 Claire.Wei@elpcon.com
]]>select a."member_num", b."member_num_tb", a."member_num" / b."member_num_tb" from ( select count(distinct mobile) as "member_num" ,'week' as "dtype" from member where dweek <= '18.06.04~18.06.10' ) as a left outer join ( select count(distinct mobile) as "member_num_tb" ,'week' as "dtype" from member where dweek_tb <= '18.06.04~18.06.10' ) as b on a."dtype" = b."dtype" - 报错信息
That the right side of the BinaryTupleExpression owns columns is not supported for / while executing SQL: "select a."member_num", b."member_num_tb", a."member_num" / b."member_num_tb" from ( select count(distinct mobile) as "member_num" ,'week' as "dtype" from member where dweek <= '18.06.04~18.06.10' ) as a left outer join ( select count(distinct mobile) as "member_num_tb" ,'week' as "dtype" from member where dweek_tb <= '18.06.04~18.06.10' ) as b on a."dtype" = b."dtype" " 请问这是是什么原因啊?
]]>要求:英文口语流利,沟通好,8 年左右 Java 开发经验,2-3 年大数据开发经验,愿意落地做开发钻研技术。
如果有兴趣,欢迎加微信:littleicybingbing,或者直接发简历到 iliu@coupang.com
Chief Architect - Fraud Detection System (Director or Sr. Manager level) Coupang is one of the largest and fastest growing e-commerce platforms on the planet. Our mission is to create a world in which Customers ask, “ How did I ever live without Coupang?” We are looking for passionate builders to help us get there. Powered by world-class technology and operations, we have set out to transform the end-to-end Customer experience -- from revolutionizing last-mile delivery to rethinking how Customers search and discover on a truly mobile-first platform. We have been named one of the “ 50 Smartest Companies in the World ” by MIT Technology Review and “ 30 Global Game Changers ” by Forbes. Coupang is a global company with offices in Beijing, Los Angeles, Seattle, Seoul, Shanghai, and Silicon Valley. Who are We? FDS (Fraud Detection System) protects online transactions from fraudsters and abusers. We build highly sophisticated and analytics-based systems and services that scan massive amounts of transaction-related data (buyer, seller, payment, etc.) to uncover underlying correlations and detect fraud and abuse patterns, as well as tools and processes for operation teams to investigate and act on these. A robust FDS protects Coupang ’ s brand and image, prevents negative impacts to Customers and Sellers and reduces revenue loss. Our mission is to ensure that every transaction is trusted, safe, and protected from fraud. We build the brand image that Coupang is a trustworthy place to buy things and do business. By leveraging state-of-the-art Big Data technologies and machine learning expertise, we try to build a data-driven culture for fraud detection and risk management. We believe in the machine learning approach to fight fraudsters and protect our customers, and are the early adopters for Big Data and Machine Learning technologies at scale in the industry. We view Big Data and Machine Learning as our core strengths. We are a truly blended group with both aspired technologists and data scientists. Advanced analytics powered by strong engineering muscles creates solutions to one of the most compelling battles for e-Commerce company like Coupang. We ’ re the modern detectives hunting for fraudulent activities, but only with better weapons in our hands. Responsibilities: • Act as the chief architect/senior technical leader of the team throughout the software development life cycle • Lead team to develop high performance big data framework • Collaborate with product owners, stakeholders and other agile teams on business and product strategy from a technical and architectural perspective; • Collaborate with data scientist, verify and implement data models to realize automatic and accurate fraud detection; improve the risk management level of E-commerce/payment platforms; • Analyze information acquired and compare solutions and weigh them against the actual needs; provide root cause analysis affecting key business problems; • Play an active role in company-wide technical strategy; Qualifications: • Masters/PhDs in CS machine learning, Statistics, Applied Math or a quantitative field; • 10+ years software development experience with at least 5 years proven track record acting as the architect/leader/manager of mission critical enterprise software/e-commerce solutions • Excellent communication and presentation skills • Expert at one or more of program languages (JAVA, Scala, C, C++, etc.); • Experience in operation and development in Hadoop and other leading big data ecosystem (Spark, Hive, Pig, Sqoop, Oozie); • Experience with SQL (MySQL/Oracle/MSSQL/DB2 etc) &NoSQL(Redis/Cassandra/HBase/MongoDB); • Passion to learn new technologies • Will work with colleagues in Silicon Valley and Seoul. Overseas travel is required. • Fluent spoken and written English
]]>id from to 1 A B 2 A C 3 B A 4 C A 去重复后如下,
id from to 1 A B 2 A C 尝试的解决方案:
1、采用 bloomfilter 去重,由于 bloomfilter 本身算法问题,会丢失一些数据;
2、使用数据库查询然后写入到新表,速度有点慢。
3、使用 BerkeleyDB ?
4、使用 hadoop 或者 spark 解决,网上找到的方式几乎都是使用 group by 或者 distinct 但这并不适合我这个场景,如何解决呢?
头大。。。新手上路。。。
没太懂这一句,新手上路,请各位指教一下。
]]>cat 不是打印吗,后面跟这个>和>>是什么意思啊,求教
]]>修改 map-reduce 的 job.properties 如下:
nameNode=hdfs://localhost:9000 jobTracker=localhost:8032 queueName=default examplesRoot=examples oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/map-reduce outputDir=map-reduce 按照文档中的提示输入命令"oozie job -oozie http://localhost:11000/oozie -config examples/apps/map-reduce/job.properties -run"时报错:
Error: E0501 : E0501: Could not perform authorization operation, Failed on local exception: com.google.protobuf.InvalidProtocolBufferException: Message missing required fields: callId, status; Host Details : local host is: "Master/服务器 ip"; destination host is: "localhost":9000;
已经确认 nameNode 端口无误,在服务器 shell 键入"hadoop fs -ls hdfs://localhost:9000"会返回结果。,可以确认 oozie 的端口无误,浏览器输入“ http://服务器 ip:11000 ”可以进入 oozie 管理界面。jobtracker ip 应该没错,我在 yarm-site.xml 里没有看见端口的设置项,但是在"netstat -tunlp"中看见有 8032 端口在占用,这应该是 resourcemanager 的默认端口。 关键点可能在 Message missing required fields: callId, status 这个提示上,放狗搜看到有人说是 hadoop 版本太高接口不一致什么的,但是 oozie5.0 已经要求安装的 hadoop 最低版本在 2.6 以上。这让我很疑惑。 希望能得到一些指导,感谢。
]]>