非得重启一下才行? rm 之后变成空白目录了,就这还不能删 .....
]]>hot ,现在分享给 v 友,它支持很多的场景: - 你可以使用
hot size (原始大小)/hot az (近似压缩大小)查看仓库中的大文件。 - Git 存储库误提交了密码凭证等,可以使用
hot remove删除并重写历史记录,hot remove的重写速度特别快(通常比 BFG 之类的工具快)。 - 你也可以直接使用
hot smart交互式操作删除仓库中的大文件,它结合了size, remove命令(如:hot smart -L20m)。 - 你可以使用
hot mc将 Git 存储库的对象格式迁移到SHA256,也可以从SHA256的迁移到SHA1(应该是第一个 Git SHA256 迁移工具)。 - 仓库无效分支标签太多,可以使用
hot prune-refs (按前缀匹配)/hot expire-refs (按过期时间,是否合并)删除,亦可以使用hot scan-refs查看分支的情况。 - 你可以使用
hot unbranch将存储库的历史线性化,也就是不包含任何合并点。 - 你亦可以使用
hot unbranch -K1 master -Tnew-branch基于特定的版本创建一个孤儿分支,这将保留最近的历史,可用于开源或者重置历史场景。 - 你可以使用
hot cat查看存储库中的文件,commit/tree/tag/blob,其中commit/tree/tag可以使用--json输出成 JSON,blob则能智能的使用 16 进制输出二进制文件。
hot cat HEAD:docs/images/blob.png 比如你查看仓库的信息,可以这样做:
hot stat 将 Git 存储库对象格式从 SHA1 迁移到 SHA256:
hot mc https://github.com/antgroup/hugescm.git 之前在别的地方问的时候有人说用 git remote set-url --add --push origin 仓库地址,谷歌英文搜了一下也基本都是这个命令。但是这个命令好像有点问题,如果最开始是通过 VS Code 的图形界面添加到 github 的私有仓库,那么第一次运行那个命令的时候会替换远程仓库,不是添加,第二次开始才是添加。这个问题不大吧?我没试最开始通过其他方式添加远程仓库会不会也这样。还有我看 remote 命令的 man 文档好像没有明确说这个命令的 --add 参数是用于什么情况的。有点不敢用。毕竟关系到代码的安全,不敢能用就凑合用。
]]>分支情况如下图:
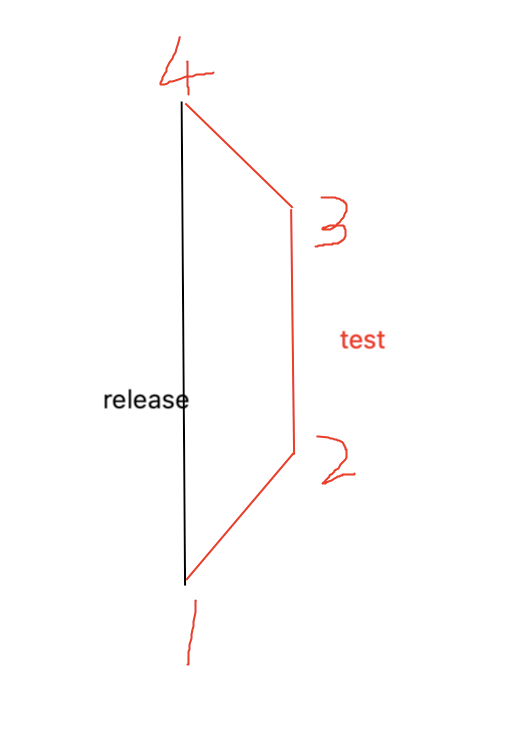
- 从
1创建新的test分支 - 在
test分支上分别进行了23提交 - merge test to release 的时候产生了
4提交 - 删除了
test分支
我现在想回退到 2来删除 3 4记录,是否能做到?如果可以的话,应该在哪个分支执行什么 git 命令。

我后面学着用这个压缩提交,可以将多个提交记录压缩成一个然后再合并到主分支上,但是用完之后提交记录变得更加诡异了,甚至会变成两个我有两个完全一样的提交记录,给我都整不会了,合并的时候也特别麻烦,审阅了很多东西,最后还让组长帮忙看看最终的内容有没有预期之外的修改才敢合并的,出了这事之后我就不敢再用压缩提交了
下面是提交记录,之所以有两个一样的提交就是因为当时用了压缩提交

后面我又跟组长学修正提交,可以修正前一个提交来解决问题,但是我用修正提交的时候有时候不知道为什么还是会触发自动合并和更新,最后虽然说可以效果没变化,但是提交记录还是变得很难看,具体来说如下图所示

到这里为止我是真没办法,不知道该怎么解决这个问题,有没有懂得大佬来说一下,虽然说这个问题也不影响开发,但是这么乱的记录我看着心里挺膈应就是
]]> ]]>
]]>比如:git status 、git log 等各种命令,基本上要等接近 1s 左右才返回。但是在 Linux 下却是瞬间就返回了,什么原因导致的?
然后我用 fork 这个 ui 工具,看 local changes 的时候点一个文件也要半天才加载出来
或者我点某个 commit 的时候,也要加载至少 1s 才能把这个 commit 的完整信息显示出来
还有就最近在编译 golang 项目的时候也要编译很久(至少分钟级),电脑配置是 64G i7-1365HX 。以前都是几秒就编译完成了。 编译的时候看电脑 CPU 和内存都不高
这咋办? 重装系统?
]]>我说的 remote 分支和已经 checkout 的分支的例子:
tony@tony-EQ1:/project/openwrt/trunk$ git branch -a
* master
openwrt-22.03
openwrt-23.05
remotes/origin/HEAD -> origin/master
remotes/origin/lede-17.01
remotes/origin/master
remotes/origin/openwrt-22.03
remotes/origin/openwrt-23.05
remotes/origin/openwrt-24.10
其中 master ,openwrt-22.03 ,openwrt-23.5 为已经 checkout 的分支,其余为 remote 分支,还没有被 checkout 。 ]]>
一处配置文件修改( 1 行代码)
两处修改是不相干的
要分开提交吗?
背后的问题是大家提交习惯是按照进度一次提交(有点备份的意思),还是按照功能细分提交(日志会很多)?
]]>git cp:没这号命令😂 git mv:这是改名 比如已有 a.txt ,我现在要个 b.txt 。 如何复制出 b.txt 这个文件,并且复制前的历史和 a.txt 保持一致?
还是说 和空文件夹 一样,git 不在乎你死活?
操作尽量简单,要是涉及的非基础知识点太多,还是算了,这历史不要也罢😂
]]>*提交的记录可以看这张大图,请大家看了这个大图再评论啊,感谢大家呀

*working 代码已提交如图,位于图片 2 位置 ,图片 1 位置是最新代码
点击 图片 1 位置 ,会对比 1 位置 和 5 位置 的差异
点击 图片 2 位置 ,会对比 2 位置 和 3 位置 的差异
*但是我想要对比 图片 1 位置 和 图片 2 位置 的差异,在 vscode 中无法直接查看对比。
*在前一个帖子里面,下面这个方式不行,提示无差异。不知道对比的是哪 2 个 commit...
git fetch origin
git diff origin/dev dev
*使用 Git Graph 插件也是一样的问题。
*只有下面这个办法可行,和我手动 git clone 一个新目录,结果一致。
git diff 图片 1 位置 commit1 图片 2 位置 commit2
*但是这个办法,操作太麻烦,需要手动复制 commit id ,而且只能在 cmd 里面查看
能否在可视化界面里面查看? ]]>
svn 可以使用 show log ,右键最新的提交,直接对比当前(当前代码可以提交,也可以未提交),调用 beyond compare 查看非常方便。
——————————————————————————————————————————
git 我使用 vscode 或者 TortoiseGit ,均无法实现以上功能。
如图,代码已经 commit 并且 sync 位于 2 ,1 是最新代码
点击 1 ,会对比 1 和 4 (还是 5 ,我不确定)
点击 2 ,会对比 2 和 3 ,
但是我想要对比 1 和 2 ,请问如何操作?
代码我是在 2 台电脑操作的,都是基于一个分支,不知道为什么会出现 merge 操作,都是 vscode 自动完成的。
——————————————————————————————————————————
问题 2:
如果当前电脑的代码未提交并且和服务器更新的文件有冲突,还必须先提交才能 fetch 对比,更加麻烦....
请问各位大佬,如何对比服务器上最新的代码和本地代码?
<img>https://imgur.com/a/ZReZPLn </img>
这个图要怎么才能直接显示 ]]>
我应该维护自己的 fork 分支吗?
但是我后面又不是经常维护,还想享受上游的更新咋整 ]]>
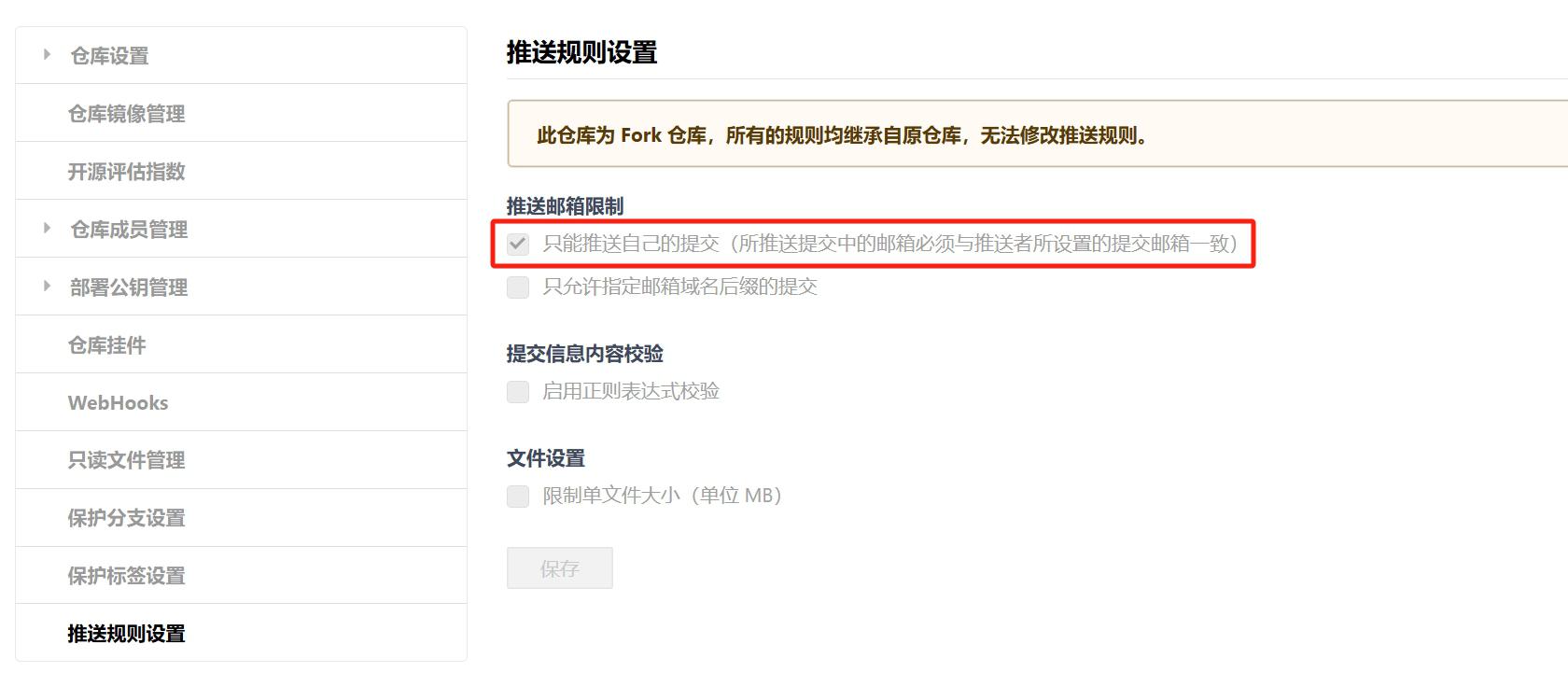
看了下该条 commit ,是从上游拉取来的,,那作者邮箱肯定是上游的邮箱啊,,怎么可能和我的邮箱一致
然后查了下我 fork 的仓库的设置,发现如下界面:上游的仓库设置了只有作者能提交,我 fork 该仓库的时候会继承该设置,并且无法修改!!
gitee 的 fork 操作为什么要继承推送规则??这是要保护什么吗?还是说就是想实现“设置了只有作者能提交的仓库,别人 fork 后就不能再跟踪上游更新”?
经过半年的开发之后,现在两者相差 200+个 commit ,500+个更改。
现在产品有需求,需要以 A 分支为基底,将 B 分支的所有内容合入,保证最终分支包含 AB 分支的所有更改。
目前想过分版本合并、以 commit 为单位合并、merge 直接合并、rebase 合并,感觉都不太好,没办法保证最终的合并结果。
各位有没有什么比较好的合并方式? ]]>
我们的开发流程是,研发将自己的开发分支合并到测试分支(第一次合并),上线到 测试环境,准出之后,提交 PR 将 feat 合并到 master 分支(第二次合并),然后上线到生产环境。
问题在于第一次合并是普通的 merge commit (因为开发中需要持续修改、持续合并),第二次合并是 squash merge (为了让主线更清晰)。这样时间长了之后,再从 master 拉开发分支,合并到测试分支的时候很容易冲突,很难解决。需要经常手动用 master 强制覆盖测试分支,强制覆盖就需要所有在测试中的 feature 再次合并到测试分支,比较麻烦。
想了解下这个问题有没有好的解决办法?
]]>工程师小明在 main 分支上进行了 A 、B 、C 、D 四次提交。
工程师小红在 A 节点 fork 了项目,并在 sub 子分支上进行开发。
现在小红想将 sub 子分支的代码合并到上游的 main 分支。
她应该先合并到自己 fork 的 main 分支,
还是可以直接将 sub 子分支合并到上游的 main 分支? ]]>
一是:直接把 master 合入 feature 解决冲突,再把 feature 合入 master ;
二是:先从 master 拉出分支 master_1 ,把 feature 合入 master_1 解决冲突,再把 master_1 合入 master ;
这 2 种有区别吗,LD 必须让第二种,不理解。 ]]>
是这样吗??
另外,,如果有一个小的修改希望发起 pull request ,,那应该也为这个修改新开一个 branch 吗??
或者说一个 fork 的仓库,,如果有 pull request 的打算,,就永远不要在 master 上修改代码,,master 只用来和 upstream 保持同步。。所有修改都在新的 branch 上做??
感谢各位大佬指教。。
]]>控制台提示
node_modules/@umijs/babel-preset-umi/node_modules/@babel/runtime/helpers/assertThisInitialized.js" does not exist in container. 删了.umi 目录也不行,然后 github 里维护说
git clean -dfx 再来安装,看起来是版本不匹配导致的
执行完然后发现不光项目启动不起来,文件都没了 😭
最近换成 cursor 开发,寻思 webstorm 的本地文件历史记录可能还有,打开 webstorm 发现.idea 文件夹都删没了,我 gitignore 忽略了都给删了,直接回滚到星期一???
]]>团队考虑了两种版本管理方式:
-
分支模式。 除了常见的 main/dev/release ,对于定制化的就从 main 拉出对应分支 project-A ... Z ,如果 A 有修改则拉出 feature 进行开发,开发测试完毕合回 project-A 里。 如果 main 有通用更新则按照情况从 main 合到 project-A ... Z ,同理如果 project-A 的一些功能验证过后按需也可以合回到 main 。
-
fork 模式。 基础版本正常开发迭代,有定制的需要时则从基础版本 fork 出一个 project-A ,它可以方便地随时同步上游仓库的修改,project-A 有被用户验证过后的功能也可以向上游仓库发起 merge 请求合到基础版本中
个人感觉分支模式到时候如果真的出现很多 project-X 分支的时候,有可能分支之间合并就乱了,也会把 git 的记录搞得很花。
另外解决怎么安排测试也是一个大问题
大家对以上两种模式有什么看法或建议? 或者有更合理的管理模式也可以提出供我们参考
]]>但是有一个文件明明只添加了一行代码,却提示整个文件都被改动了
原来一直没有这个问题,最近总是会莫名奇妙的出现,不知道是不是我前段时间重装了一次 git 的问题
有大佬遇到过或者了解啥问题的吗,求解惑,十分感谢 ]]>
我试着 Rebase 了一下 master, 各种冲突解决的要命, 所以问问大家. 你们合代码看重 rebase 么?
]]>我 gitignore 的 config.toml
项目展示的 config-example.toml
源码中有对 toml 的很多引用,导致我每次开发完 push 到 github 的时候都要把我源码中的 config 改为 example 。非常麻烦,想问问大家有没有什么好的解决方法或者插件什么的,能够让我 push 的时候丝滑切换。 ]]>
这个系统还不是很完美,希望有更多的人参与进来。
]]>git pull 项目,提示:Permission denied,ssh -T 测试又是正常的,如下图👇 
同样配置和密钥,在公司电脑就可以正常 pull 和 push ,请问大家可能是哪里的问题?
~/.gitconfig 里): [alias] wips = !(git stash -u | grep -qv 'No local changes to save' || (echo 'No local changes to save' && false)) && git stash show stash@{0} && (git push origin stash@{0}:refs/stashes/wip || (git stash pop && false)) && git stash drop -q wipl = !git fetch origin refs/stashes/wip && git stash apply FETCH_HEAD && git push -qd origin refs/stashes/wip 使用时在需要暂存的设备上运行 git wips( Working In Progress Save )
$ git wips 2019/12.bean | 2 -- 2020/01.bean | 2 +- 2024/07.bean | 6 ++-- 2024/08.bean | 97 ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ 2024/09.bean | 89 +++++++++++++++++++++++++++++++++++++++++++++++++++++++ 2024/10.bean | 88 ++++++++++++++++++++++++++++++++++++++++++++++++++++++ 2024/11.bean | 88 ++++++++++++++++++++++++++++++++++++++++++++++++++++++ main.bean | 3 ++ 8 files changed, 369 insertions(+), 6 deletions(-) Enumerating objects: 24, done. Counting objects: 100% (24/24), done. Delta compression using up to 12 threads Compressing objects: 100% (15/15), done. Writing objects: 100% (16/16), 3.30 KiB | 3.30 MiB/s, done. Total 16 (delta 10), reused 0 (delta 0), pack-reused 0 (from 0) To infinity:repos/accounting * [new reference] stash@{0} -> refs/stashes/wip 然后可以在其他配置了同一远程仓库的设备上运行 git wipl( Working In Progress Load )
$ git wipl From infinity:repos/accounting * branch refs/stashes/wip -> FETCH_HEAD On branch master Your branch is up to date with 'origin/master'. Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: 2019/12.bean modified: 2020/01.bean modified: 2024/07.bean modified: main.bean Untracked files: (use "git add <file>..." to include in what will be committed) 2024/08.bean 2024/09.bean 2024/10.bean 2024/11.bean no changes added to commit (use "git add" and/or "git commit -a") 过程就是从当前的工作区创建一个 stash ,推到远程一个叫 stashes/wip 的特殊 ref 上,再从另外的设备上拉取并删除。目前版本很简单,一次只能存在一个 stash (重复运行 git wips 会报错),不过基本够我用了。
后续有更新的话会更新在 这里
]]>Github: https://github.com/undertone0809/gcop
几个月前,受到一篇推文的启发 https://x.com/mtrainier2020/status/1802941902964277379 ,我突然想到可以借助 git alias 添加一些小命令,加速我的 git workflow 流程,于是我花了两个小时的时间进行工程封装,并发布了 pypi 包,并分享到了 V2EX 上: t/1052254 。
几个月来,我一直在维护这个框架,gcop 是一个智能的 AI copilot ,旨在帮助开发者撰写更好的 git commit message ,同时加速 git workflow 。
gcop 具有以下优点:
- 配置简单,
pip install gcop -U之后,简单配置完自己的模型就能直接使用 AI 生成你的 commit - 兼容市面上的几乎所有模型,底层基于promptulate 构建,开发者可以很轻松的配置自己想用的模型
- 加速 git workflow: 提供了丰富的 git 命令扩展,如 git amend, git info, git undo 等,用习惯了之后特别方便,具体参考 docs
- 自动撰写 git commit ,通过
git c的命令就可以自动生成你的 git commit message ,十分方便。 - 自定义 commit 模板:支持最佳实践自定义模板,让 AI 学习定制化的 commit style 。
最近在设计一个功能:可以自动将一个大的 code diff 拆分多个 commit ,不知道大家有没有这个需求呢,另外大家要是有其他的建议也欢迎交流。
欢迎大家 star 支持一下!
]]>请问这是什么情况??需要如何修改?
]]>一般研发写完代码之后,只要测试不反馈问题,他们也不会去管后续的流程。最开始是组内通知大家,要记得把代码合并到 develop 。但是一个项目有好几个开发人员,靠人去做这件事情确实要花时间,你要跟进这个项目的进度。所以单纯的靠研发去做这件事情,也确实不合理。
现在的问题是,缺一个流程去做这件事情:代码上线之后把代码合并到 develop ,这件事情由谁来做,怎么做?
请教一下大家的公司是怎么做类似的事情的?
]]>我的操作
-
github 上建了一个分支
-
在修改好文件后,当前目录 init 了一个仓库
-
gitub push 之后,报出存在冲突,提示要远程的分支已经有文件( readme
-
做了很多尝试,包括合并了冲突到 git pull 至 update branch 无果 最后 git push -f
同事说标准化操作必须是,要本地建文件或者空文件先 clone 或者 pull
这是 git 固定的工作流,还是说是有 SHA-1 的对应关系在里面。总感觉光这点跟 SVN 的差别不大
]]>教程地址:http://wyag-zh.hanyujie.xyz/
Github 仓库:https://github.com/hanyujie2002/wyag-zh
目前翻译还有很多需要改进的地方,欢迎提建议或者 pr !
]]>起初,我用 git bundle 来备份仓库,但是空间消耗太快,我想尽可能节省空间。
后来发现,Gitea 有「镜像仓库」功能。
上游仓库尚在,本地仓库可以同步更新,上游仓库删除,本地仓库也不会随之消失,本地仓库占用的空间永远与上游仓库相近。
不过这项功能有个缺点,仓库作者可以通过强制推送来删除上游仓库的内容,甚至把仓库换成另一个仓库。若上游仓库换成了另一个仓库,本地仓库也会同步上游仓库更改,变成另一个仓库。
无意间发现了 git fetch。
执行 git fetch <repo> *:refs/remotes/0924,待命令执行完毕,refs/remotes/0924 下会完整显示上游仓库引用的一切,git checkout 命令也可调出远程仓库的文件。不知道这么做有没有缺点,请大家指点指点
补充:git 是用的 gitea 搭建 ]]>
[remote "github"] url = https://github.com/jock/test fetch = +refs/heads/*:refs/remotes/origin/* [remote "gitlab"] url = https://gitlab.com/test fetch = +refs/heads/*:refs/remotes/origin/*| 我如何能为 github gitlab 分别设置对应的提交用户名
github:github-username gitlab: gilab-username 3 、同事 a 就打算复用 master ,就把 dev 直接合到 master
4 、最后我需要上线了,按之前的流程我得把 master 分支 rebase 到我的 feature ,但跨度这么大直接放弃了
5 、急着上线我就选择 merge 到 master ,也提前准备了备份分支,合并过去看用 sourcetree 和在线仓库检查 commit 都正常
6 、结果突然被组长发现了,他是用 smartGit ,说看到工作流乱成麻很不爽,这箭头我确实没看到,看了下 smartGit 的文档也不知所以
7 、点击下箭头会跳到 22 年的 commit 位置,然后点击向上箭头就回到现在,我感觉只是个提示,组长觉得是 24 年的 commit 插到了 22 年
https://imgur.com/a/i74XXnz ]]>
后来才明白,我之前误把 git+ssh 理解为 file+ssh 协议了
今天使用 export GIT_SSH_COMMAND="ssh -vvv" 的方法,给 ssh 开了 verbose 模式 debug1: Sending command: git-upload-pack 'git/git.git' debug2: mux_master_process_new_session: channel 1: request tty 0, X 0, agent 0, subsys 0, term "xterm-256color", cmd "git-upload-pack 'git/git.git'", env 4 从日志可以看出,其实 git+ssh 协议是通过 ssh 调用远端的 git 内部命令来提供服务的,而不是通过 ssh 访问远程文件系统来提供服务的
这个做法其实和 smart HTTP 类似: git+ssh 协议:ssh 作为网络层和身份验证层,ssh session channel 作为适配层,git 内部命令作为实际的 git 协议服务器 smart HTTP 协议: httpd 作为网络层和身份验证层、CGI 模式执行的 git-http-backend 作为适配层、git 内部命令作为实际的 git 协议服务器
而 dumb HTTP 协议,因为是 httpd 直接服务静态文件的,没有调用 git 的内部命令提供服务,所以才缺了 update-server-info 这个步骤,需要通过 hook 来执行该命令。
不过 post update hook 和 git send-pack 之间的互动我没看明白,不知道 update-server-info 命令到底输出了什么内容给 git send-pack 命令,让它上传文件到 dumb HTTP 服务去 这段代码应该怎么读呢?
]]>之前一直使用 Github ,也续费了一段时间每月$5 的存储包,后来发现腾讯的 Coding 直接免费给 10G 空间,就转移到 Coding 了,但是逐渐也不够了,腾讯 Coding 主要面对企业客户的,个人续费太贵了。
大家有没有其他推荐的平台?尽量空间大、续费便宜,海外平台也可以。
自己没有服务器,不太熟悉服务端的东西,对于单台服务器文件安全性也不太信任,所以尽量不想折腾自己搭建,偶尔还有异地访问需求。
]]>因为数据工程经常需要迅速、改动小的变动,所以我们没有 tag 和 release branch 。每次做开发的流程都是这样:
- 从 main 创建 feature branch
- feature branch 开发结束之后 merge 到 preprd
- 测试结束之后,preprd merge 到 main
目前我们很少有冲突,这点还蛮好的,因为项目划分的还可以,极少碰到两个人修改一个文件的问题。但是很难解决preprd和main同步的问题,所以经常出现不知道为什么preprd merge 到 main的时候,会把很早的 commit 也合并进去的问题。当然这并不是致命的问题,所以团队很久都没有解决,我也是最近加入才发现这个问题的。我猜测是因为有些同事直接把 feature 分支 merge 到 main 导致的,但是我也不是 git 专家,所以也不确定。另外我们从来不用 rebase ,只能用 merge ,我觉得也不是很好,但是说不出来为什么不好。
最近我们加了一步,就是 2 和 3 之间让main 反向 merge 到 preprd。这似乎解决了问题,但是我又觉得十分的丑陋。不知道大家有没有什么好的设计方案?或者说,我究竟应该怎么排查问题?我翻了下 gitbook ,感觉里头介绍的十分详尽,反而搞不清楚应该如何排查了。
多谢!
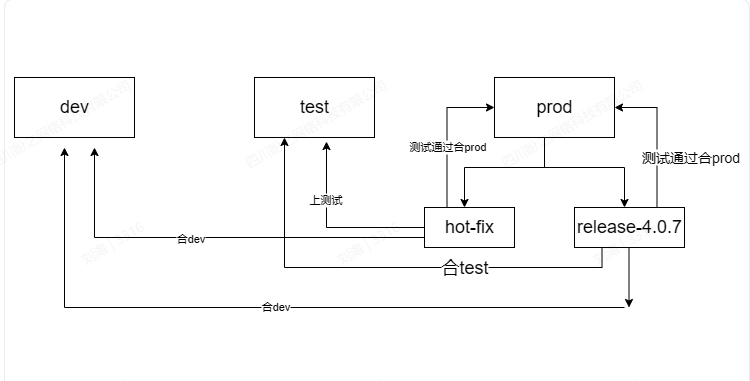
]]>目前我们是这样:
从 prod 单独拉一个 release 分支,然后 4 、5 个人在这个分支上开发,按功能区分模块,完成后让某个人合到 dev 、test
但是有个问题,开发的人一多,这样特别容易造成代码冲突