1 ,全文翻译,不是普通机翻,是 llm 大模型 AI 翻译,对学术语言风格进行了调校。可以选择你的学科,这样翻译更准确!
2 ,排版还原,公式图表不乱码;基本上( 90%)常见的论文的排版都是完美还原。
3 ,大模型辅助阅读:一键生成思维导图、论文导读、提取 LaTeX 公式等
4 ,跨库搜文献
网址: https://www.easyreader.com.cn/
目前我们正在不断完善软件,还有些 bug 。欢迎提供对于软件的使用建议。
本社区的分享资源:
目前注册后会有一个免费的使用额度,免费额度用完以后:
1 、回复主题
2 、并且在软件的反馈功能中,只需要提供你的社区昵称即可,会再赠送免费资源包(如果您愿意提供一些使用反馈,那更加感谢)
(分享的资源包需要人工定期发送,所以不是即时的,请理解。) ]]>
有些变化,一旦错过,就真的追不上了
做出海、做网站、做增长分析久了,你一定会发现一件事:
真正重要的信息,
往往不是你分析不出来,
而是你根本没看到它发生。
一个新站悄悄上线。
一个广告商开始把钱投向一批陌生网站。
一个 Publisher ID ,背后慢慢长出一整个站群。
等你意识到的时候,往往已经是事后复盘。
这就是我为什么要做 SiteData。
从“查数据”到“盯变化”,这是我真正想解决的问题
市面上的网站分析工具并不少:
- 查流量
- 看关键词
- 翻 Google Ads Transparency
但它们有一个共同的问题:
都只是在回答“现在怎么样”。
而现实里的关键问题是:
- 谁在扩张?
- 谁在复制?
- 钱正在往哪流?
这些答案,只有在变化刚发生时才有价值。
所以在 SiteData 里,我刻意把重点放在两件事上:
一是:把零散信息“串起来”
二是:把一次查询,变成持续监控
一眼判断:直接在 Google 搜索结果里看到站点全貌
我自己用工具时,最不爽的一点是:
明明已经在 Google 搜索了,
还要再点进各种网站、工具、后台。
所以 SiteData 做的第一件事很简单:
👉 在 Google 搜索结果页面,直接展示站点核心情报
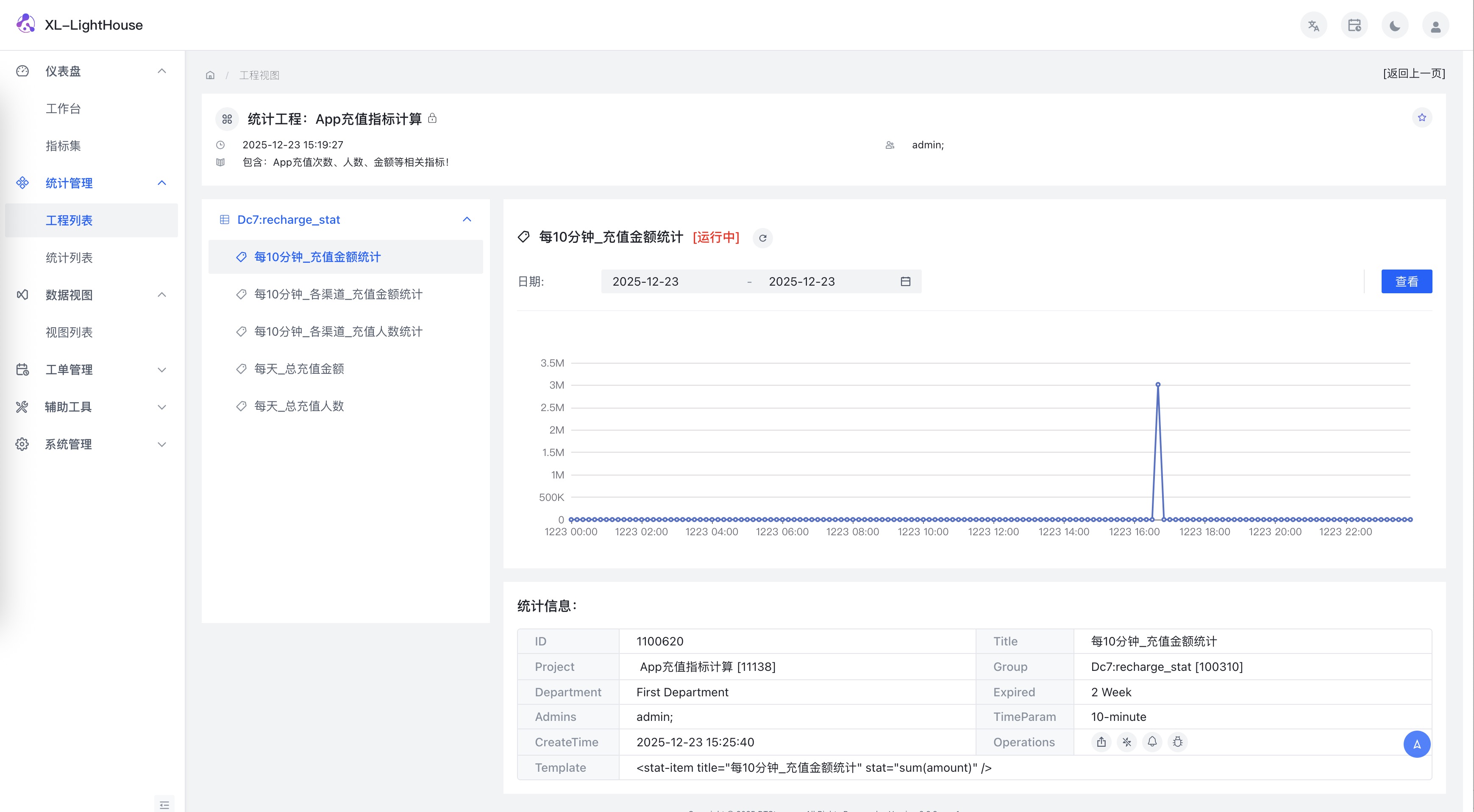
当你搜索一个网站时,可以直接看到:
- 每月访问量
- 流量来源构成(搜索 / 直接 / 外链 / 社交)
- 主要国家分布
- 跳出率、访问时长、页面数
- 核心关键词与搜索量
不跳转、不切页面,看一眼就知道值不值得点进去。
这解决的是一个非常现实的问题:
把“判断成本”压到最低。
Publisher ID 反查:把“单个网站”升级成“站群视角”
如果你做过 AdSense 、内容站或站群分析,一定知道:
- 单个网站,信息价值有限
- Publisher ID 才是结构线索
在 SiteData 里,你可以直接:
- 通过 AdSense Publisher ID
- 反查同一 ID 下的 所有关联网站
这一步非常关键,因为它能帮你:
- 判断是不是站群
- 看清扩张路径
- 识别内容农场或成熟模型
一句话概括这个能力:
你看到的不再是一个网站,
而是一个「正在运转的体系」。
通过 Google 广告商,反向找到一整批关联网站
除了 Publisher ,我还做了另一条反向路径:
👉 从「广告商」出发,找它投放过的所有网站
你可以通过:
- 某个 Google 广告商
- 查看它正在 / 曾经投放的站点列表
- 以及投放频率、投放规模
目标网站所在谷歌广告商,投放了哪些站点:
按周统计目标网站,谷歌广告投放行为:
这个视角非常“现实”,因为:
广告商的钱,是最诚实的信号。
如果一个广告商反复在多站点投放,通常意味着:
- 这个站点类型跑通了
- 或这个流量结构是可复制的
这一步,本质上是在回答:
哪些网站,是真的被市场验证过的。
不止反查,我更关心:谁又开始“动了”
只查一次,其实远远不够。
很多真正值钱的信号是:
- 新站刚上线
- 新投放刚开始
- 新站群刚扩张
所以在 SiteData 里,我加了「监控」这一层。
Publisher ID 监控:新站一上线,我就知道
你可以直接:
- 指定一个 Publisher ID
- 开启监控
- 当有新网站开始使用这个 ID时,系统会通知你
这意味着:
- 你不需要反复手动检查
- 不需要等几个月后再“考古”
你盯的是:
一个持续造站的源头,而不是结果。
广告商监控:钱开始投向新网站的那一刻
同样地,你也可以:
- 指定一个 广告商
- 当它开始在新网站投放广告
- 第一时间收到通知
这个功能的本质,是一个:
广告资金流向雷达。
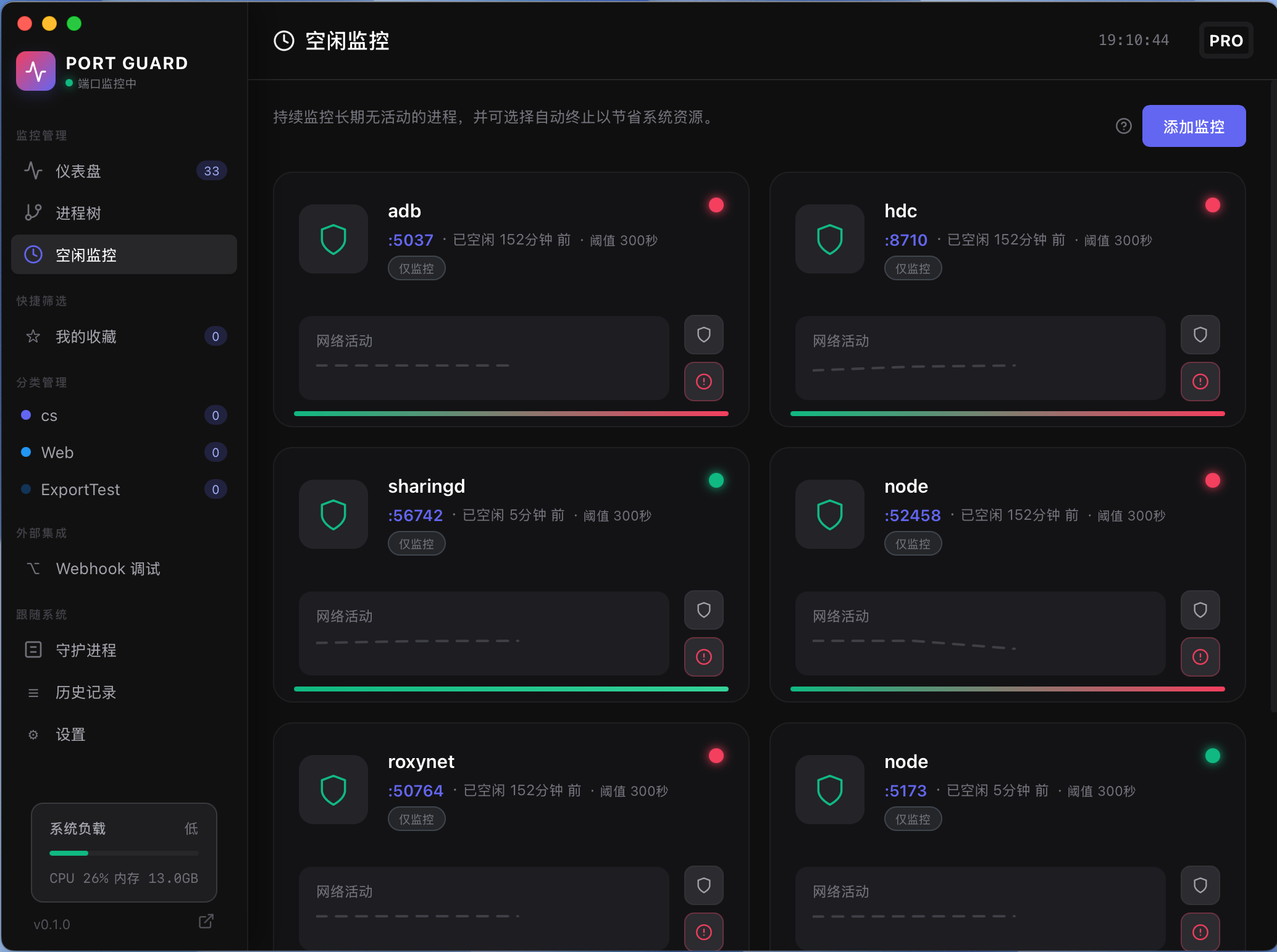
适合谁?
- 广告联盟
- 出海开发者
- 增长 / 竞品研究者
查询 + 反查 + 监控,才是完整闭环
我现在使用 SiteData 的方式基本固定:
- 在 Google 搜索页,快速扫一眼值不值得看
- 点开反查,确认有没有站群 / 关联结构
- 对关键对象加监控,等变化自己出现
你不需要天天盯着工具,
工具会在关键时刻来找你。
为什么我要把这套系统做出来?
说得直白一点:
- 我不想再靠运气
- 也不想等别人把趋势总结完再抄作业
我更想做到的是:
在变化刚发生的时候,
我已经在场内了。
SiteData 不是一个“什么都能查”的工具,
而是一套 降低你错过关键信号概率的系统。
官网地址
SiteData 不只是告诉你「现在发生了什么」,
而是让你在第一时间知道:
你关心的开发者和目标广告商,又开始行动,做了什么站。
如果你也关心网站、广告和变化本身,
可以直接访问官网 👉 https://sitedata.dev
或前往 Chrome 商店安装插件 👉 https://chromewebstore.google.com/detail/emeakbgdecgmdjgegnejpppcnkcnoaen
之前赠送的授权也都失效了。
主要变更
-
额外的数据库驱动现在每个数据库是单独的进程了。
-
查询文件保存为文件了,之前保存在 Sqlite 中。
bug 修复
-
SQL 分割时多行注释的最后一个
/会被错误的保留,已修复。 另外整理了 SQL 文件格式的说明文档,参见SQL 文件格式 -
MongoDB ,编辑含有 Binary 的单元格时,生成的 Javascript 多了
new, 比如new bson.Binary.createFromBase64(...),应该为bson.Binary.createFromBase64(...)。
新增特性
-
额外驱动文件现在可以自动下载安装了。(不过网络错误,请在设置中修改
Network-Application Proxy) -
数据库配置中的密码都使用保存在 Keyring 中的主密码来加密保存了。
-
支持 MongoDB 的事务。(需要你的部署方式支持,不然不显示)
-
选择文件的组件支持拖拽文件了。
已知问题
授权认证的时候,ctx 少绑定一个参数,现在会报错,而且如果激活了授权,启动时候的认证会导致应用直接推出(之前激活过 BlueNova 的用户无需担心,因为,,额,无效了)……目前根本没有需要购买授权才能使用的功能,所以本次更新就不再赠送授权了。( Bug 也下个版本再修了)😓
目前想到的授权才能使用的功能是,在单独的窗口中打开某个数据库。感觉需要到 beta 的末尾才会做。所以授权认证这些逻辑的优先级目前很低,所以总是出错。
地址
]]>脑洞生成器 是一款专为同人社区设计的免费 AI 驱动网络应用,用于生成创意角色脑洞、关系场景和多角色互动。服务全球范围内的写作者、角色扮演者和同人创作者。
在线地址: https://headcanongen.org
目标用户: 同人小说作者、角色扮演者、同人创作者、角色开发爱好者
核心功能
1. 三种生成模式
- 单人角色模式: 为单个角色生成独特个性特征、习惯和背景故事
- 多角色模式( 2-10 人): 创建团体动态、团队互动和群像场景
- 关系/CP 模式: 发展两个角色间的浪漫、柏拉图式或复杂关系场景
2. 四种情感基调
- 搞笑: 轻松幽默的娱乐性场景
- 深刻: 富有情感深度的内省式内容
- 温馨: 温暖治愈的暖心时刻
- 虐心: 情感戏剧和激烈场景
3. 内容管理
- 本地存储: 在浏览器中私密保存喜爱的脑洞
- 导出选项: 下载为文本文件或图片
- 复制到剪贴板: 快速分享功能
- 社交分享: 直接分享至 Reddit 和 Twitter
4. 零门槛设计
- ✅ 完全免费 - 无付费层级,无隐藏费用
- ✅ 无需注册 - 无需登录即时访问
- ✅ 无限生成 - 无使用限制或上限
- ✅ 隐私优先 - 所有数据本地存储,永不上传
热门使用场景
同人小说作者
- 生成角色发展灵感
- 创建关系动态
- 开发情节场景
- 克服写作瓶颈
角色扮演者
- 发展角色个性
- 创建背景故事
- 生成互动场景
- 建立角色关系
内容创作者
- 社交媒体内容灵感
- 同人画作概念
- 视频内容创意
- 社区互动帖子
热门同人圈
- 《博德之门 3 》
- 《哈利·波特》
- 漫威电影宇宙
- 《星球大战》
- 《原神》
- 《 Critical Role 》
- 《我的英雄学院》
- 以及其他任何虚构宇宙!
]]>
Mac App Store 下载地址: https://apps.apple.com/app/id6755630162
官网: https://floattube.uuphy.com/
如题,在我开发的 FloatTube 中,加入了这项小功能,目前支持:
场景 A. 切换标签页自动 PiP
场景 B. 离开 Safari 自动 PiP
两个场景均可选择性开启。 两个场景并不是所有 macOS 都支持,Safari 扩展兼容性为 macOS 10+,新功能在较旧版本不支持切换标签页触发,在 macOS 26 上却可以。
上线的版本目前是 1.0.7 ,我想收集这个情况来写官网功能说明,辛苦大家帮我一起完善这个小功能。
我目前仅测试了 macOS 12 和 macOS 26 ,我想收集一下在其他系统和其他 Safari 版本的使用情况。对外接显示器有优化,阻止了一些情况的自动触发,具体可以看 TG 群,如果有些情况需要额外阻止自动 PiP ,也可以反馈给我。
如何发码
目前我这里将会提供 12 个兑换码,评论区待会儿我会放剩下的 6 个。 已兑到的,在评论区留下评论,避免抢兑。
K63PKAJJWYLH6EYYA7J6X44XA496LW34WYTRMYT47PKX64L6KLJL4KRX7LL69Y6ARLJT3LAX
没有兑换到的也没关系,加入 TestFlight, 安装后,进群讨论,或者可以在扩展 配置 界面的右下角,有一个反馈按钮,不管在哪里反馈,反馈信息至少包含:
系统版本: Version 12.7.6 Safari 版本: Version 17.6 (17618.3.11.11.7, 17618) 是否外接屏幕: 是 使用情况: 切换标签页自动 PiP 完全不可用 离开 Safari 自动 PiP 可用 外接多屏幕下,切换到另外一个屏幕时,不会意外触发 是否需要兑换码 是 如果还有更好的建议,欢迎提出来。
我会预留 77 个兑换码发给参加 TestFlight 的用户,因为这个验证还是需要一点时间的,出于收集的价值考虑,按照系统版本的情况平均分配数量,如果某个系统版本发送的兑换码已经达半数,我会在评论区附上评论。
]]>一键安装地址: 安装地址
脚本仓库地址: 仓库地址
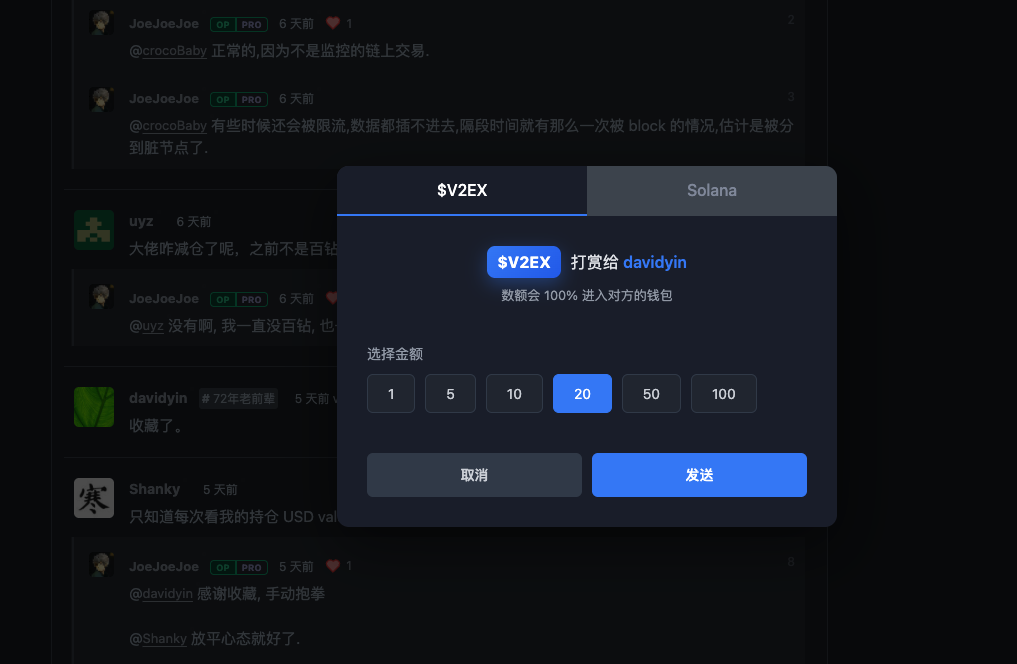
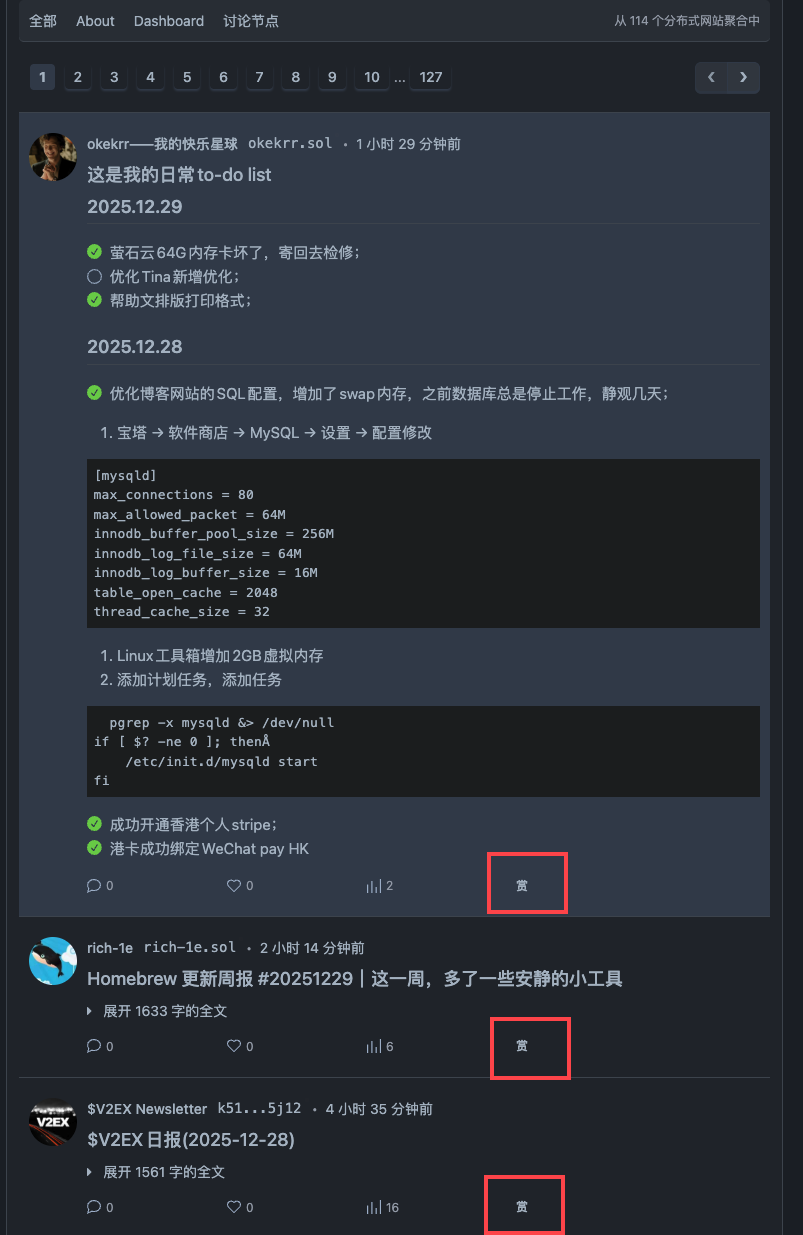
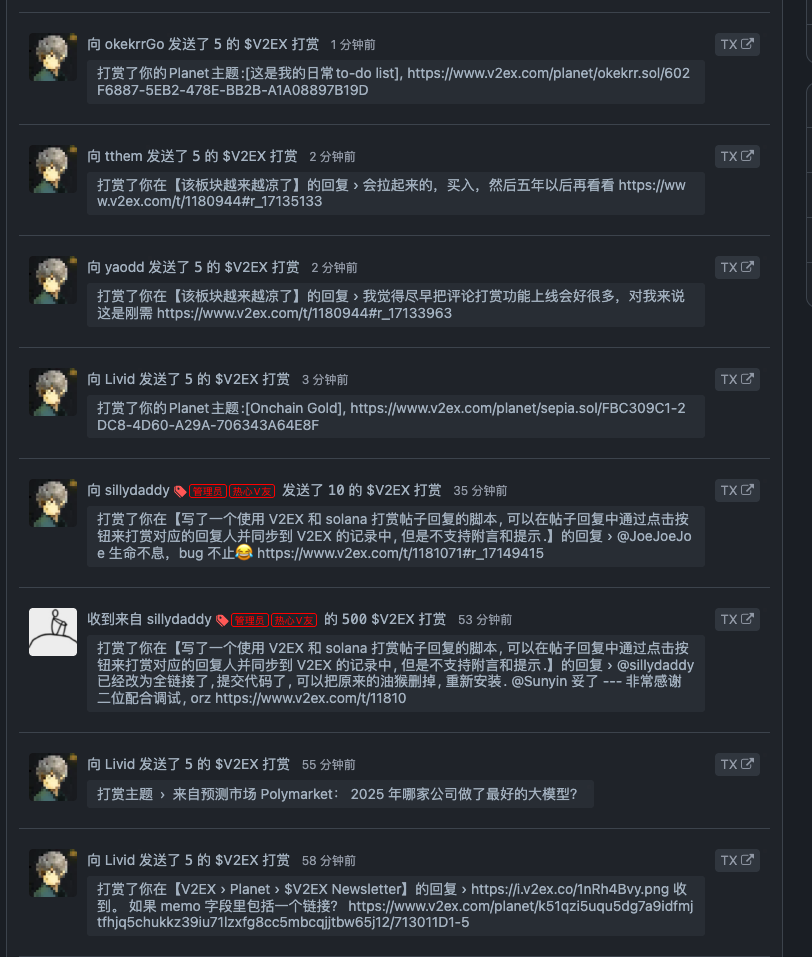
V2EX 关联钱包教程: 视频教程
https://fun.v2ex.pro/188F179E-2776-4F0F-B2C6-78C49F21E71D/connect_wallet.mp4
ps: 顺带着提一嘴 V2EX 历史数据查看器: https://data.v2ex.pro/ ,可以查看之前的 V2EX 数据, 包括但不限于在线人数变化, $V2EX 持有人数变化等, 相关介绍在这$v2ex 历史数据查看.
相关截图: 
官方网站 : https://intm.jsiqi.vip/
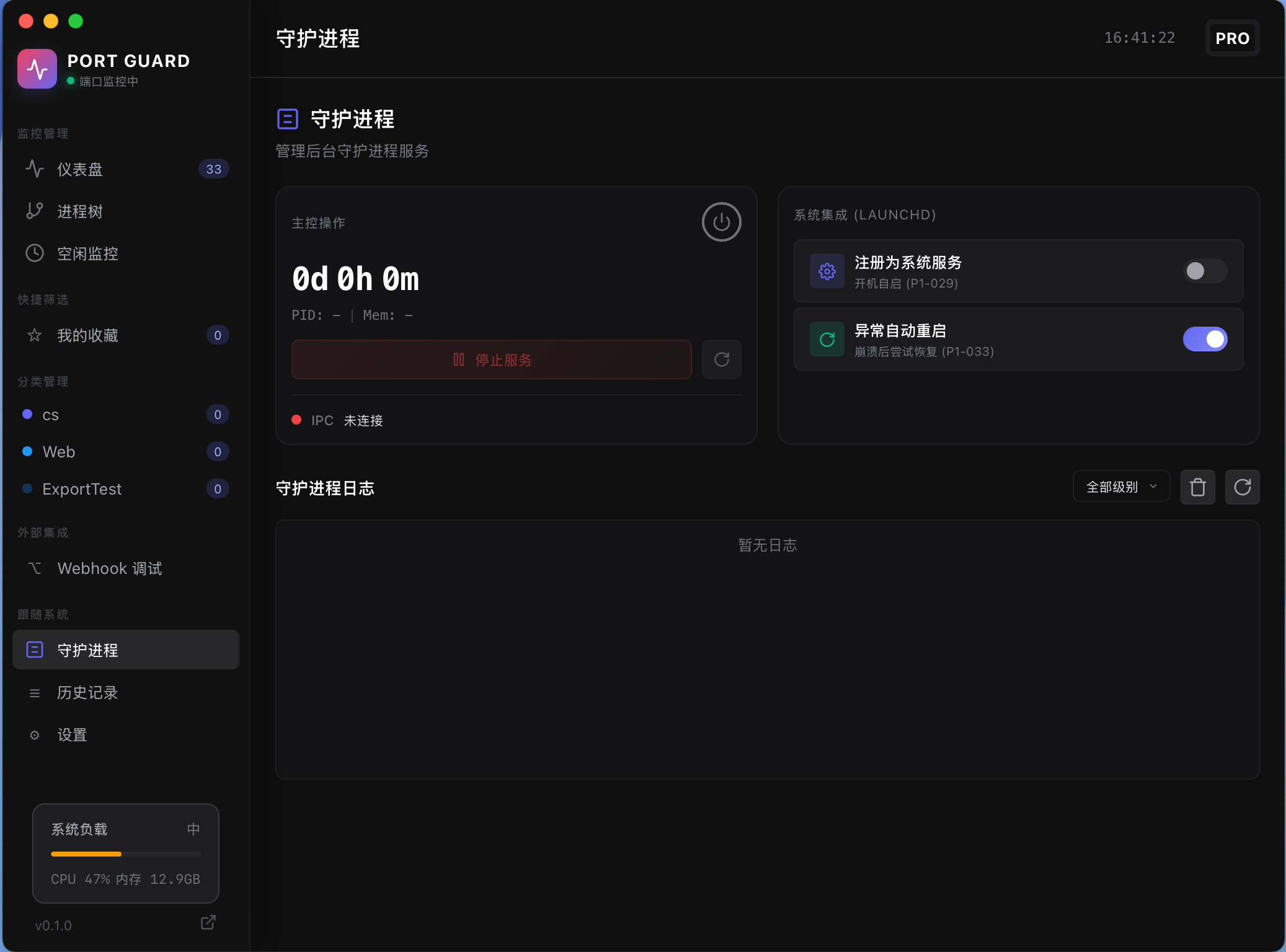
主要功能
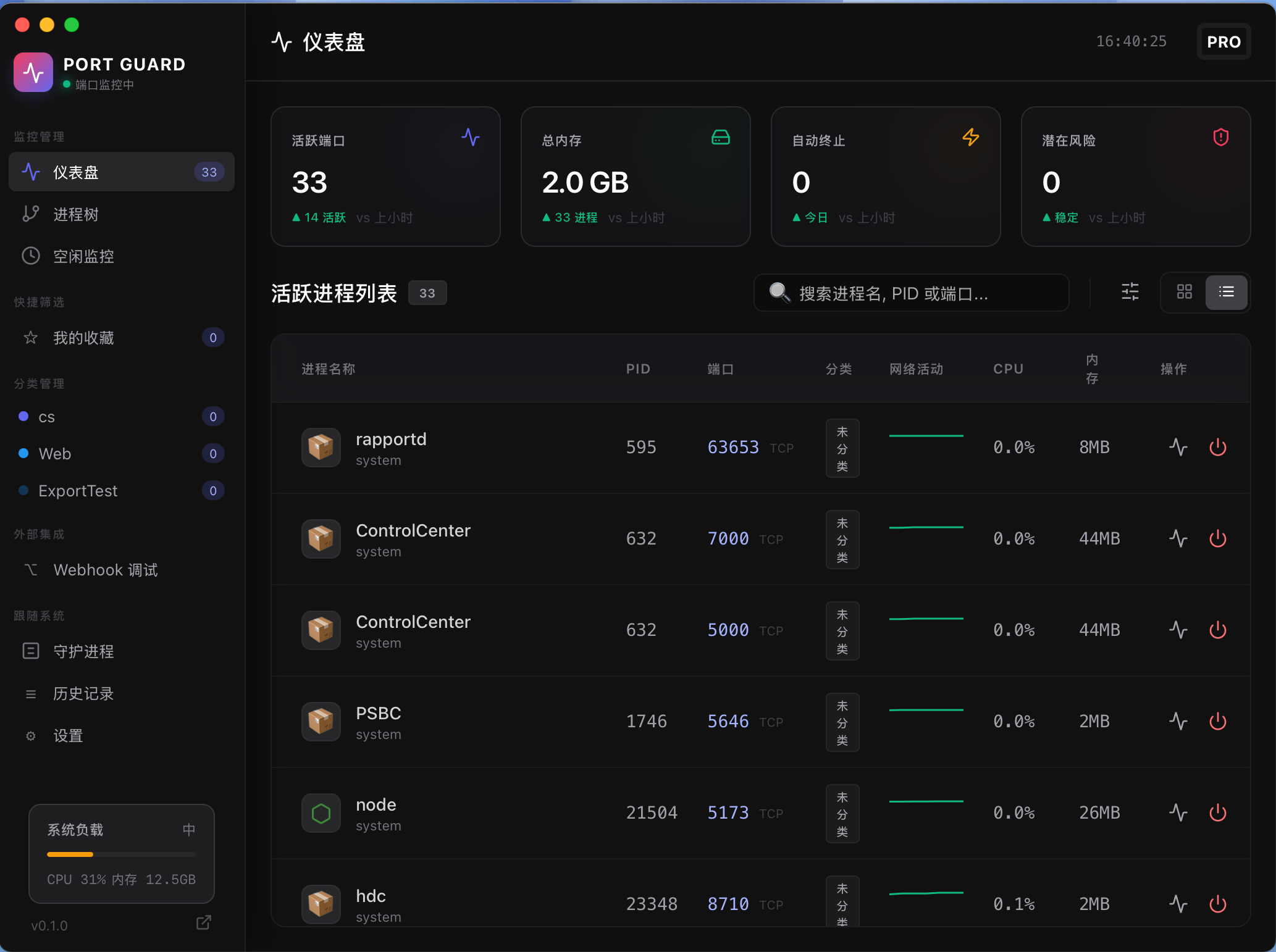
-
仪表盘:实时速度仪表、网络趋势图、网络信息、程序实时活动信息。
-
流量监控:按程序/按时间双维度,小时/日/周/月/年聚合图表展示网络使用情况。
-
防火墙:规则组管理、启停与优先级;通配符/CIDR/端口/应用/路径匹配;实时拦截与决策记录。
-
状态栏弹窗:不打开主窗口也能看实时网络动态。
-
设置:主题、语言、颜色、单位、刷新间隔、自启动、数据导入导出、版本检查等常用功能。





核心特点
-
菜单栏即刻网速:常驻状态栏+弹窗,抬眼就能看到上下行速度、趋势与关键网络信息。
-
程序级洞察:按应用实时排序上传/下载占用,快速找出谁在偷跑流量。
-
深度历史统计:小时/日/周/月/年多维度图表与列表,支持按程序、按时间双视角分析。
-
专业防火墙:规则分组+优先级,支持域名通配符、CIDR 、端口、Bundle ID/进程路径,入站/出站都可控,并有实时决策日志。
-
网络信息面板:公网/局域网 IP 、网关、MAC 、接口状态一目了然,辅助排查网络异常。
-
玻璃态 SwiftUI 体验:现代化 UI ,亮/暗/跟随系统主题,自定义上传/下载配色;内置中英双语,单位与刷新频率可选。
-
高性能本地化:NE+XPC 流程低延迟,GRDB 本地存储,Combine 响应式链路;数据留在本机,长时运行占用低。
平台支持
- 平台支持:macOS 14+,Apple Silicon 优化。
- 语言与主题:简体中文/英文(自动/手动切换),亮/暗/跟随系统。
- 数据与隐私:历史数据本地 SQLite 持久化,无需外部依赖。
- 程序提供 7 天免费全功能试用。
购买优惠
折扣码在官方网站下单时,可以直接减免相应金额。初期提供大量折扣优惠:
下述三个折扣码有效期到 2026 年 1 月底;且都有一定的使用次数。
- 一折优惠折扣码:
XWQQ5B6BU1 - 五折优惠折扣码:
HGY9KA57FQ - 八折优惠折扣码:
IQT93OHNST
附言
]]>
- 初衷是由于
little snitch太贵了,且Lulu有些简陋,所以想开发一个自用的 app ;产品创意、方案设计、代码开发,这整个过程vibe coding作为主要执行者,我负责方案审查,代码审查、性能优化等工作。iNTM的的名称是由Network Traffic Monitor缩写后在前方添加一个字母i得来;
发自内心的给大家说,我很开心能有 Bluesky 这样一款产品,能让我保持关注和真诚的热爱。毕竟作为家有 4 老 1 小的大龄程序员(已失业,抱歉没给大家做出正面的榜样),生活中的琐碎很容易磨灭任何兴趣。
回到技术本身,Bluesky 广义上是指基于 AT 协议的开放社交平台,既然是开放的,那么任何组织和个人都能自己实现 Bluesky 的任何服务,本次来给大家推荐的就是由我实现的 Bluesky 视图服务(也有配套的 app ),我给他取名 Fatesky 。可能很多人不理解,Bluesky 已经有对应的服务了,干嘛还要重复造轮子?
真心说,我其实没得选,这一切都要从我发现 Bluesky 的枷锁谈起,我理解本质是中心化与非中心化的战争。从了解用上 Bluesky 后,刚开始我傻傻的认为终于能自己掌握数据,畅游互联网了。当头一棒就是评论看不到,是的,我看到有评论数量,但是我看不到真正的评论。
后来才发现,原来 bsky 并没有表面上的那么开放,它在实现视图服务的时候照抄了很多中心化平台的思路,拥有强大的影子审核屏蔽措施。而不是使用去中心网络中的标签方式把信息审核选择权还给用户(虽然 bsky 支持自定义标签机,但它并没有很好的实践出来,我们 v 站有浏览器扩展可以对用户打标签审核,本质是一样的)。
我看不到的评论其实就是一个被 bsky 封禁的账号发布的评论,这个账号是人家独立托管的 PDS ,所以从 AT 网络上来看,这个账号一切正常,是 bsky 平台单方面的封禁。这让我对 bsky 的正义权威形象有了根本性动摇。后面发生了更多不爽的事,我经常在帖子下劝人不要键政(现在不会了,不熟的不会劝了,没必要,给别人添堵自己也没好处),有键政的用户就通过攻击拉黑的方式恶心我。行为是攻击我之前解除拉黑,攻击我之后重新拉黑。由于我被拉黑了,在 bsky 的机制中我看不到它的评论,也无法做出回应,只有其他人(包括匿名用户)能看到。这算什么?
作为程序员,我当然不会坐以待毙,我在 bsky 的 api 服务之上包装了一层 api ,进行数据检查和利用匿名用户身份纠正数据,这就是第一版的 Fatesky 的雏形,当时我还写了一篇博客介绍。将 PDS 的配置修改成 Fatesky 之后我就解锁 bsky 的一小部分枷锁,你无法想象你的关注列表中有多少死账号(被 bsky 封禁了,你看不到所以也无法 unfollow ,且由于你的社交数据 bsky 无权修改,所以这些垃圾数据就在你的 PDS 社交关系中腐烂了下来)。就这么悠闲的冲浪着,维护者自己的动态源和标签机,我以为也就这样了,后来( 10 月)我自己的账号 @smitechow.com 也被 bsky 无理由(连邮件通知都没有)封禁了,我能登录,能看别人的帖子(因为 PDS 是我自己独立托管的,数据一切正常,感谢 AT 协议),就是看不到自己的帖子,多么可笑?
正好我失业了,我有了大把时间,我就专心开发了 Fatesky 第二版,不再是第一版那样的缝缝补补小打小闹,而是全套的视图服务,其中艰辛就不必说了(如果你想听有时间再聊),修改上线了第三方客户端自己用了起来。如果你也被 Bluesky 的枷锁困扰多时,你一定要用一用,试试看。
但是 web 客户端始终不方便(刷动态源一时半会看不完,进度位置没法像 Android ,ios 原生 app 那样保持),前几天产生了一个想法,能不能在 Bluesky 官方客户端上直接使用 Fatesky 的视图服务呢,发现可以,我非常开心。
这就是 soar 遨游蓝天的由来,欢迎大家加入真 web3.0 的网络,加入 Bluesky 。这是 soar 遨游蓝天的落地页官网 https://soar.smitechow.com
感谢你的耐心阅读,欢迎试用。
]]>产品哲学,稳定第一,安全第二,流畅第三
放弃所有狗屁跨平台框架,采用系统原生语言
体积:14.5M
 )
)下载链接: https://apps.apple.com/app/id6479238971
10 个美区优惠券兑换码,原价 29.99$ 优惠后到手 17.99$
AYNJ38KWFT37J4HX7F
PFMMTAEYY3JN4RNTML
W63TK3LFYTK6J3ARFM
7LNEYWFW7FRTT66E8E
6EE3HWK74LR83AEJL6
KHLAW8ANL4HX8AP8YM
EYMJ76RXP6EL8T6K64
NJKN6KPX7J8FX7RP6W
WKWXETP6PMX8NMMLYE
6FPTPNLA7P3F6X7RNW ]]>
上一版的功能已经有很多不错的管理功能了:
- 多语言支持
- 多来源支持:本地 MDX 文件渲染和服务端内容数据渲染
- 设置文章发布状态(草稿、发布、归档)
- 设置可读权限(公开、登录用户、订阅用户)
- 置顶
- AI 翻译
- 完善的 metadata
昨天新增了更多功能,能够让 NEXTY.DEV 轻松扩展 CMS 模块,无需费心开发代码,把更多精力用在 SEO 内容方案规划上:
- 5 分钟新增 CMS 模块。网站只有 Blog 模块写内容是不够的,现在模板用户只需添加几行配置( p4 )、新增页面入口文件,一个全新的内容模块就做好了。(口喷 AI 仅需 1 分钟)
- 新增开箱即用的 CMS 模块 /glossary,可以用来做产品术语介绍,提升 SEO ,重视 SEO 的大厂通常都有这样的页面。(演示链接: https://demo.nexty.dev/glossary )
- 大部分功能都可轻松开关( p4 ),而且不同模块独立设置,互不影响,完美支持不同 CMS 模块需求不同的场景
- 支持开关阅读量统计
- 支持开关本地 MDX 文件渲染
- 文章列表支持选择卡片视图或列表视图
- 没有设置封面图也没事,模板会自动根据标题生成 OG Image
- 封面图和文章图片都支持本地上传、外部链接、从 CloudFlare R2 选择
- 富文本/Markdown 编辑器的工具栏也都可配置开关,多处复用难度降到 0
懂 SEO 的兄弟应该能看出来这些功能设计有多好用。
完整介绍可以来文档看:(NEXTY.DEV 的 CMS 模块介绍)[https://nexty.dev/zh/docs/guide/cms]
SEO 已经需要时间了,就不要再在编码上面付出时间了。用 NEXTY.DEV 的 CMS 模块,上站第一天就无需关心内容页面开发,直接专注布局 SEO 方案。