
有没有更加易用的,比如本地起个镜像就行,以及可视化配置表同步,配置同步哪些字段
最好是能和其他系统进行交互,例如调度系统,在数据同步完成后再执行后续任务
]]>文档例子不好好写,每次出个问题还得翻源码看怎么处理,永远只会写个 hello world 级别例子,就这级别例子自己写个 scala 就搞定了好伐。
关键是这糟糕的项目竟然还能混进 Apache ,李安震惊表示不理解。
上一次吃屎还是腾讯开源的数据全家桶,那是真恶心。
]]>消费 kafka 数据写到 CK ,mysql
不想写代码方式对接数据源
看看社区有什么经验,避免走弯路
比如,980pro 4 条组 raid 0 ( YouTube 上有视频,https://www.youtube.com/watch?v=OCGguruZyrw&t=413s 甚至直接 256G 内存,拿 120G 内存当硬盘(一时之间忘了这个名词)
用 mysql 或者 clickhouse,对比 spark 、presto 等,会存在前者更快的可能吗?
]]>目前考虑是通过 canal 通过 binlog 订阅某几张表来实现新增通知机制,有没有什么更好的办法呢?是个小工程,周期很短。
感谢大家!!!
]]>在各网站找到的课程基本都是面向研发的,上来就开始怼 JAVA,学起来太难了。故求各位大佬推荐,能快速了解大数据技术生态的书 /课程,大致类似给产品经理讲技术这样的程度,不要求掌握原理,知道基本全景过程即可。
期望:能基本了解大数据 /数据中台类似项目的全流程技术,可以和 RD 进行对话。
本人技术背景:非 CS 专业出身,懂一些云,会写一些前端,知道传统工程化的研发流程。正在看 Hadoop 的各种书。
]]>这两年国外的数据产品 dbt 非常的火,国内好像讨论很少,最近翻译了一篇 dbt 创始人介绍 dbt 的文章也写了一篇使用 dbt 的教程帮助大家了解 dbt:指路
]]>更多精彩内容,请关注微信公众号:后端技术小屋
一文读懂 clickhouse 集群监控
常言道,兵马未至,粮草先行,在 clickhouse 上生产环境之前,我们就得制定好相关的监控方案,包括 metric 采集、报警策略、图形化报表。有了全面有效的监控,我们就仿佛拥有了千里眼顺风耳,对于线上任何风吹草动都能及时感知,在必要的情况下提前介入以避免线上故障。
业界常用的监控方案一般是基于 prometheus + grafana 生态。本文将介绍由 clickhouse-exporter(node-exporter) + prometheus + grafana 组成的监控方案。
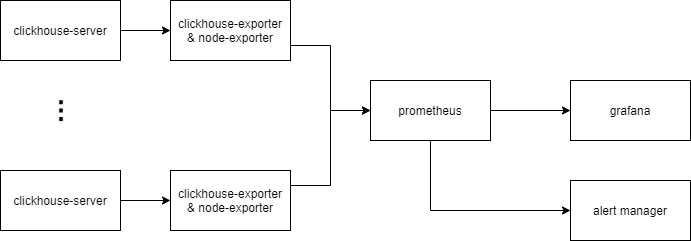
以上为监控方案示意图
- clickhouse-server 中有 4 个系统表会记录进程内部的指标,分别是
system.metrics,system.asynchronous_metrics,system.events,system.parts - clickhuse-exporter 是一个用于采集 clickhouse 指标的开源组件( https://github.com/ClickHouse/clickhouse_exporter),它会定时查询 clickhouse-server 中的系统表,转化成监控指标,并通过 HTTP 接口暴露给 prometheus.
- node-exporter 是一个用于采集硬件和操作系统相关指标的开源组件( https://github.com/prometheus/node_exporter)。
- prometheus 定时抓取 clickhouse-exporter 暴露的指标,并判断报警条件是否被触发,是则推送到 alert manager
- DBA 可通过 grafana 看板实时查看当前 clickhouse 集群的运行状态
- DBA 可通过 alertmanager 设置报警通知方式,如邮件、企业微信、电话等。
1 部署与配置
1.1 clickhouse-server
我们生产环境版本为20.3.8,按照官方文档部署即可。
1.2 clickhouse-exporter
clickhouse-exporter 一般与 clickhouse-server 同机部署。
首先下载最新代码并编译(需预先安装 Go)
git clone https://github.com/ClickHouse/clickhouse_exporter cd clickhouse_exporter go mod init go mod vendor go build ls ./clickhouse_exporter 然后启动
export CLICKHOUSE_USER="user" export CLICKHOUSE_PASSWORD="password" nohup ./-scrape_uri=http://localhost:port/ >nohup.log 2>&1 & 最后检查指标是否被正常采集:
> curl localhost:9116/metrics | head # TYPE clickhouse_arena_alloc_bytes_total counter clickhouse_arena_alloc_bytes_total 9.799096840192e+12 # HELP clickhouse_arena_alloc_chunks_total Number of ArenaAllocChunks total processed # TYPE clickhouse_arena_alloc_chunks_total counter clickhouse_arena_alloc_chunks_total 2.29782524e+08 # HELP clickhouse_background_move_pool_task Number of BackgroundMovePoolTask currently processed # TYPE clickhouse_background_move_pool_task gauge clickhouse_background_move_pool_task 0 # HELP clickhouse_background_pool_task Number of BackgroundPoolTask currently processed 1.3 node-exporter
node-exporter 需与 clickhouse-server 同机部署
首先下载最新代码并编译
git clone https://github.com/prometheus/node_exporter make build ls ./node_exporter 然后启动
nohup ./node_exporter > nohup.log 2>&1 & 最后检查指标是否被正常采集
> curl localhost:9100/metrics # HELP go_gc_duration_seconds A summary of the GC invocation durations. # TYPE go_gc_duration_seconds summary go_gc_duration_seconds{quantile="0"} 6.3563e-05 go_gc_duration_seconds{quantile="0.25"} 7.4746e-05 go_gc_duration_seconds{quantile="0.5"} 9.0556e-05 go_gc_duration_seconds{quantile="0.75"} 0.000110677 go_gc_duration_seconds{quantile="1"} 0.004362325 go_gc_duration_seconds_sum 28.451282046 go_gc_duration_seconds_count 223479 ... 1.4 prometheus
修改 prometheus 配置文件,添加 alertmanager 地址、clickhouse-exporter 地址
prometheus.yml 示例如下:
global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: - ./rules/*.rules # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'clickhouse' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['clickhouseexporter1:9116', 'clickhouseexporter2:9116', ...] *.rules 示例如下:
groups: - name: qps_too_high rules: - alert: clickhouse qps 超出阈值 expr: rate(clickhouse_query_total[1m]) > 100 for: 2m labels: job: clickhouse-server severity: critical alertname: clickhouse qps 超出阈值 annotations: summary: "clickhouse qps 超出阈值" description: "clickhouse qps 超过阈值(100), qps: {{ $value }}" 启动 promethus
nohup ./prometheus --config.file=/path/to/config --storage.tsdb.path=/path/to/storage --web.external-url=prometheus --web.enable-admin-api --web.enable-lifecycle --log.level=warn >nohup.log 2>&1 & 浏览器输入http://prometheus_ip:9090检查 prometheus 状态
1.5 alert manager
首先修改配置文件
配置文件示例如下:
route: receiver: 'default' group_by: ['service','project'] receivers: - name: "电话" webhook_configs: - url: <url> - name: "企业微信" webhook_configs: - url: <url> - name: "邮箱" webhook_configs: - url: <url> 然后启动
nohup ./alertmanager --config.file=/path/to/config --log.level=warn >nohup.log 2>&1 & 1.6 grafana
关于 clickhouse 的 dashboard 模板已经有很多,在这里推荐: https://grafana.com/grafana/dashboards/882 将它导入到新建的 grafana dashboard 之后,即可得到漂亮的 clickhouse 集群看板(可能需要微调)。
另外建议安装 clickhouse datasource 插件。有了这个插件便能在 grafana 中配置 clickhouse 数据源,并通过 Clickhouse SQL 配置图表,详细文档见: https://grafana.com/grafana/plugins/vertamedia-clickhouse-datasource
2 重要指标和监控
我们可以看到,不管是 node-exporter 还是 clickhouse-exporter,它们的指标种类很多,大概有几百个。我们的策略是抓大放小,对于重要的指标才设置报警策略并创建看板。
下面列举一些个人觉得比较重要的指标
2.1 系统指标
系统指标由 node-exporter 采集
| 指标名 | 指标含义 | 报警策略 | 策略含义 |
|---|---|---|---|
| node_cpu_seconds_total | 机器累计 cpu 时间(单位 s) | 100 * sum without (cpu) (rate(node_cpu_seconds_total{mode='user'}[5m])) / count without (cpu) (node_cpu_seconds_total{mode='user'}) > 80 | 用户态 cpu 利用率大于 80%则报警 |
| node_filesystem_size_bytes/node_filesystem_avail_bytes | 机器上个文件分区容量 /可用容量 | 100 * (node_filesystem_size_bytes{mountpoint="/data"} - node_filesystem_avail_bytes{mountpoint="/data"}) / node_filesystem_size_bytes{mountpoint="/data"} > 80 | /data 盘占用超过 80%则报警 |
| node_load5 | 5 分钟 load 值 | node_load5 > 60 | 5 分钟 load 值超过 60 则报警(可根据具体情况设置阈值) |
| node_disk_reads_completed_total | 累计读磁盘请求次数 | rate(node_disk_reads_completed_total[5m]) > 200 | read iops 超过 200 则报警 |
2.2 clickhouse 指标
| 指标名 | 指标含义 | 报警策略 | 策略含义 |
|---|---|---|---|
| clickhouse_exporter_scrape_failures_total | prometheus 抓取 exporter 失败总次数 | increase(clickhouse_exporter_scrape_failures_total[5m]) > 10 | prometheus 抓取 export 失败次数超过阈值则报警,说明此时 ch 服务器可能发生宕机 |
| promhttp_metric_handler_requests_total | exporter 请求 clickhouse 失败总次数 | increase(promhttp_metric_handler_requests_total{code="200"}[2m]) == 0 | 2 分钟内查询 clickhouse 成功次数为零则报警,说明此时某个 ch 实例可能不可用 |
| clickhouse_readonly_replica | ch 实例中处于只读状态的表个数 | clickhouse_readonly_replica > 5 | ch 中只读表超过 5 则报警,说明此时 ch 与 zk 连接可能发生异常 |
| clickhouse_query_total | ch 已处理的 query 总数 | rate(clickhouse_query_total[1m]) > 30 | 单实例 qps 超过 30 则报警 |
| clickhouse_query | ch 中正在运行的 query 个数 | clickhouse_query > 30 | 单实例并发 query 数超过阈值则报警 |
| clickhouse_tcp_connection | ch 的 TCP 连接数 | clickhouse_tcp_connection > XXX | 略 |
| clickhouse_http_connection | ch 的 HTTP 连接数 | clickhouse_http_connection > XXX | 略 |
| clickhouse_zoo_keeper_request | ch 中正在运行的 zk 请求数 | clickhouse_zoo_keeper_request > XXX | 略 |
| clickhouse_replicas_max_queue_size | ch 中 zk 副本同步队列的长度 | clickhouse_replicas_max_queue_size > 100 | zk 副本同步队列长度超过阈值则报警,说明此时副本同步队列出现堆积 |
2.3 其他常用 SQL
在 clickhouse 中,所有被执行的 Query 都会记录到system.query_log表中。因此我们可通过该表监控集群的查询情况。以下列举几种用于监控的常用 SQL 。为了更方便的查看,可添加到 grafana 看板中。
最近查询
SELECT event_time, user, query_id AS query, read_rows, read_bytes, result_rows, result_bytes, memory_usage, exception FROM clusterAllReplicas('cluster_name', system, query_log) WHERE (event_date = today()) AND (event_time >= (now() - 60)) AND (is_initial_query = 1) AND (query NOT LIKE 'INSERT INTO%') ORDER BY event_time DESC LIMIT 100 慢查询
SELECT event_time, user, query_id AS query, read_rows, read_bytes, result_rows, result_bytes, memory_usage, exception FROM clusterAllReplicas('cluster_name', system, query_log) WHERE (event_date = yesterday()) AND query_duration_ms > 30000 AND (is_initial_query = 1) AND (query NOT LIKE 'INSERT INTO%') ORDER BY query_duration_ms desc LIMIT 100 Top10 大表
SELECT database, table, sum(bytes_on_disk) AS bytes_on_disk FROM clusterAllReplicas('cluster_name', system, parts) WHERE active AND (database != 'system') GROUP BY database, table ORDER BY bytes_on_disk DESC LIMIT 10 Top10 查询用户
SELECT user, count(1) AS query_times, sum(read_bytes) AS query_bytes, sum(read_rows) AS query_rows FROM clusterAllReplicas('cluster_name', system, query_log) WHERE (event_date = yesterday()) AND (is_initial_query = 1) AND (query NOT LIKE 'INSERT INTO%') GROUP BY user ORDER BY query_times DESC LIMIT 10 ]]>更多精彩内容,请扫码关注微信公众号:后端技术小屋。如果觉得文章对你有帮助的话,请多多分享、转发、在看。
1. 什么是 Talend
Talend Open Studio 是 Talend (拓蓝)公司开发的一个数据集成的数据 ETL 软件,可以简化数据处理流程,降低入门门槛,不需要掌握专业的 ETL 知识,仅仅通过 web 界面和简单的组件拖拽就可实现数据处理。可以协助企业利用更多数据,不断提高其数据的可用性、可靠性以及有用性。BI 工具 Talend Open Studio 功能强大,可以同步多种数据库,可以清洗、筛选、java 代码处理数据、数据导入导出,内联查询多种数据库,以下简称 talend 。
概况来说,talend 特点主要有以下几点:
数据源:各种常用数据库( mysql oracle hive ),文件等。
-
速度:需要手工调整,对特定数据源有优化。
-
部署:创建 java 或 perl 文件,并通过操作系统调度工具来运行。
-
易用性:有 GUI 图形界面但是以 Eclipse 的插件方式提供。
等在使用 talend 的朋友说说看。
]]>主要是上传 API 接口,有 bucket, 上传个图片,给出个公开 http 地址, 如果有权限认证就更好了。
感觉 nginx 应该也是可以做这样的事情, 但是要考虑到磁盘可能会爆掉, 但如果一开始就申请很大的磁盘,又很浪费。 (听别人说,要用 HDFS 这类的东西。)
大家有什么可以推荐的? (一定要支持 Docker 部署)
]]>但是由于以后可能量比较大,不想着存数据库( MySQL )。
现在一般是怎么好做法?
比如,现在想到的比较笨的方法:
系统会有频繁跟踪数据传过来, 那么我就在 DB 里 [跟踪日志表] 里新建一条记录。
然后定时每 10 分钟汇总一些。记录在 [分小时统计表] 里。 然后再定时从 [分小时统计表] 算出总量,存放 [总量表] 的。
现在是 3 张表。
A - 跟踪记录表 B - 分小时统计表 C - 每个广告的统计总量表 感觉这种方法不好, A 表应该算是非主业务的,不应该与业务表们放在一起。 A 表也会越来越庞大。(大表做统计的话,可能会把 MySQL 搞崩溃掉) 其余两个表是由于 A 来算出来的。
应该会有更好的解决方法,求教
]]>分布式技术的发展,深刻地改变了我们编程的模式和思考软件的模式。值 2019 岁末,PingCAP 联合 InfoQ 共同策划出品“分布式系统前沿技术 ”专题, 邀请众多技术团队共同参与,一起探索这个古老领域的新生机。本文出自微众银行大数据平台负责人邸帅。
在当前的复杂分布式架构环境下,服务治理已经大行其道。但目光往下一层,从上层 APP、Service,到底层计算引擎这一层面,却还是各个引擎各自为政,Client-Server 模式紧耦合满天飞的情况。如何做好“计算治理”,让复杂环境下各种类型的大量计算任务,都能更简洁、灵活、有序、可控的提交执行,和保障成功返回结果?计算中间件 Linkis 就是上述问题的最佳实践。
复杂分布式架构环境下的计算治理有什么问题?
什么是复杂分布式架构环境?
分布式架构,指的是系统的组件分布在通过网络相连的不同计算机上,组件之间通过网络传递消息进行通信和协调,协同完成某一目标。一般来说有水平(集群化)和垂直(功能模块切分)两个拆分方向,以解决高内聚低耦合、高并发、高可用等方面问题。
多个分布式架构的系统,组成分布式系统群,就形成了一个相对复杂的分布式架构环境。通常包含多种上层应用服务,多种底层基础计算存储引擎。如下图 1 所示:
什么是计算治理?
就像《微服务设计》一书中提到的,如同城市规划师在面对一座庞大、复杂且不断变化的城市时,所需要做的规划、设计和治理一样,庞大复杂的软件系统环境中的各种区域、元素、角色和关系,也需要整治和管理,以使其以一种更简洁、优雅、有序、可控的方式协同运作,而不是变成一团乱麻。
在当前的复杂分布式架构环境下,大量 APP、Service 间的通信、协调和管理,已经有了从 SOA ( Service-Oriented Architecture )到微服务的成熟理念,及从 ESB 到 Service Mesh 的众多实践,来实现其从服务注册发现、配置管理、网关路由,到流控熔断、日志监控等一系列完整的服务治理功能。服务治理框架的“中间件”层设计,可以很好的实现服务间的解耦、异构屏蔽和互操作,并提供路由、流控、状态管理、监控等治理特性的共性提炼和复用,增强整个架构的灵活性、管控能力、可扩展性和可维护性。
但目光往下一层,你会发现在从 APP、Service,到后台引擎这一层面,却还是各个引擎各自为政,Client-Server 模式紧耦合满天飞的情况。在大量的上层应用,和大量的底层引擎之间,缺乏一层通用的“中间件”框架设计。类似下图 2 的网状。
计算治理,关注的正是上层应用和底层计算(存储)引擎之间,从 Client 到 Server 的连接层范围,所存在的紧耦合、灵活性和管控能力欠缺、缺乏复用能力、可扩展性、可维护性差等问题。要让复杂分布式架构环境下各种类型的计算任务,都能更简洁、灵活、有序、可控的提交执行,和成功返回结果。如下图 3 所示:
计算治理问题描述
更详细的来看计算治理的问题,可以分为如下治( architecture,架构层面)和理( insight,细化特性)两个层面。
计算治理之治( architecture )-架构层面问题
紧耦合问题,上层应用和底层计算存储引擎间的 CS 连接模式。
所有 APP & Service 和底层计算存储引擎,都是通过 Client-Server 模式相连,处于紧耦合状态。以 Analytics Engine 的 Spark 为例,如下图 4:
这种状态会带来如下问题:
-
引擎 client 的任何改动(如版本升级),将直接影响每一个嵌入了该 client 的上层应用;当应用系统数量众多、规模庞大时,一次改动的成本会很高。
-
直连模式,导致上层应用缺乏,对跨底层计算存储引擎实例级别的,路由选择、负载均衡等能力;或者说依赖于特定底层引擎提供的特定连接方式实现,有的引擎有一些,有的没有。
-
随着时间推移,不断有新的上层应用和新的底层引擎加入进来,整体架构和调用关系将愈发复杂,可扩展性、可靠性和可维护性降低。
重复造轮子问题,每个上层应用工具系统都要重复解决计算治理问题。
每个上层应用都要重复的去集成各种 client,创建和管理 client 到引擎的连接及其状态,包括底层引擎元数据的获取与管理。在并发使用的用户逐渐变多、并发计算任务量逐渐变大时,每个上层应用还要重复的去解决多个用户间在 client 端的资源争用、权限隔离,计算任务的超时管理、失败重试等等计算治理问题。
想象你有 10 个并发任务数过百的上层应用,不管是基于 Web 的 IDE 开发环境、可视化 BI 系统,还是报表系统、工作流调度系统等,每个接入 3 个底层计算引擎。上述的计算治理问题,你可能得逐一重复的去解决 10*3=30 遍,而这正是当前在各个公司不断发生的现实情况,其造成的人力浪费不可小觑。
扩展难问题,上层应用新增对接底层计算引擎,维护成本高,改动大。
在 CS 的紧耦合模式下,上层应用每新增对接一个底层计算引擎,都需要有较大改动。
以对接 Spark 为例,在上层应用系统中的每一台需要提交 Spark 作业的机器,都需要部署和维护好 Java 和 Scala 运行时环境和变量,下载和部署 Spark Client 包,且配置并维护 Spark 相关的环境变量。如果要使用 Spark on YARN 模式,那么你还需要在每一台需要提交 Spark 作业的机器上,去部署和维护 Hadoop 相关的 jar 包和环境变量。再如果你的 Hadoop 集群需要启用 Kerberos 的,那么很不幸,你还需要在上述的每台机器去维护和调试 keytab、principal 等一堆 Kerberos 相关配置。
这还仅仅是对接 Spark 一个底层引擎。随着上层应用系统和底层引擎的数量增多,需要维护的关系会是个笛卡尔积式的增长,光 Client 和配置的部署维护,就会成为一件很令人头疼的事情。
应用孤岛问题,跨不同应用工具、不同计算任务间的互通问题。
多个相互有关联的上层应用,向后台引擎提交执行的不同计算任务之间,往往是有所关联和共性的,比如需要共享一些用户定义的运行时环境变量、函数、程序包、数据文件等。当前情况往往是一个个应用系统就像一座座孤岛,相关信息和资源无法直接共享,需要手动在不同应用系统里重复定义和维护。
典型例子是在数据批处理程序开发过程中,用户在数据探索开发 IDE 系统中定义的一系列变量、函数,到了数据可视化系统里往往又要重新定义一遍; IDE 系统运行生成的数据文件位置和名称,不能直接方便的传递给可视化系统;依赖的程序包也需要从 IDE 系统下载、重新上传到可视化系统;到了工作流调度系统,这个过程还要再重复一遍。不同上层应用间,计算任务的运行依赖缺乏互通、复用能力。
计算治理之理( insight )- 细化特性问题
除了上述的架构层面问题,要想让复杂分布式架构环境下,各种类型的计算任务,都能更简洁、灵活、有序、可控的提交执行,和成功返回结果,计算治理还需关注高并发,高可用,多租户隔离,资源管控,安全增强,计算策略等等细化特性问题。这些问题都比较直白易懂,这里就不一一展开论述了。
基于计算中间件 Linkis 的计算治理 - 治之路( Architecture )
Linkis 架构设计介绍
核心功能模块与流程
计算中间件 Linkis,是微众银行专门设计用来解决上述紧耦合、重复造轮子、扩展难、应用孤岛等计算治理问题的。当前主要解决的是复杂分布式架构的典型场景-数据平台环境下的计算治理问题。
Linkis 作为计算中间件,在上层应用和底层引擎之间,构建了一层中间层。能够帮助上层应用,通过其对外提供的标准化接口(如 HTTP, JDBC, Java …),快速的连接到多种底层计算存储引擎(如 Spark、Hive、TiSpark、MySQL、Python 等),提交执行各种类型的计算任务,并实现跨上层应用间的计算任务运行时上下文和依赖的互通和共享。且通过提供多租户、高并发、任务分发和管理策略、资源管控等特性支持,使得各种计算任务更灵活、可靠、可控的提交执行,成功返回结果,大大降低了上层应用在计算治理层的开发和运维成本、与整个环境的架构复杂度,填补了通用计算治理软件的空白。(图 8、9 )
要更详细的了解计算任务通过 Linkis 的提交执行过程,我们先来看看 Linkis 核心的“计算治理服务”部分的内部架构和流程。如下图 10:
计算治理服务:计算中间件的核心计算框架,主要负责作业调度和生命周期管理、计算资源管理,以及引擎连接器的生命周期管理。
公共增强服务:通用公共服务,提供基础公共功能,可服务于 Linkis 各种服务及上层应用系统。
其中计算治理服务的主要模块如下:
-
入口服务 Entrance,负责接收作业请求,转发作业请求给对应的 Engine,并实现异步队列、高并发、高可用、多租户隔离。
-
应用管理服务 AppManager,负责管理所有的 EngineConnManager 和 EngineConn,并提供 EngineConnManager 级和 EngineConn 级标签能力;加载新引擎插件,向 RM 申请资源, 要求 EM 根据资源创建 EngineConn ;基于标签功能,为作业分配可用 EngineConn。
-
资源管理服务 ResourceManager,接收资源申请,分配资源,提供系统级、用户级资源管控能力,并为 EngineConnManager 级和 EngineConn 提供负载管控。
-
引擎连接器管理服务 EngineConn Manager,负责启动 EngineConn,管理 EngineConn 的生命周期,并定时向 RM 上报资源和负载情况。
-
引擎连接器 EngineConn,负责与底层引擎交互,解析和转换用户作业,提交计算任务给底层引擎,并实时监听底层引擎执行情况,回推相关日志、进度和状态给 Entrance。
如图 10 所示,一个作业的提交执行主要分为以下 11 步:
1. 上层应用向计算中间件提交作业,微服务网关 SpringCloud Gateway 接收作业并转发给 Entrance。
2. Entrance 消费作业,为作业向 AppManager 申请可用 EngineConn。
3. 如果不存在可复用的 Engine,AppManager 尝试向 ResourceManager 申请资源,为作业启动一个新 EngineConn。
- 申请到资源,要求 EngineConnManager 依照资源启动新 EngineConn
5. EngineConnManager 启动新 EngineConn,并主动回推新 EngineConn 信息。
6. AppManager 将新 EngineConn 分配给 Entrance,Entrance 将 EngineConn 分配给用户作业,作业开始执行,将计算任务提交给 EngineConn。
7. EngineConn 将计算任务提交给底层计算引擎。
8. EngineConn 实时监听底层引擎执行情况,回推相关日志、进度和状态给 Entrance,Entrance 通过 WebSocket,主动回推 EngineConn 传过来的日志、进度和状态给上层应用系统。
9. EngineConn 执行完成后,回推计算任务的状态和结果集信息,Entrance 将作业和结果集信息更新到 JobHistory,并通知上层应用系统。
10. 上层应用系统访问 JobHistory,拿到作业和结果集信息。
11. 上层应用系统访问 Storage,请求作业结果集。
计算任务管理策略支持
在复杂分布式环境下,一个计算任务往往不单会是简单的提交执行和返回结果,还可能需要面对提交失败、执行失败、hang 住等问题,且在大量并发场景下还需通过计算任务的调度分发,解决租户间互相影响、负载均衡等问题。
Linkis 通过对计算任务的标签化,实现了在任务调度、分发、路由等方面计算任务管理策略的支持,并可按需配置超时、自动重试,及灰度、多活等策略支持。如下图 11。
基于 Spring Cloud 微服务框架
说完了业务架构,我们现在来聊聊技术架构。在计算治理层环境下,很多类型的计算任务具有生命周期较短的特征,如一个 Spark job 可能几十秒到几分钟就执行完,EngineConn ( EnginConnector )会是大量动态启停的状态。前端用户和 Linkis 中其他管理角色的服务,需要能够及时动态发现相关服务实例的状态变化,并获取最新的服务实例访问地址信息。同时需要考虑,各模块间的通信、路由、协调,及各模块的横向扩展、负载均衡、高可用等能力。
基于以上需求,Linkis 实际是基于 Spring Cloud 微服务框架技术,将上述的每一个模块 /角色,都封装成了一个微服务,构建了多个微服务组,整合形成了 Linkis 的完整计算中间件能力。如下图 12:
从多租户管理角度,上述服务可区分为租户相关服务,和租户无关服务两种类型。租户相关服务,是指一些任务逻辑处理负荷重、资源消耗高,或需要根据具体租户、用户、物理机器等,做隔离划分、避免相互影响的服务,如 Entrance、EnginConn ( EnginConnector ) Manager、EnginConn ;其他如 App Manger、Resource Manager、Context Service 等服务,都是租户无关的。
Eureka 承担了微服务动态注册与发现中心,及所有租户无关服务的负载均衡、故障转移功能。
Eureka 有个局限,就是在其客户端,对后端微服务实例的发现与状态刷新机制,是客户端主动轮询刷新,最快可设 1 秒 1 次(实际要几秒才能完成刷新)。这样在 Linkis 这种需要快速刷新大量后端 EnginConn 等服务的状态的场景下,时效得不到满足,且定时轮询刷新对 Eureka server、对后端微服务实例的成本都很高。
为此我们对 Spring Cloud Ribbon 做了改造,在其中封装了 Eureka client 的微服务实例状态刷新方法,并把它做成满足条件主动请求刷新,而不会再频繁的定期轮询。从而在满足时效的同时,大大降低了状态获取的成本。如下图 13:
Spring Cloud Gateway 承担了外部请求 Linkis 的入口网关的角色,帮助在服务实例不断发生变化的情况下,简化前端用户的调用逻辑,快速方便的获取最新的服务实例访问地址信息。
Spring Cloud Gateway 有个局限,就是一个 WebSocket 客户端只能将请求转发给一个特定的后台服务,无法完成一个 WebSocket 客户端通过网关 API 对接后台多个 WebSocket 微服务,而这在我们的 Entrance HA 等场景需要用到。
为此 Linkis 对 Spring Cloud Gateway 做了相应改造,在 Gateway 中实现了 WebSocket 路由转发器,用于与客户端建立 WebSocket 连接。建立连接成功后,会自动分析客户端的 WebSocket 请求,通过规则判断出请求该转发给哪个后端微服务,然后将 WebSocket 请求转发给对应的后端微服务实例。详见 Github 上 Linkis 的 Wiki 中,“Gateway 的多 WebSocket 请求转发实现”一文。
**Spring Cloud OpenFeign ** 提供的 HTTP 请求调用接口化、解析模板化能力,帮助 Linkis 构建了底层 RPC 通信框架。但基于 Feign 的微服务之间 HTTP 接口的调用,只能满足简单的 A 微服务实例根据简单的规则随机选择 B 微服务之中的某个服务实例,而这个 B 微服务实例如果想异步回传信息给调用方,是无法实现的。同时,由于 Feign 只支持简单的服务选取规则,无法做到将请求转发给指定的微服务实例,无法做到将一个请求广播给接收方微服务的所有实例。Linkis 基于 Feign 实现了一套自己的底层 RPC 通信方案,集成到了所有 Linkis 的微服务之中。一个微服务既可以作为请求调用方,也可以作为请求接收方。作为请求调用方时,将通过 Sender 请求目标接收方微服务的 Receiver ;作为请求接收方时,将提供 Receiver 用来处理请求接收方 Sender 发送过来的请求,以便完成同步响应或异步响应。如下图示意。详见 GitHub 上 Linkis 的 Wiki 中,“Linkis RPC 架构介绍”一文。
至此,Linkis 对上层应用和底层引擎的解耦原理,其核心架构与流程设计,及基于 Spring Cloud 微服务框架实现的,各模块微服务化动态管理、通信路由、横向扩展能力介绍完毕。
解耦:Linkis 如何解耦上层应用和底层引擎
Linkis 作为计算中间件,在上层应用和底层引擎之间,构建了一层中间层。上层应用所有计算任务,先通过 HTTP、WebSocket、Java 等接口方式提交给 Linkis,再由 Linkis 转交给底层引擎。原有的上层应用以 CS 模式直连底层引擎的紧耦合得以解除,因此实现了解耦。如下图 16 所示:
通过解耦,底层引擎的变动有了 Linkis 这层中间件缓冲,如引擎 client 的版本升级,无需再对每一个对接的上层应用做逐个改动,可在 Linkis 层统一完成。并能在 Linkis 层,实现对上层应用更加透明和友好的升级策略,如灰度切换、多活等策略支持。且即使后继接入更多上层应用和底层引擎,整个环境复杂度也不会有大的变化,大大降低了开发运维工作负担。
复用:对于上层应用,Linkis 如何凝练计算治理模块供复用,避免重复开发
上层应用复用 Linkis 示例( Scriptis )
有了 Linkis,上层应用可以基于 Linkis,快速实现对多种后台计算存储引擎的对接支持,及变量、函数等自定义与管理、资源管控、多租户、智能诊断等计算治理特性。
优点
以微众银行与 Linkis 同时开源的,交互式数据开发探索工具 Scriptis 为例,Scriptis 的开发人员只需关注 Web UI、多种数据开发语言支持、脚本编辑功能等纯前端功能实现,Linkis 包办了其从存储读写、计算任务提交执行、作业状态日志更新、资源管控等等几乎所有后台功能。基于 Linkis 的大量计算治理层能力的复用,大大降低了 Scriptis 项目的开发成本,使得 Scritpis 目前只需要有限的前端人员,即可完成维护和版本迭代工作。
如下图 17,Scriptis 项目 99.5% 的代码,都是前端的 JS、CSS 代码。后台基本完全复用 Linkis。
快速扩展:对于底层引擎,Linkis 如何以很小的开发量,实现新底层引擎快速对接
模块化可插拔的计算引擎接入设计,新引擎接入简单快速。
对于典型交互式模式计算引擎(提交任务,执行,返回结果),用户只需要 buildApplication 和 executeLine 这 2 个方法,就可以完成一个新的计算引擎接入 Linkis,代码量极少。示例如下。
(1) AppManager 部分:用户必须实现的接口是 ApplicationBuilder,用来封装新引擎连接器实例启动命令。
1. //用户必须实现的方法: 用于封装新引擎连接器实例启动命令 2. def buildApplication(protocol:Protocol):ApplicationRequest (2) EngineConn 部分:用户只需实现 executeLine 方法,向新引擎提交执行计算任务:
1. //用户必须实现的方法:用于调用底层引擎提交执行计算任务 2. def executeLine(context: EngineConnContext,code: String): ExecuteResponse 引擎相关其他功能 /方法都已有默认实现,无定制化需求可直接复用。
连通:Linkis 如何打通应用孤岛
通过 Linkis 提供的上下文服务,和存储、物料库服务,接入的多个上层应用之间,可轻松实现环境变量、函数、程序包、数据文件等,相关信息和资源的共享和复用,打通应用孤岛。
Context Service 上下文服务介绍
Context Service ( CS )为不同上层应用系统,不同计算任务,提供了统一的上下文管理服务,可实现上下文的自定义和共享。在 Linkis 中,CS 需要管理的上下文内容,可分为元数据上下文、数据上下文和资源上下文 3 部分。
元数据上下文,定义了计算任务中底层引擎元数据的访问和使用规范,主要功能如下:
-
提供用户的所有元数据信息读写接口(包括 Hive 表元数据、线上库表元数据、其他 NoSQL 如 HBase、Kafka 等元数据)。
-
计算任务内所需元数据的注册、缓存和管理。
-
数据上下文,定义了计算任务中数据文件的访问和使用规范。管理数据文件的元数据。
-
运行时上下文,管理各种用户自定义的变量、函数、代码段、程序包等。
-
同时 Linkis 也提供了统一的物料管理和存储服务,上层应用可根据需要对接,从而可实现脚本文件、程序包、数据文件等存储层的打通。
基于计算中间件 Linkis 的计算治理 - 理之路( Insight )
Linkis 计算治理细化特性设计与实现介绍,在高并发、高可用、多租户隔离、资源管控、计算任务管理策略等方面,做了大量细化考量和实现,保障计算任务在复杂条件下成功执行。
计算任务的高并发支持
Linkis 的 Job 基于多级异步设计模式,服务间通过高效的 RPC 和消息队列模式进行快速通信,并可以通过给 Job 打上创建者、用户等多种类型的标签进行任务的转发和隔离来提高 Job 的并发能力。通过 Linkis 可以做到 1 个入口服务( Entrance )同时承接超 1 万+ 在线的 Job 请求。
多级异步的设计架构图如下:
如上图所示 Job 从 GateWay 到 Entrance 后,Job 从生成到执行,到信息推送经历了多个线程池,每个环节都通过异步的设计模式,每一个线程池中的线程都采用运行一次即结束的方式,降低线程开销。整个 Job 从请求—执行—到信息推送全都异步完成,显著的提高了 Job 的并发能力。
这里针对计算任务最关键的一环 Job 调度层进行说明,海量用户成千上万的并发任务的压力,在 Job 调度层中是如何进行实现的呢?
在请求接收层,请求接收队列中,会缓存前端用户提交过来的成千上万计算任务,并按系统 /用户层级划分的调度组,分发到下游 Job 调度池中的各个调度队列;到 Job 调度层,多个调度组对应的调度器,会同时消费对应的调度队列,获取 Job 并提交给 Job 执行池进行执行。过程中大量使用了多线程、多级异步调度执行等技术。示意如下图 21:
其他细化特性
Linkis 还在高可用、多租户隔离、资源管控、计算任务管理策略等方面,做了很多细化考量和实现。篇幅有限,在这里不再详述每个细化特性的实现,可参见 Github 上 Linkis 的 Wiki。后继我们会针对 Linkis 的计算治理-理之路( Insight )的细化特性相关内容,再做专题介绍。
结语
基于如上解耦、复用、快速扩展、连通等架构设计优点,及高并发、高可用、多租户隔离、资源管控等细化特性实现,计算中间件 Linkis 在微众生产环境的应用效果显著。极大的助力了微众银行一站式大数据平台套件 WeDataSphere 的快速构建,且构成了 WeDataSphere 全连通、多租户、资源管控等企业级特性的基石。
Linkis 在微众应用情况如图 22:
我们已将 Linkis 开源,Github repo 地址:https://github.com/WeBankFinTech/Linkis。
欢迎对类似计算治理问题感兴趣的同学,参与到计算中间件 Linkis 的社区协作中,共同把 Linkis 建设得更加完善和易用。
作者介绍:邸帅,微众银行大数据平台负责人,主导微众银行 WeDataSphere 大数据平台套件的建设运营与开源,具备丰富的大数据平台开发建设实践经验。
本文是「分布式系统前沿技术」专题文章,目前该专题在持续更新中,欢迎大家保持关注👇
