
目前用国产的 trae 和 G 家的 antigravity 。感觉还是不太如意。目前 antigravity 强一点点。
大家有推荐的吗?还有就是非要选择一家氪金的话。哪一家好点。 ]]>
- 同一栋写字楼里,一边在聊 风格库 / LoRA / 纳米香蕉 / 一致性 / 成本,目标是:把一个人的产能扩成小工作室,越聊越贵。
- 另一边品牌部凌晨 2 点改 KV:字号更大、人物更亮、Logo 更右、留白更空,改到第 23 版。
- 第二天还被指着屏幕问:“这个是不是也能用 AI 做?”

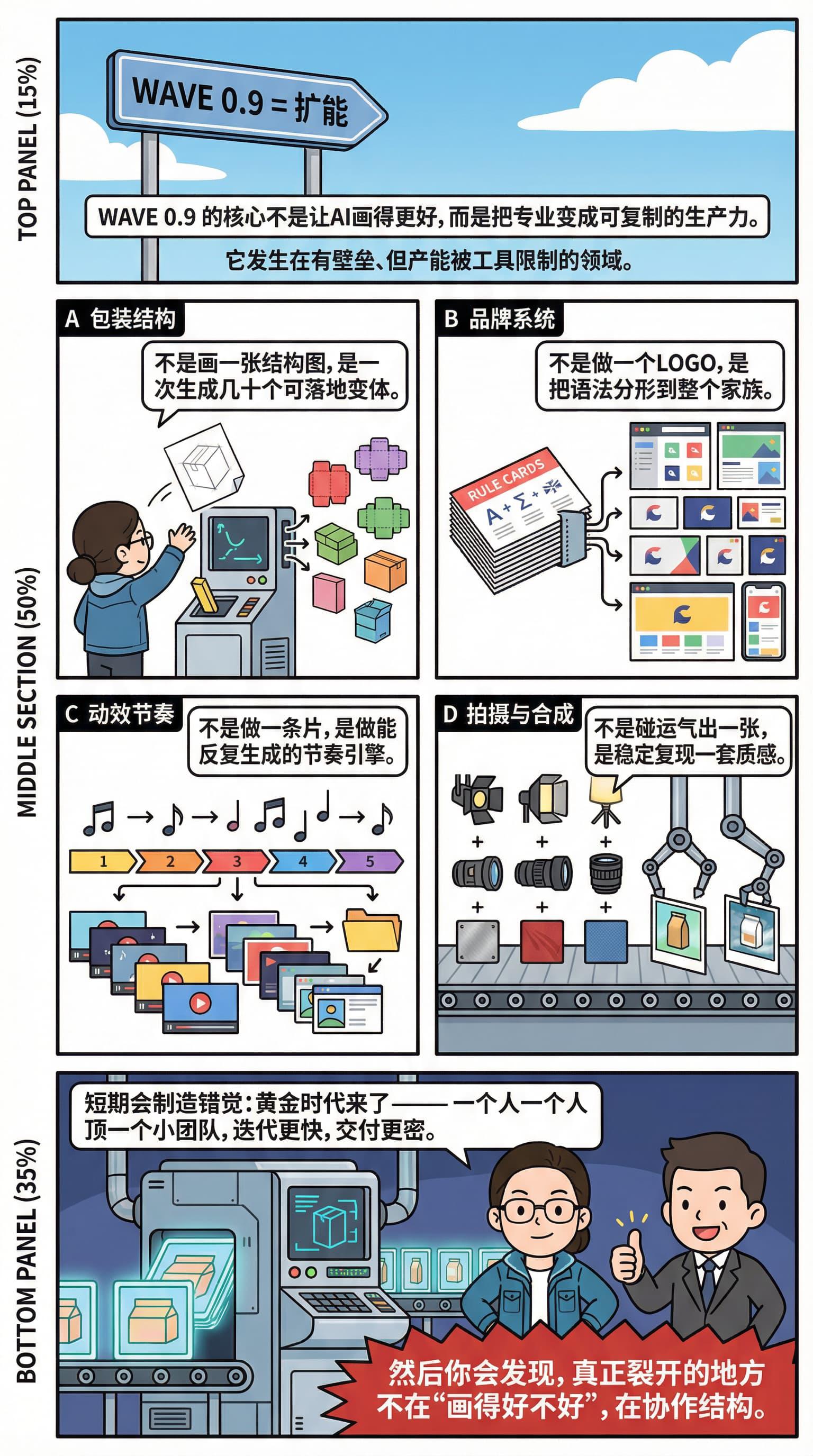
- WAVE 0.9 不是替代,是扩能:把专业变成可复制的产能。
- 包装结构 → 批量变体;品牌系统 → 母品牌语法分形;动效/拍摄 → 模板化流水线。
- 关键不是“AI 画更好”,而是:我把会的专业,变成可复制的生产力。
- 短期看像黄金时代:一个人顶小团队;但真正裂开的是——协作结构。
- 最先出问题的不是“低端审美”,而是那些曾经最稳的岗位:品牌视觉 / 包装 / 活动主视觉 / 运营图 / 一部分 UI。
- 因为它们最适合被稳定执行:固定版式、可复制气质、可枚举风格、无限灵感。
- 它们就是被替换的 Wave 1。
- 但在 Wave 1 之前,还有一波更隐蔽的:WAVE 0.9。
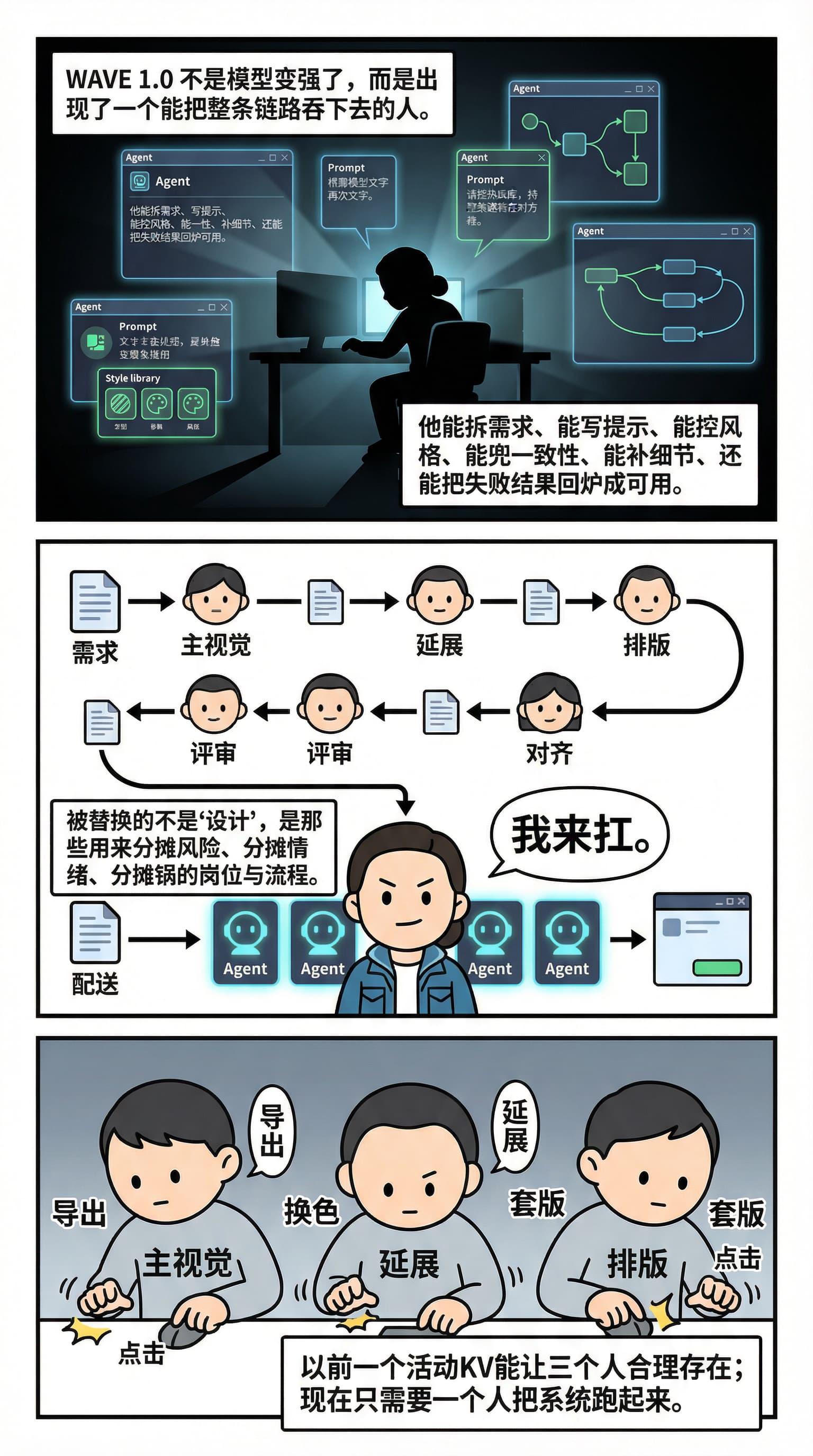
WAVE 1.0:有一个囊括一切的卷王
- 不是模型变强,而是出现一个人:能拆需求、控风格、兜一致性、把失败回炉成可交付,还愿意扛脏活。
- 产出链路被压成:一个人 + 一堆 Agent + 一个交付窗口。
- 被替换的不是“设计”,是那些用来 分摊风险/情绪/责任 的岗位与流程。
- 组织直觉会一致:能少招就少招,能压价就压价。

- 当你的工作能被 生成链路 + Agent + 总控 整体接管时,你的剩余价值会在那一刻被榨干。
- 不是“失业后再找一份”,而是:市场不再需要你。
- 你以为你在卖“创意”,其实一直在卖 协作成本;协作被绕开,你就只剩下那句:“这也能不能用 AI 做?”
- 只要分配 / 激励模式不改变,一切都是枉然。
P.S. 原创的第一版 · 交换一个友链接,以后讨论未来。哈哈。Zeitgeist
]]>- 检索能力受限 在大仓上,检索的关键词容易遗漏关键路径,把不相干的内容加入时会占用上下文窗口,后续模型会遗漏一些文件;
- 缺少代码结构 检索是 AI 自己给的关键词进行,缺乏真实代码的语义和代码调用、依赖关系等
因此,我们实现了一个 CKG 方案,解析了文件结构之后,分析出依赖、调用关系之后生成代码摘要,然后向量存储,最后提供 MCP 给 Agent 做大仓代码检索。
但理想是好的,现实使用时遇到了问题:
- 查询的错配 当使用自然语言提问时(如:我的头像双击逻辑),Agent 在调用 CKG MCP 时给到工具的 query 关键词可能是 "avatar double click"、"user icon interaction" 等,会丢了我的,这样检索出来的结果会不理想,再重排序意义也不大,因为召回的内容不匹配,本质还是关键词由 LLM 生成的,有一定的不可靠;
关于这个大家有什么好的想法?
]]>文中的核心卖点是:30B 参数规模的模型跑出了 1T 参数的性能。里面提到了一些刷榜数据:
-
HLE-Text: 39.2%
-
BrowseComp: 69.8%
-
GAIA-Val-165: 80.8%
说实话,看文章描述感觉挺玄学的,又是“交互内化进推理”,又是“用确定性对抗不确定性”。
作为一个普通开发者,我想请教下站里的大佬:
1.现在 30B 真的能通过架构优化或者推理侧的改进,跨两个量级去打 1T 的模型吗?
2.文中提到的这些测试集(比如那个 HLE 人类终极测试)含金量如何?
3.这种“做题家模式 vs 科学家模式”的提法,在实际落地场景中意义大吗?
想听听大家的真实看法。我试了他们的官网产品 dr.miromind.ai ,除了速度比较慢,好像质量还挺高。
]]>1.各类大模型、AIGC 工具的使用体验
2.AI 在工作、学习、创作中的实际应用
3.提示词、自动化、踩坑记录、效果对比
4.对 AI 行业、产品、趋势的个人看法
不追求高深理论,更欢迎真实体验、实践总结和日常问题。只要和 AI 有关,都可以发在这里。
AI 不是万能的神,而是“能力照妖镜”。26 年必然是 AI 大爆发的元年,如果不主动拥抱 AI ,主动学习,主动使用,那 26 年很有可能就会是职场危机的一年。 ]]>